 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentGym: A Testbed For Cross-Task Experiential Learning With Controllable Latent Structure
Jun 13, 2026We envision continually learning agentic systems that become more useful over time: as they encounter sequences of related tasks, they should infer the hidden structure shared across those tasks and use it to improve future decisions. This cross-task experiential learning capability is pivotal in domains such as personalization and interactive assistance, but existing training/evaluation frameworks do not provide shared, controllable latent structures and cannot measure whether or why agents improve. We introduce LatentGym: a controllable suite in which each environment is organized around a ground-truth latent variable governing the structure across tasks. Our construction yields metrics that separate exploration (whether the agent's actions gather information about the latent) from exploitation (whether the agent uses what it has gathered). We demonstrate our suite on empirical studies addressing three questions: how and why frontier models fail to adapt across related tasks; whether post-training on related task sequences improves general cross-task adaptation, and where those gains come from; and how design choices such as inter-task feedback shape training dynamics and generalization. Together, these results establish a controlled foundation for studying how LLM agents learn from experience across tasks, and for designing agents that adapt more reliably in sequential, personalized, and interactive settings.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Learning Image-Text Matching with Optimal Partial Transport
Mar 15, 2026Cross-modal matching, a fundamental task in bridging vision and language, has recently garnered substantial research interest. Despite the development of numerous methods aimed at quantifying the semantic relatedness between image-text pairs, these methods often fall short of achieving both outstanding performance and high efficiency. In this paper, we propose the crOss-Modal sInkhorn maTching (OMIT) network as an effective solution to effectively improving performance while maintaining efficiency. Rooted in the theoretical foundations of Optimal Transport, OMIT harnesses the capabilities of Cross-modal Mover's Distance to precisely compute the similarity between fine-grained visual and textual fragments, utilizing Sinkhorn iterations for efficient approximation. To further alleviate the issue of redundant alignments, we seamlessly integrate partial matching into OMIT, leveraging local-to-global similarities to eliminate the interference of irrelevant fragments. We conduct extensive evaluations of OMIT on two benchmark image-text retrieval datasets, namely Flickr30K and MS-COCO. The superior performance achieved by OMIT on both datasets unequivocally demonstrates its effectiveness in cross-modal matching. Furthermore, through comprehensive visualization analysis, we elucidate OMIT's inherent tendency towards focal matching, thereby shedding light on its efficacy. Our code is publicly available at https://github.com/ppanzx/OMIT.
Interactive World Simulator for Robot Policy Training and Evaluation
Mar 09, 2026Action-conditioned video prediction models (often referred to as world models) have shown strong potential for robotics applications, but existing approaches are often slow and struggle to capture physically consistent interactions over long horizons, limiting their usefulness for scalable robot policy training and evaluation. We present Interactive World Simulator, a framework for building interactive world models from a moderate-sized robot interaction dataset. Our approach leverages consistency models for both image decoding and latent-space dynamics prediction, enabling fast and stable simulation of physical interactions. In our experiments, the learned world models produce interaction-consistent pixel-level predictions and support stable long-horizon interactions for more than 10 minutes at 15 FPS on a single RTX 4090 GPU. Our framework enables scalable demonstration collection solely within the world models to train state-of-the-art imitation policies. Through extensive real-world evaluation across diverse tasks involving rigid objects, deformable objects, object piles, and their interactions, we find that policies trained on world-model-generated data perform comparably to those trained on the same amount of real-world data. Additionally, we evaluate policies both within the world models and in the real world across diverse tasks, and observe a strong correlation between simulated and real-world performance. Together, these results establish the Interactive World Simulator as a stable and physically consistent surrogate for scalable robotic data generation and faithful, reproducible policy evaluation.
LLM-Driven Completeness and Consistency Evaluation for Cultural Heritage Data Augmentation in Cross-Modal Retrieval
Nov 09, 2025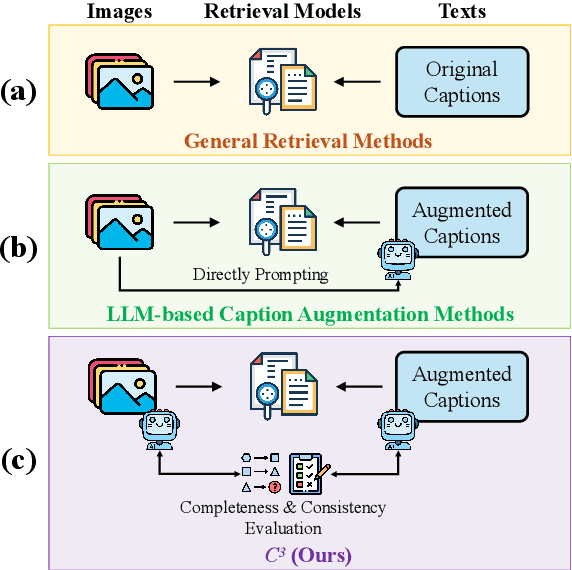
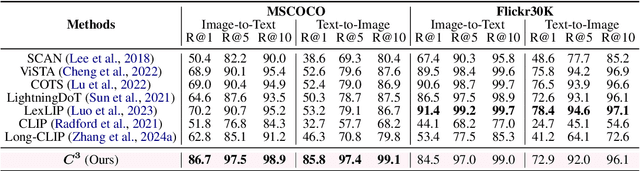
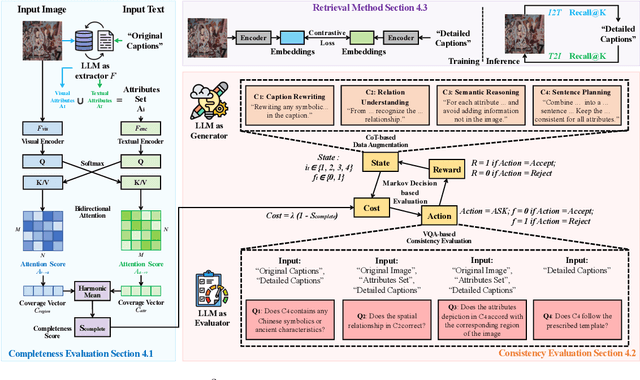
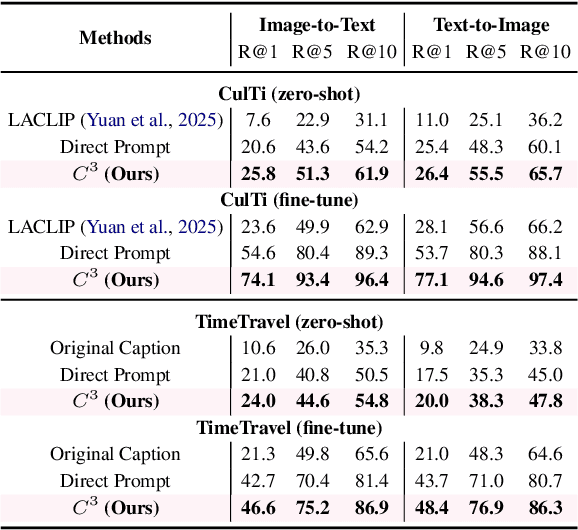
Cross-modal retrieval is essential for interpreting cultural heritage data, but its effectiveness is often limited by incomplete or inconsistent textual descriptions, caused by historical data loss and the high cost of expert annotation. While large language models (LLMs) offer a promising solution by enriching textual descriptions, their outputs frequently suffer from hallucinations or miss visually grounded details. To address these challenges, we propose $C^3$, a data augmentation framework that enhances cross-modal retrieval performance by improving the completeness and consistency of LLM-generated descriptions. $C^3$ introduces a completeness evaluation module to assess semantic coverage using both visual cues and language-model outputs. Furthermore, to mitigate factual inconsistencies, we formulate a Markov Decision Process to supervise Chain-of-Thought reasoning, guiding consistency evaluation through adaptive query control. Experiments on the cultural heritage datasets CulTi and TimeTravel, as well as on general benchmarks MSCOCO and Flickr30K, demonstrate that $C^3$ achieves state-of-the-art performance in both fine-tuned and zero-shot settings.
HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
May 29, 2025

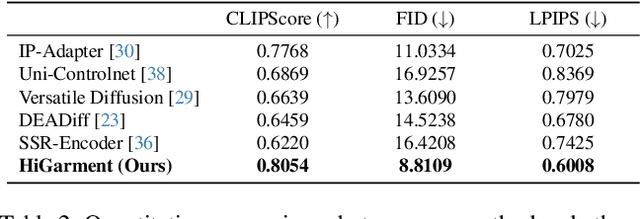

Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence. To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.
Towards Cross-modal Retrieval in Chinese Cultural Heritage Documents: Dataset and Solution
May 16, 2025China has a long and rich history, encompassing a vast cultural heritage that includes diverse multimodal information, such as silk patterns, Dunhuang murals, and their associated historical narratives. Cross-modal retrieval plays a pivotal role in understanding and interpreting Chinese cultural heritage by bridging visual and textual modalities to enable accurate text-to-image and image-to-text retrieval. However, despite the growing interest in multimodal research, there is a lack of specialized datasets dedicated to Chinese cultural heritage, limiting the development and evaluation of cross-modal learning models in this domain. To address this gap, we propose a multimodal dataset named CulTi, which contains 5,726 image-text pairs extracted from two series of professional documents, respectively related to ancient Chinese silk and Dunhuang murals. Compared to existing general-domain multimodal datasets, CulTi presents a challenge for cross-modal retrieval: the difficulty of local alignment between intricate decorative motifs and specialized textual descriptions. To address this challenge, we propose LACLIP, a training-free local alignment strategy built upon a fine-tuned Chinese-CLIP. LACLIP enhances the alignment of global textual descriptions with local visual regions by computing weighted similarity scores during inference. Experimental results on CulTi demonstrate that LACLIP significantly outperforms existing models in cross-modal retrieval, particularly in handling fine-grained semantic associations within Chinese cultural heritage.
FruitNinja: 3D Object Interior Texture Generation with Gaussian Splatting
Nov 21, 2024



In the real world, objects reveal internal textures when sliced or cut, yet this behavior is not well-studied in 3D generation tasks today. For example, slicing a virtual 3D watermelon should reveal flesh and seeds. Given that no available dataset captures an object's full internal structure and collecting data from all slices is impractical, generative methods become the obvious approach. However, current 3D generation and inpainting methods often focus on visible appearance and overlook internal textures. To bridge this gap, we introduce FruitNinja, the first method to generate internal textures for 3D objects undergoing geometric and topological changes. Our approach produces objects via 3D Gaussian Splatting (3DGS) with both surface and interior textures synthesized, enabling real-time slicing and rendering without additional optimization. FruitNinja leverages a pre-trained diffusion model to progressively inpaint cross-sectional views and applies voxel-grid-based smoothing to achieve cohesive textures throughout the object. Our OpaqueAtom GS strategy overcomes 3DGS limitations by employing densely distributed opaque Gaussians, avoiding biases toward larger particles that destabilize training and sharp color transitions for fine-grained textures. Experimental results show that FruitNinja substantially outperforms existing approaches, showcasing unmatched visual quality in real-time rendered internal views across arbitrary geometry manipulations.
Enhancing Exchange Rate Forecasting with Explainable Deep Learning Models
Oct 25, 2024
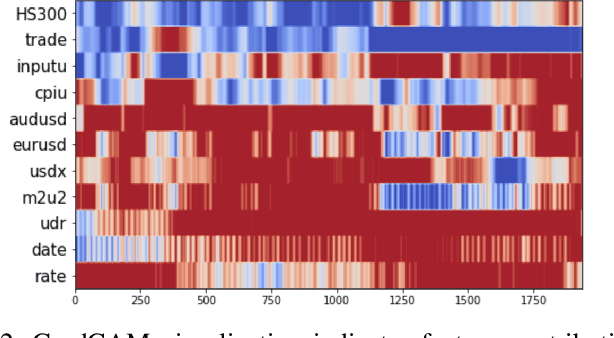

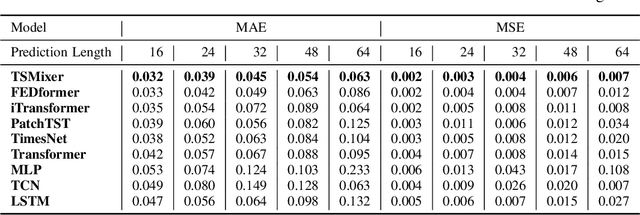
Accurate exchange rate prediction is fundamental to financial stability and international trade, positioning it as a critical focus in economic and financial research. Traditional forecasting models often falter when addressing the inherent complexities and non-linearities of exchange rate data. This study explores the application of advanced deep learning models, including LSTM, CNN, and transformer-based architectures, to enhance the predictive accuracy of the RMB/USD exchange rate. Utilizing 40 features across 6 categories, the analysis identifies TSMixer as the most effective model for this task. A rigorous feature selection process emphasizes the inclusion of key economic indicators, such as China-U.S. trade volumes and exchange rates of other major currencies like the euro-RMB and yen-dollar pairs. The integration of grad-CAM visualization techniques further enhances model interpretability, allowing for clearer identification of the most influential features and bolstering the credibility of the predictions. These findings underscore the pivotal role of fundamental economic data in exchange rate forecasting and highlight the substantial potential of machine learning models to deliver more accurate and reliable predictions, thereby serving as a valuable tool for financial analysis and decision-making.
Multi-task Prompt Words Learning for Social Media Content Generation
Jul 10, 2024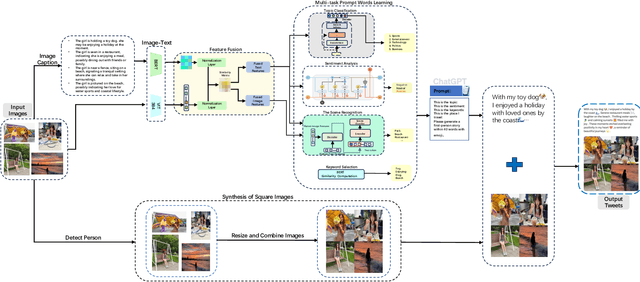
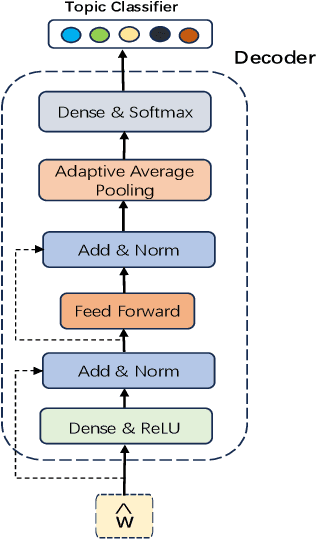
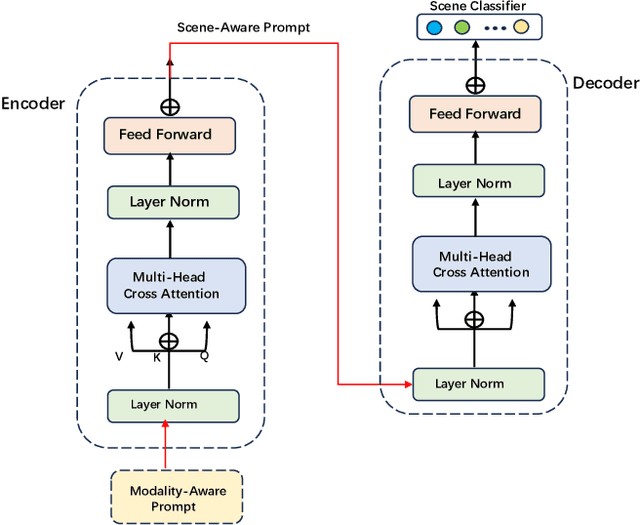
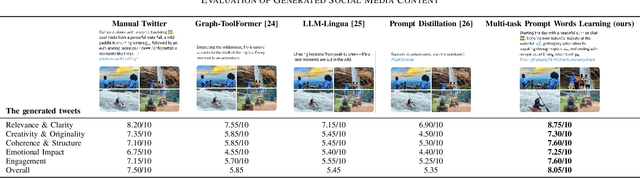
The rapid development of the Internet has profoundly changed human life. Humans are increasingly expressing themselves and interacting with others on social media platforms. However, although artificial intelligence technology has been widely used in many aspects of life, its application in social media content creation is still blank. To solve this problem, we propose a new prompt word generation framework based on multi-modal information fusion, which combines multiple tasks including topic classification, sentiment analysis, scene recognition and keyword extraction to generate more comprehensive prompt words. Subsequently, we use a template containing a set of prompt words to guide ChatGPT to generate high-quality tweets. Furthermore, in the absence of effective and objective evaluation criteria in the field of content generation, we use the ChatGPT tool to evaluate the results generated by the algorithm, making large-scale evaluation of content generation algorithms possible. Evaluation results on extensive content generation demonstrate that our cue word generation framework generates higher quality content compared to manual methods and other cueing techniques, while topic classification, sentiment analysis, and scene recognition significantly enhance content clarity and its consistency with the image.
* 8 pages, 5 figures