 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion of Skeleton Dynamics and Clinical Gait Features for Video-Based Cerebral Palsy Severity Assessment
Mar 23, 2026Video-based gait analysis has become a promising approach for assessing motor impairment in children with cerebral palsy (CP). However, existing methods usually rely on either pose sequences or handcrafted gait features alone, making it difficult to simultaneously capture spatiotemporal motion patterns and clinically meaningful biomechanical information. To address this gap, we propose a multimodal fusion framework that integrates skeleton dynamics with contribution-guided clinically meaningful gait features. First, Grad-CAM analysis on a pre-trained ST-GCN backbone identified the most discriminative body keypoints, providing an interpretable basis for subsequent gait feature extraction. We then build a dual-stream architecture, with one stream modeling skeleton dynamics using ST-GCN and the other encoding gait geatures derived from the identified keypoints. By fusing the two streams through feature cross-attention improved four-level CP motor severity classification to 70.86%, outperforming the baseline by 5.6 percentage points. Overall, this work suggests that integrating skeleton dynamics with clinically meaningful gait descriptors can improve both prediction performance and biomechanical interpretability for video-based CP severity assessment.
Abundant Intelligence and Deficient Demand: A Macro-Financial Stress Test of Rapid AI Adoption
Mar 10, 2026We formalize a macro-financial stress test for rapid AI adoption. Rather than a productivity bust or existential risk, we identify a distribution-and-contract mismatch: AI-generated abundance coexists with demand deficiency because economic institutions are anchored to human cognitive scarcity. Three mechanisms formalize this channel. First, a displacement spiral with competing reinstatement effects: each firm's rational decision to substitute AI for labor reduces aggregate labor income, which reduces aggregate demand, accelerating further AI adoption. We derive conditions on the AI capability growth rate, diffusion speed, and reinstatement rate under which the net feedback is self-limiting versus explosive. Second, Ghost GDP: when AI-generated output substitutes for labor-generated output, monetary velocity declines monotonically in the labor share absent compensating transfers, creating a wedge between measured output and consumption-relevant income. Third, intermediation collapse: AI agents that reduce information frictions compress intermediary margins toward pure logistics costs, triggering repricing across SaaS, payments, consulting, insurance, and financial advisory. Because top-quintile earners drive 47--65\% of U.S.\ consumption and face the highest AI exposure, the transmission into private credit (\$2.5 trillion globally) and mortgage markets (\$13 trillion) is disproportionate. We derive eleven testable predictions with explicit falsification conditions. Calibrated simulations disciplined by FRED time series and BLS occupation-level data quantify conditions under which stable adjustment transitions to explosive crisis.
VANGUARD: Vehicle-Anchored Ground Sample Distance Estimation for UAVs in GPS-Denied Environments
Mar 04, 2026Autonomous aerial robots operating in GPS-denied or communication-degraded environments frequently lose access to camera metadata and telemetry, leaving onboard perception systems unable to recover the absolute metric scale of the scene. As LLM/VLM-based planners are increasingly adopted as high-level agents for embodied systems, their ability to reason about physical dimensions becomes safety-critical -- yet our experiments show that five state-of-the-art VLMs suffer from spatial scale hallucinations, with median area estimation errors exceeding 50%. We propose VANGUARD, a lightweight, deterministic Geometric Perception Skill designed as a callable tool that any LLM-based agent can invoke to recover Ground Sample Distance (GSD) from ubiquitous environmental anchors: small vehicles detected via oriented bounding boxes, whose modal pixel length is robustly estimated through kernel density estimation and converted to GSD using a pre-calibrated reference length. The tool returns both a GSD estimate and a composite confidence score, enabling the calling agent to autonomously decide whether to trust the measurement or fall back to alternative strategies. On the DOTA~v1.5 benchmark, VANGUARD achieves 6.87% median GSD error on 306~images. Integrated with SAM-based segmentation for downstream area measurement, the pipeline yields 19.7% median error on a 100-entry benchmark -- with 2.6x lower category dependence and 4x fewer catastrophic failures than the best VLM baseline -- demonstrating that equipping agents with deterministic geometric tools is essential for safe autonomous spatial reasoning.
Machine Learning-Based Prediction of Speech Arrest During Direct Cortical Stimulation Mapping
Sep 10, 2025Identifying cortical regions critical for speech is essential for safe brain surgery in or near language areas. While Electrical Stimulation Mapping (ESM) remains the clinical gold standard, it is invasive and time-consuming. To address this, we analyzed intracranial electrocorticographic (ECoG) data from 16 participants performing speech tasks and developed machine learning models to directly predict if the brain region underneath each ECoG electrode is critical. Ground truth labels indicating speech arrest were derived independently from Electrical Stimulation Mapping (ESM) and used to train classification models. Our framework integrates neural activity signals, anatomical region labels, and functional connectivity features to capture both local activity and network-level dynamics. We found that models combining region and connectivity features matched the performance of the full feature set, and outperformed models using either type alone. To classify each electrode, trial-level predictions were aggregated using an MLP applied to histogram-encoded scores. Our best-performing model, a trial-level RBF-kernel Support Vector Machine together with MLP-based aggregation, achieved strong accuracy on held-out participants (ROC-AUC: 0.87, PR-AUC: 0.57). These findings highlight the value of combining spatial and network information with non-linear modeling to improve functional mapping in presurgical evaluation.
VoxelFormer: Parameter-Efficient Multi-Subject Visual Decoding from fMRI
Sep 10, 2025Recent advances in fMRI-based visual decoding have enabled compelling reconstructions of perceived images. However, most approaches rely on subject-specific training, limiting scalability and practical deployment. We introduce \textbf{VoxelFormer}, a lightweight transformer architecture that enables multi-subject training for visual decoding from fMRI. VoxelFormer integrates a Token Merging Transformer (ToMer) for efficient voxel compression and a query-driven Q-Former that produces fixed-size neural representations aligned with the CLIP image embedding space. Evaluated on the 7T Natural Scenes Dataset, VoxelFormer achieves competitive retrieval performance on subjects included during training with significantly fewer parameters than existing methods. These results highlight token merging and query-based transformers as promising strategies for parameter-efficient neural decoding.
Instruction Tuning and CoT Prompting for Contextual Medical QA with LLMs
Jun 13, 2025Large language models (LLMs) have shown great potential in medical question answering (MedQA), yet adapting them to biomedical reasoning remains challenging due to domain-specific complexity and limited supervision. In this work, we study how prompt design and lightweight fine-tuning affect the performance of open-source LLMs on PubMedQA, a benchmark for multiple-choice biomedical questions. We focus on two widely used prompting strategies - standard instruction prompts and Chain-of-Thought (CoT) prompts - and apply QLoRA for parameter-efficient instruction tuning. Across multiple model families and sizes, our experiments show that CoT prompting alone can improve reasoning in zero-shot settings, while instruction tuning significantly boosts accuracy. However, fine-tuning on CoT prompts does not universally enhance performance and may even degrade it for certain larger models. These findings suggest that reasoning-aware prompts are useful, but their benefits are model- and scale-dependent. Our study offers practical insights into combining prompt engineering with efficient finetuning for medical QA applications.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
Multi-head Reward Aggregation Guided by Entropy
Mar 26, 2025



Aligning large language models (LLMs) with safety guidelines typically involves reinforcement learning from human feedback (RLHF), relying on human-generated preference annotations. However, assigning consistent overall quality ratings is challenging, prompting recent research to shift towards detailed evaluations based on multiple specific safety criteria. This paper uncovers a consistent observation: safety rules characterized by high rating entropy are generally less reliable in identifying responses preferred by humans. Leveraging this finding, we introduce ENCORE, a straightforward entropy-guided approach that composes multi-head rewards by downweighting rules exhibiting high rating entropy. Theoretically, we demonstrate that rules with elevated entropy naturally receive minimal weighting in the Bradley-Terry optimization framework, justifying our entropy-based penalization. Through extensive experiments on RewardBench safety tasks, our method significantly surpasses several competitive baselines, including random weighting, uniform weighting, single-head Bradley-Terry models, and LLM-based judging methods. Our proposed approach is training-free, broadly applicable to various datasets, and maintains interpretability, offering a practical and effective solution for multi-attribute reward modeling.
R-LLaVA: Improving Med-VQA Understanding through Visual Region of Interest
Oct 27, 2024



Artificial intelligence has made significant strides in medical visual question answering (Med-VQA), yet prevalent studies often interpret images holistically, overlooking the visual regions of interest that may contain crucial information, potentially aligning with a doctor's prior knowledge that can be incorporated with minimal annotations (e.g., bounding boxes). To address this gap, this paper introduces R-LLaVA, designed to enhance biomedical VQA understanding by integrating simple medical annotations as prior knowledge directly into the image space through CLIP. These annotated visual regions of interest are then fed into the LLaVA model during training, aiming to enrich the model's understanding of biomedical queries. Experimental evaluation on four standard Med-VQA datasets demonstrates R-LLaVA's superiority over existing state-of-the-art (SoTA) methods. Additionally, to verify the model's capability in visual comprehension, a novel multiple-choice medical visual understanding dataset is introduced, confirming the positive impact of focusing on visual regions of interest in advancing biomedical VQA understanding.
Enhancing Exchange Rate Forecasting with Explainable Deep Learning Models
Oct 25, 2024
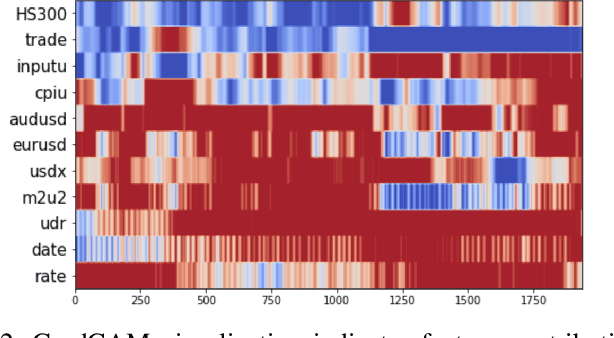

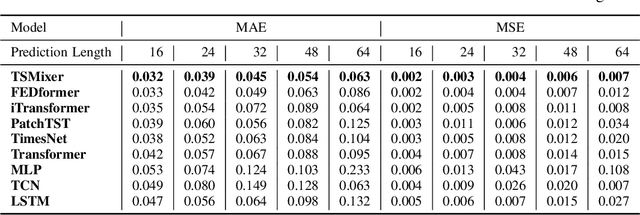
Accurate exchange rate prediction is fundamental to financial stability and international trade, positioning it as a critical focus in economic and financial research. Traditional forecasting models often falter when addressing the inherent complexities and non-linearities of exchange rate data. This study explores the application of advanced deep learning models, including LSTM, CNN, and transformer-based architectures, to enhance the predictive accuracy of the RMB/USD exchange rate. Utilizing 40 features across 6 categories, the analysis identifies TSMixer as the most effective model for this task. A rigorous feature selection process emphasizes the inclusion of key economic indicators, such as China-U.S. trade volumes and exchange rates of other major currencies like the euro-RMB and yen-dollar pairs. The integration of grad-CAM visualization techniques further enhances model interpretability, allowing for clearer identification of the most influential features and bolstering the credibility of the predictions. These findings underscore the pivotal role of fundamental economic data in exchange rate forecasting and highlight the substantial potential of machine learning models to deliver more accurate and reliable predictions, thereby serving as a valuable tool for financial analysis and decision-making.