 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLR: Learning Quadruped Locomotion without Privileged Information
Jun 07, 2024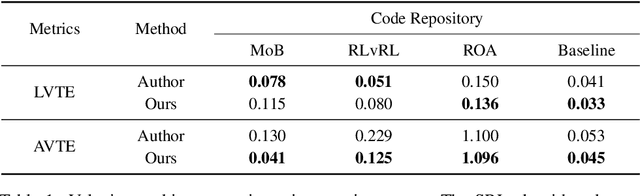
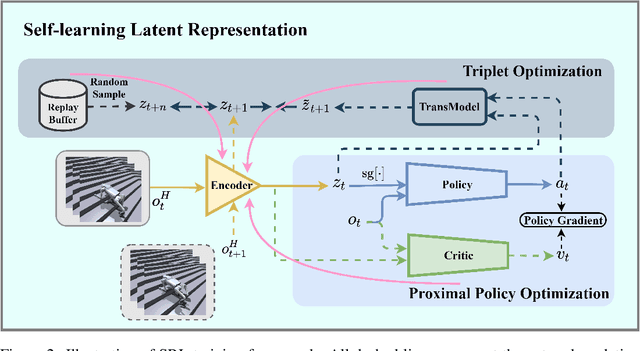
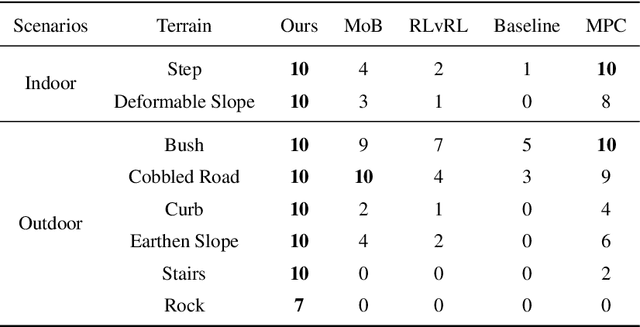
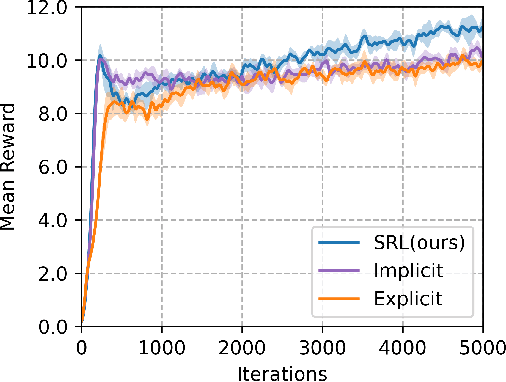
Traditional reinforcement learning control for quadruped robots often relies on privileged information, demanding meticulous selection and precise estimation, thereby imposing constraints on the development process. This work proposes a Self-learning Latent Representation (SLR) method, which achieves high-performance control policy learning without the need for privileged information. To enhance the credibility of our proposed method's evaluation, SLR is compared with open-source code repositories of state-of-the-art algorithms, retaining the original authors' configuration parameters. Across four repositories, SLR consistently outperforms the reference results. Ultimately, the trained policy and encoder empower the quadruped robot to navigate steps, climb stairs, ascend rocks, and traverse various challenging terrains. Robot experiment videos are at https://11chens.github.io/SLR/
Hyp-UML: Hyperbolic Image Retrieval with Uncertainty-aware Metric Learning
Oct 22, 2023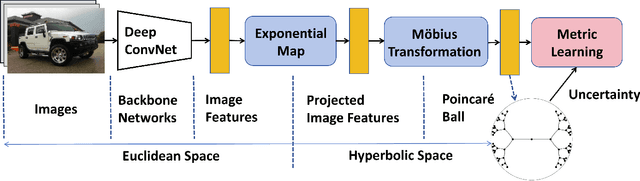
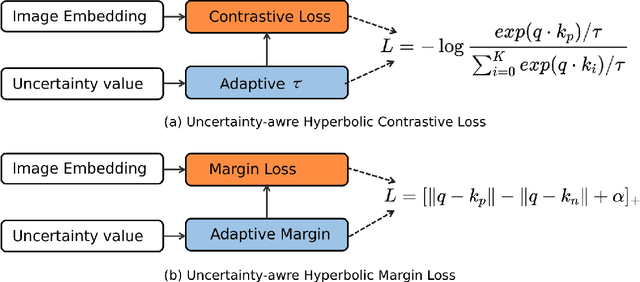
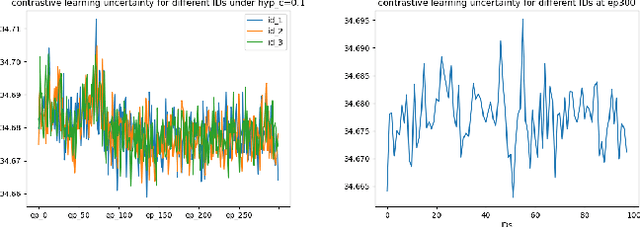

Metric learning plays a critical role in training image retrieval and classification. It is also a key algorithm in representation learning, e.g., for feature learning and its alignment in metric space. Hyperbolic embedding has been recently developed. Compared to the conventional Euclidean embedding in most of the previously developed models, Hyperbolic embedding can be more effective in representing the hierarchical data structure. Second, uncertainty estimation/measurement is a long-lasting challenge in artificial intelligence. Successful uncertainty estimation can improve a machine learning model's performance, robustness, and security. In Hyperbolic space, uncertainty measurement is at least with equivalent, if not more, critical importance. In this paper, we develop a Hyperbolic image embedding with uncertainty-aware metric learning for image retrieval. We call our method Hyp-UML: Hyperbolic Uncertainty-aware Metric Learning. Our contribution are threefold: we propose an image embedding algorithm based on Hyperbolic space, with their corresponding uncertainty value; we propose two types of uncertainty-aware metric learning, for the popular Contrastive learning and conventional margin-based metric learning, respectively. We perform extensive experimental validations to prove that the proposed algorithm can achieve state-of-the-art results among related methods. The comprehensive ablation study validates the effectiveness of each component of the proposed algorithm.
SC-ML: Self-supervised Counterfactual Metric Learning for Debiased Visual Question Answering
Apr 04, 2023



Visual question answering (VQA) is a critical multimodal task in which an agent must answer questions according to the visual cue. Unfortunately, language bias is a common problem in VQA, which refers to the model generating answers only by associating with the questions while ignoring the visual content, resulting in biased results. We tackle the language bias problem by proposing a self-supervised counterfactual metric learning (SC-ML) method to focus the image features better. SC-ML can adaptively select the question-relevant visual features to answer the question, reducing the negative influence of question-irrelevant visual features on inferring answers. In addition, question-irrelevant visual features can be seamlessly incorporated into counterfactual training schemes to further boost robustness. Extensive experiments have proved the effectiveness of our method with improved results on the VQA-CP dataset. Our code will be made publicly available.
AdaTriplet-RA: Domain Matching via Adaptive Triplet and Reinforced Attention for Unsupervised Domain Adaptation
Nov 16, 2022Unsupervised domain adaption (UDA) is a transfer learning task where the data and annotations of the source domain are available but only have access to the unlabeled target data during training. Most previous methods try to minimise the domain gap by performing distribution alignment between the source and target domains, which has a notable limitation, i.e., operating at the domain level, but neglecting the sample-level differences. To mitigate this weakness, we propose to improve the unsupervised domain adaptation task with an inter-domain sample matching scheme. We apply the widely-used and robust Triplet loss to match the inter-domain samples. To reduce the catastrophic effect of the inaccurate pseudo-labels generated during training, we propose a novel uncertainty measurement method to select reliable pseudo-labels automatically and progressively refine them. We apply the advanced discrete relaxation Gumbel Softmax technique to realise an adaptive Topk scheme to fulfil the functionality. In addition, to enable the global ranking optimisation within one batch for the domain matching, the whole model is optimised via a novel reinforced attention mechanism with supervision from the policy gradient algorithm, using the Average Precision (AP) as the reward. Our model (termed \textbf{\textit{AdaTriplet-RA}}) achieves State-of-the-art results on several public benchmark datasets, and its effectiveness is validated via comprehensive ablation studies. Our method improves the accuracy of the baseline by 9.7\% (ResNet-101) and 6.2\% (ResNet-50) on the VisDa dataset and 4.22\% (ResNet-50) on the Domainnet dataset. {The source code is publicly available at \textit{https://github.com/shuxy0120/AdaTriplet-RA}}.
Discrete-continuous Action Space Policy Gradient-based Attention for Image-Text Matching
Apr 21, 2021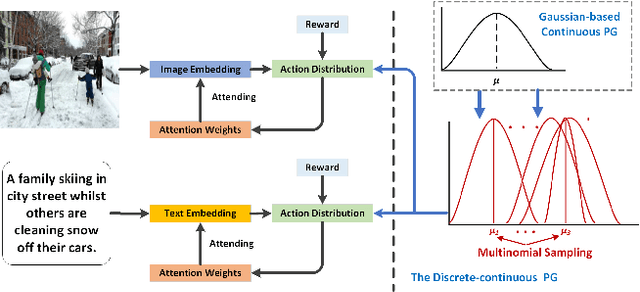
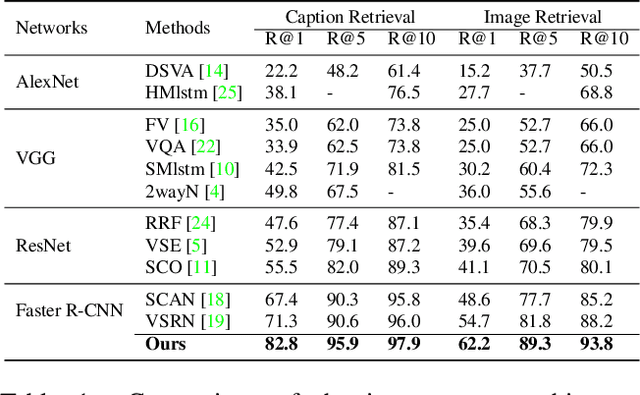
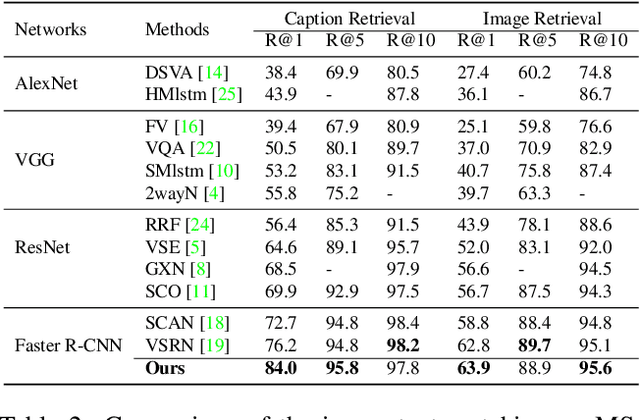
Image-text matching is an important multi-modal task with massive applications. It tries to match the image and the text with similar semantic information. Existing approaches do not explicitly transform the different modalities into a common space. Meanwhile, the attention mechanism which is widely used in image-text matching models does not have supervision. We propose a novel attention scheme which projects the image and text embedding into a common space and optimises the attention weights directly towards the evaluation metrics. The proposed attention scheme can be considered as a kind of supervised attention and requiring no additional annotations. It is trained via a novel Discrete-continuous action space policy gradient algorithm, which is more effective in modelling complex action space than previous continuous action space policy gradient. We evaluate the proposed methods on two widely-used benchmark datasets: Flickr30k and MS-COCO, outperforming the previous approaches by a large margin.
Off-Policy Self-Critical Training for Transformer in Visual Paragraph Generation
Jun 21, 2020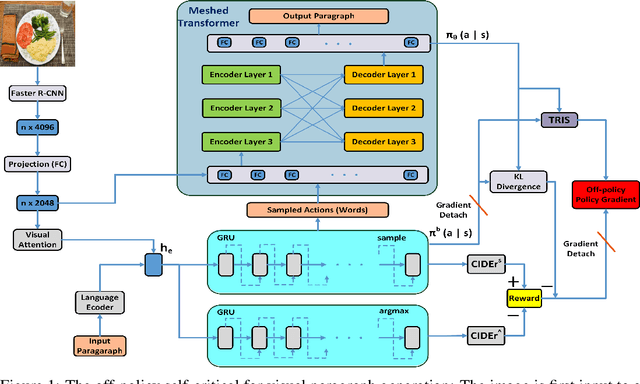
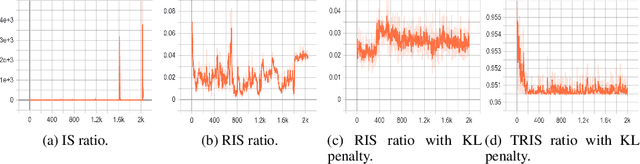


Recently, several approaches have been proposed to solve language generation problems. Transformer is currently state-of-the-art seq-to-seq model in language generation. Reinforcement Learning (RL) is useful in solving exposure bias and the optimisation on non-differentiable metrics in seq-to-seq language learning. However, Transformer is hard to combine with RL as the costly computing resource is required for sampling. We tackle this problem by proposing an off-policy RL learning algorithm where a behaviour policy represented by GRUs performs the sampling. We reduce the high variance of importance sampling (IS) by applying the truncated relative importance sampling (TRIS) technique and Kullback-Leibler (KL)-control concept. TRIS is a simple yet effective technique, and there is a theoretical proof that KL-control helps to reduce the variance of IS. We formulate this off-policy RL based on self-critical sequence training. Specifically, we use a Transformer-based captioning model as the target policy and use an image-guided language auto-encoder as the behaviour policy to explore the environment. The proposed algorithm achieves state-of-the-art performance on the visual paragraph generation and improved results on image captioning.
ParaCNN: Visual Paragraph Generation via Adversarial Twin Contextual CNNs
Apr 21, 2020

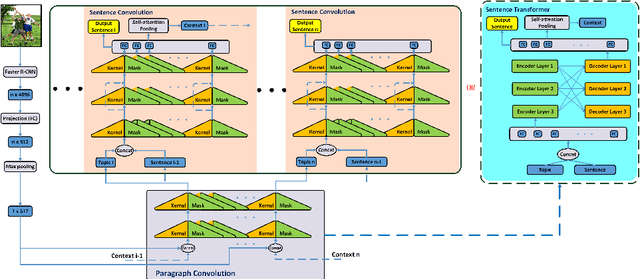

Image description generation plays an important role in many real-world applications, such as image retrieval, automatic navigation, and disabled people support. A well-developed task of image description generation is image captioning, which usually generates a short captioning sentence and thus neglects many of fine-grained properties, e.g., the information of subtle objects and their relationships. In this paper, we study the visual paragraph generation, which can describe the image with a long paragraph containing rich details. Previous research often generates the paragraph via a hierarchical Recurrent Neural Network (RNN)-like model, which has complex memorising, forgetting and coupling mechanism. Instead, we propose a novel pure CNN model, ParaCNN, to generate visual paragraph using hierarchical CNN architecture with contextual information between sentences within one paragraph. The ParaCNN can generate an arbitrary length of a paragraph, which is more applicable in many real-world applications. Furthermore, to enable the ParaCNN to model paragraph comprehensively, we also propose an adversarial twin net training scheme. During training, we force the forwarding network's hidden features to be close to that of the backwards network by using adversarial training. During testing, we only use the forwarding network, which already includes the knowledge of the backwards network, to generate a paragraph. We conduct extensive experiments on the Stanford Visual Paragraph dataset and achieve state-of-the-art performance.
HorNet: A Hierarchical Offshoot Recurrent Network for Improving Person Re-ID via Image Captioning
Aug 14, 2019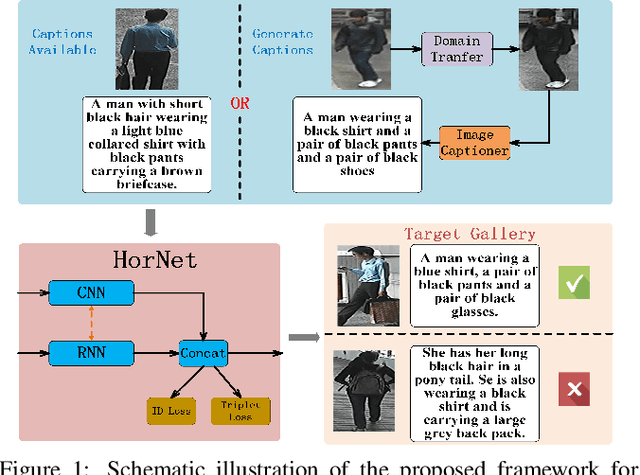
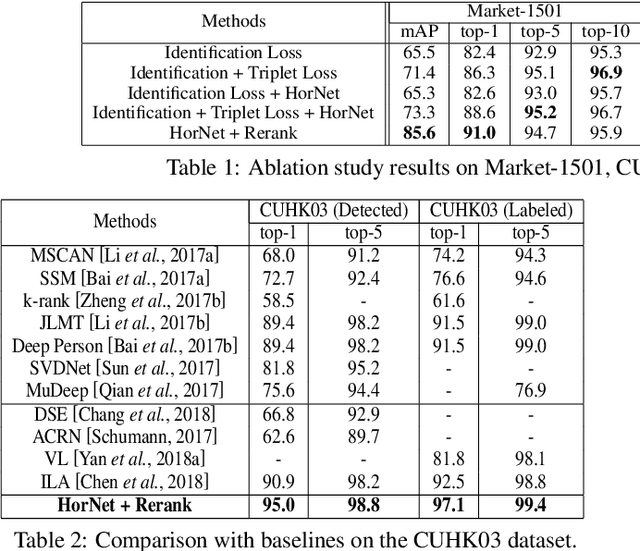
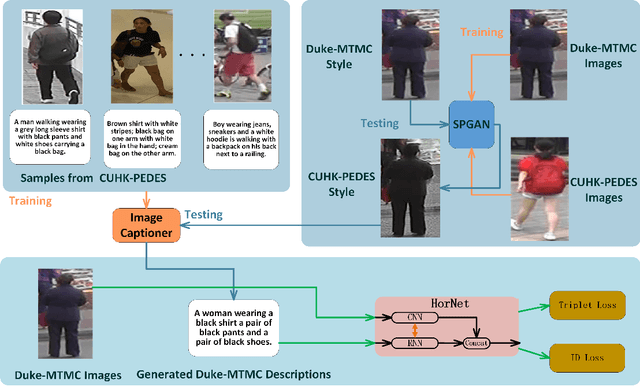
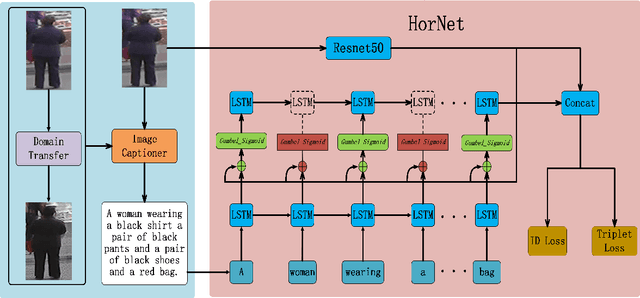
Person re-identification (re-ID) aims to recognize a person-of-interest across different cameras with notable appearance variance. Existing research works focused on the capability and robustness of visual representation. In this paper, instead, we propose a novel hierarchical offshoot recurrent network (HorNet) for improving person re-ID via image captioning. Image captions are semantically richer and more consistent than visual attributes, which could significantly alleviate the variance. We use the similarity preserving generative adversarial network (SPGAN) and an image captioner to fulfill domain transfer and language descriptions generation. Then the proposed HorNet can learn the visual and language representation from both the images and captions jointly, and thus enhance the performance of person re-ID. Extensive experiments are conducted on several benchmark datasets with or without image captions, i.e., CUHK03, Market-1501, and Duke-MTMC, demonstrating the superiority of the proposed method. Our method can generate and extract meaningful image captions while achieving state-of-the-art performance.
Image Captioning Based on a Hierarchical Attention Mechanism and Policy Gradient Optimization
Nov 13, 2018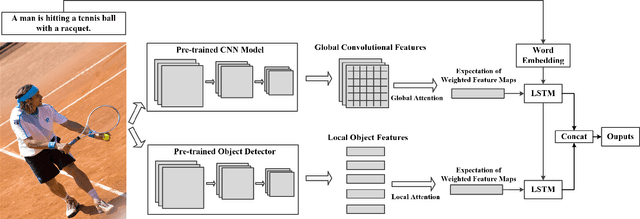
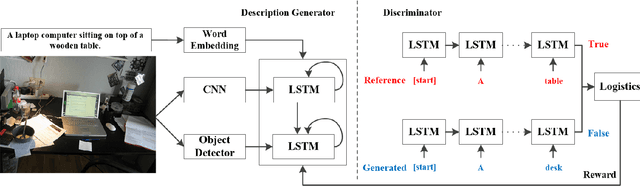
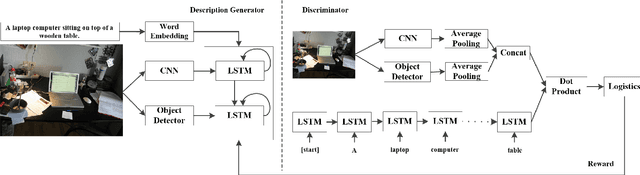
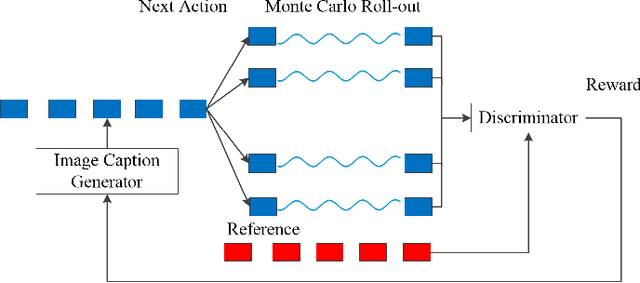
Automatically generating the descriptions of an image, i.e., image captioning, is an important and fundamental topic in artificial intelligence, which bridges the gap between computer vision and natural language processing. Based on the successful deep learning models, especially the CNN model and Long Short-Term Memories (LSTMs) with attention mechanism, we propose a hierarchical attention model by utilizing both of the global CNN features and the local object features for more effective feature representation and reasoning in image captioning. The generative adversarial network (GAN), together with a reinforcement learning (RL) algorithm, is applied to solve the exposure bias problem in RNN-based supervised training for language problems. In addition, through the automatic measurement of the consistency between the generated caption and the image content by the discriminator in the GAN framework and RL optimization, we make the finally generated sentences more accurate and natural. Comprehensive experiments show the improved performance of the hierarchical attention mechanism and the effectiveness of our RL-based optimization method. Our model achieves state-of-the-art results on several important metrics in the MSCOCO dataset, using only greedy inference.
Hierarchical Multi-scale Attention Networks for Action Recognition
Aug 28, 2017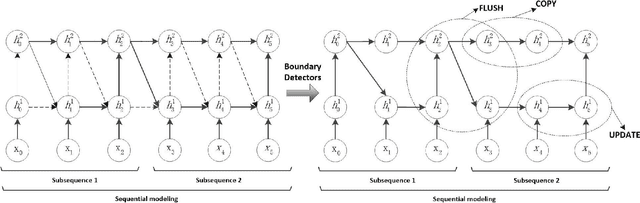
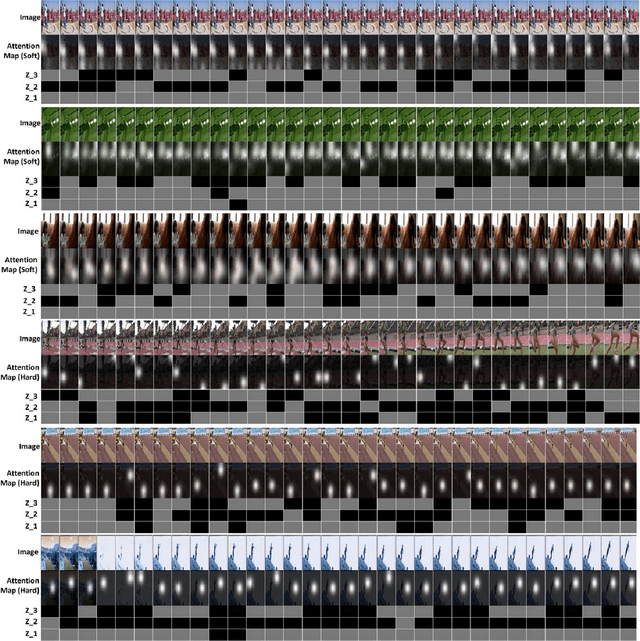
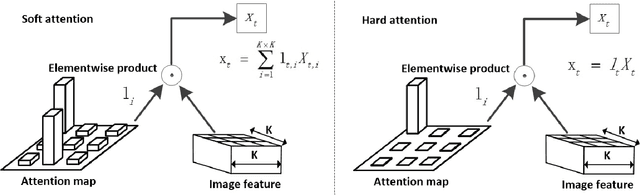
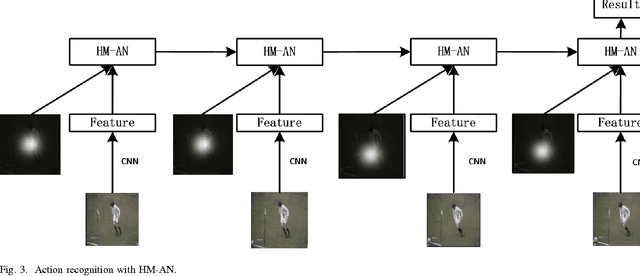
Recurrent Neural Networks (RNNs) have been widely used in natural language processing and computer vision. Among them, the Hierarchical Multi-scale RNN (HM-RNN), a kind of multi-scale hierarchical RNN proposed recently, can learn the hierarchical temporal structure from data automatically. In this paper, we extend the work to solve the computer vision task of action recognition. However, in sequence-to-sequence models like RNN, it is normally very hard to discover the relationships between inputs and outputs given static inputs. As a solution, attention mechanism could be applied to extract the relevant information from input thus facilitating the modeling of input-output relationships. Based on these considerations, we propose a novel attention network, namely Hierarchical Multi-scale Attention Network (HM-AN), by combining the HM-RNN and the attention mechanism and apply it to action recognition. A newly proposed gradient estimation method for stochastic neurons, namely Gumbel-softmax, is exploited to implement the temporal boundary detectors and the stochastic hard attention mechanism. To amealiate the negative effect of sensitive temperature of the Gumbel-softmax, an adaptive temperature training method is applied to better the system performance. The experimental results demonstrate the improved effect of HM-AN over LSTM with attention on the vision task. Through visualization of what have been learnt by the networks, it can be observed that both the attention regions of images and the hierarchical temporal structure can be captured by HM-AN.