 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025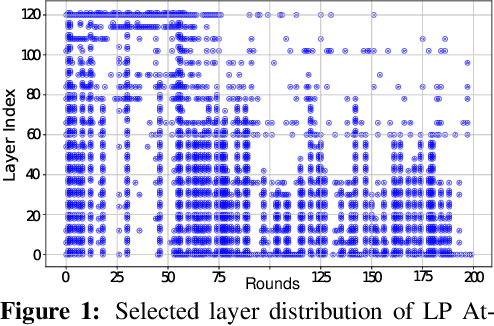



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark
Jun 04, 2025As AI evolves, collaboration among heterogeneous models helps overcome data scarcity by enabling knowledge transfer across institutions and devices. Traditional Federated Learning (FL) only supports homogeneous models, limiting collaboration among clients with heterogeneous model architectures. To address this, Heterogeneous Federated Learning (HtFL) methods are developed to enable collaboration across diverse heterogeneous models while tackling the data heterogeneity issue at the same time. However, a comprehensive benchmark for standardized evaluation and analysis of the rapidly growing HtFL methods is lacking. Firstly, the highly varied datasets, model heterogeneity scenarios, and different method implementations become hurdles to making easy and fair comparisons among HtFL methods. Secondly, the effectiveness and robustness of HtFL methods are under-explored in various scenarios, such as the medical domain and sensor signal modality. To fill this gap, we introduce the first Heterogeneous Federated Learning Library (HtFLlib), an easy-to-use and extensible framework that integrates multiple datasets and model heterogeneity scenarios, offering a robust benchmark for research and practical applications. Specifically, HtFLlib integrates (1) 12 datasets spanning various domains, modalities, and data heterogeneity scenarios; (2) 40 model architectures, ranging from small to large, across three modalities; (3) a modularized and easy-to-extend HtFL codebase with implementations of 10 representative HtFL methods; and (4) systematic evaluations in terms of accuracy, convergence, computation costs, and communication costs. We emphasize the advantages and potential of state-of-the-art HtFL methods and hope that HtFLlib will catalyze advancing HtFL research and enable its broader applications. The code is released at https://github.com/TsingZ0/HtFLlib.
FedL2G: Learning to Guide Local Training in Heterogeneous Federated Learning
Oct 09, 2024



Data and model heterogeneity are two core issues in Heterogeneous Federated Learning (HtFL). In scenarios with heterogeneous model architectures, aggregating model parameters becomes infeasible, leading to the use of prototypes (i.e., class representative feature vectors) for aggregation and guidance. However, they still experience a mismatch between the extra guiding objective and the client's original local objective when aligned with global prototypes. Thus, we propose a Federated Learning-to-Guide (FedL2G) method that adaptively learns to guide local training in a federated manner and ensures the extra guidance is beneficial to clients' original tasks. With theoretical guarantees, FedL2G efficiently implements the learning-to-guide process using only first-order derivatives w.r.t. model parameters and achieves a non-convex convergence rate of O(1/T). We conduct extensive experiments on two data heterogeneity and six model heterogeneity settings using 14 heterogeneous model architectures (e.g., CNNs and ViTs) to demonstrate FedL2G's superior performance compared to six counterparts.
Poisoning with A Pill: Circumventing Detection in Federated Learning
Jul 22, 2024



Without direct access to the client's data, federated learning (FL) is well-known for its unique strength in data privacy protection among existing distributed machine learning techniques. However, its distributive and iterative nature makes FL inherently vulnerable to various poisoning attacks. To counteract these threats, extensive defenses have been proposed to filter out malicious clients, using various detection metrics. Based on our analysis of existing attacks and defenses, we find that there is a lack of attention to model redundancy. In neural networks, various model parameters contribute differently to the model's performance. However, existing attacks in FL manipulate all the model update parameters with the same strategy, making them easily detectable by common defenses. Meanwhile, the defenses also tend to analyze the overall statistical features of the entire model updates, leaving room for sophisticated attacks. Based on these observations, this paper proposes a generic and attack-agnostic augmentation approach designed to enhance the effectiveness and stealthiness of existing FL poisoning attacks against detection in FL, pointing out the inherent flaws of existing defenses and exposing the necessity of fine-grained FL security. Specifically, we employ a three-stage methodology that strategically constructs, generates, and injects poison (generated by existing attacks) into a pill (a tiny subnet with a novel structure) during the FL training, named as pill construction, pill poisoning, and pill injection accordingly. Extensive experimental results show that FL poisoning attacks enhanced by our method can bypass all the popular defenses, and can gain an up to 7x error rate increase, as well as on average a more than 2x error rate increase on both IID and non-IID data, in both cross-silo and cross-device FL systems.
Exploring Diffusion Models' Corruption Stage in Few-Shot Fine-tuning and Mitigating with Bayesian Neural Networks
May 30, 2024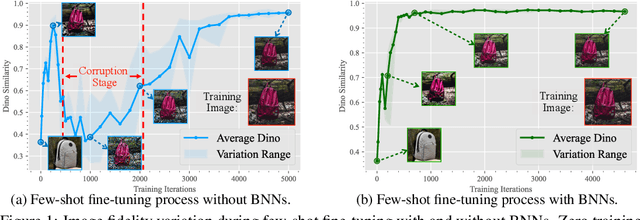
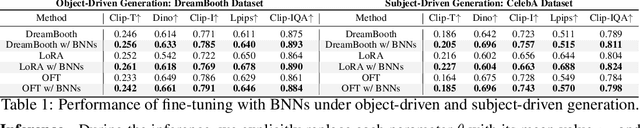
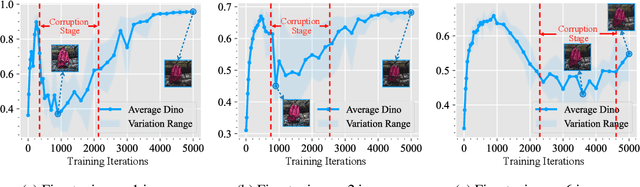
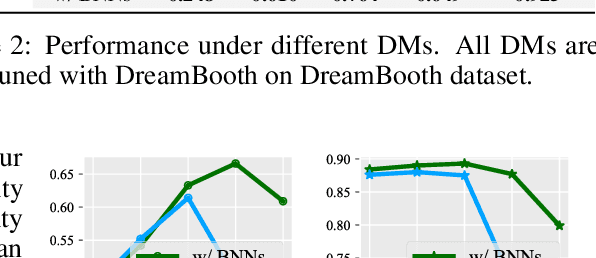
Few-shot fine-tuning of Diffusion Models (DMs) is a key advancement, significantly reducing training costs and enabling personalized AI applications. However, we explore the training dynamics of DMs and observe an unanticipated phenomenon: during the training process, image fidelity initially improves, then unexpectedly deteriorates with the emergence of noisy patterns, only to recover later with severe overfitting. We term the stage with generated noisy patterns as corruption stage. To understand this corruption stage, we begin by theoretically modeling the one-shot fine-tuning scenario, and then extend this modeling to more general cases. Through this modeling, we identify the primary cause of this corruption stage: a narrowed learning distribution inherent in the nature of few-shot fine-tuning. To tackle this, we apply Bayesian Neural Networks (BNNs) on DMs with variational inference to implicitly broaden the learned distribution, and present that the learning target of the BNNs can be naturally regarded as an expectation of the diffusion loss and a further regularization with the pretrained DMs. This approach is highly compatible with current few-shot fine-tuning methods in DMs and does not introduce any extra inference costs. Experimental results demonstrate that our method significantly mitigates corruption, and improves the fidelity, quality and diversity of the generated images in both object-driven and subject-driven generation tasks.
An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning
Mar 23, 2024
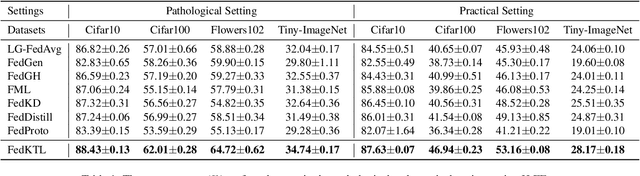
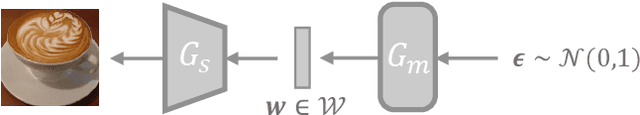
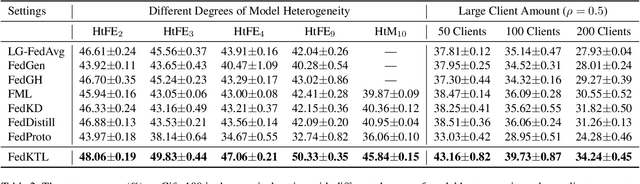
Heterogeneous Federated Learning (HtFL) enables collaborative learning on multiple clients with different model architectures while preserving privacy. Despite recent research progress, knowledge sharing in HtFL is still difficult due to data and model heterogeneity. To tackle this issue, we leverage the knowledge stored in pre-trained generators and propose a new upload-efficient knowledge transfer scheme called Federated Knowledge-Transfer Loop (FedKTL). Our FedKTL can produce client-task-related prototypical image-vector pairs via the generator's inference on the server. With these pairs, each client can transfer pre-existing knowledge from the generator to its local model through an additional supervised local task. We conduct extensive experiments on four datasets under two types of data heterogeneity with 14 kinds of models including CNNs and ViTs. Results show that our upload-efficient FedKTL surpasses seven state-of-the-art methods by up to 7.31% in accuracy. Moreover, our knowledge transfer scheme is applicable in scenarios with only one edge client. Code: https://github.com/TsingZ0/FedKTL
CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
Mar 17, 2024


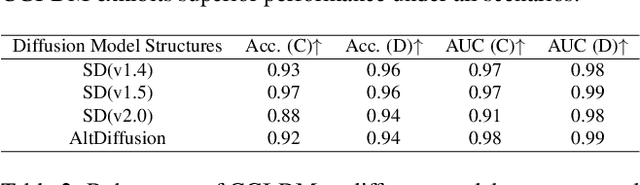
Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot generation where a pretrained model is fine-tuned on a small set of images to capture a specific style or object. Despite their success, concerns exist about potential copyright violations stemming from the use of unauthorized data in this process. In response, we present Contrasting Gradient Inversion for Diffusion Models (CGI-DM), a novel method featuring vivid visual representations for digital copyright authentication. Our approach involves removing partial information of an image and recovering missing details by exploiting conceptual differences between the pretrained and fine-tuned models. We formulate the differences as KL divergence between latent variables of the two models when given the same input image, which can be maximized through Monte Carlo sampling and Projected Gradient Descent (PGD). The similarity between original and recovered images serves as a strong indicator of potential infringements. Extensive experiments on the WikiArt and Dreambooth datasets demonstrate the high accuracy of CGI-DM in digital copyright authentication, surpassing alternative validation techniques. Code implementation is available at https://github.com/Nicholas0228/Revelio.
Efficient One-stage Video Object Detection by Exploiting Temporal Consistency
Feb 14, 2024Recently, one-stage detectors have achieved competitive accuracy and faster speed compared with traditional two-stage detectors on image data. However, in the field of video object detection (VOD), most existing VOD methods are still based on two-stage detectors. Moreover, directly adapting existing VOD methods to one-stage detectors introduces unaffordable computational costs. In this paper, we first analyse the computational bottlenecks of using one-stage detectors for VOD. Based on the analysis, we present a simple yet efficient framework to address the computational bottlenecks and achieve efficient one-stage VOD by exploiting the temporal consistency in video frames. Specifically, our method consists of a location-prior network to filter out background regions and a size-prior network to skip unnecessary computations on low-level feature maps for specific frames. We test our method on various modern one-stage detectors and conduct extensive experiments on the ImageNet VID dataset. Excellent experimental results demonstrate the superior effectiveness, efficiency, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
TDViT: Temporal Dilated Video Transformer for Dense Video Tasks
Feb 14, 2024Deep video models, for example, 3D CNNs or video transformers, have achieved promising performance on sparse video tasks, i.e., predicting one result per video. However, challenges arise when adapting existing deep video models to dense video tasks, i.e., predicting one result per frame. Specifically, these models are expensive for deployment, less effective when handling redundant frames, and difficult to capture long-range temporal correlations. To overcome these issues, we propose a Temporal Dilated Video Transformer (TDViT) that consists of carefully designed temporal dilated transformer blocks (TDTB). TDTB can efficiently extract spatiotemporal representations and effectively alleviate the negative effect of temporal redundancy. Furthermore, by using hierarchical TDTBs, our approach obtains an exponentially expanded temporal receptive field and therefore can model long-range dynamics. Extensive experiments are conducted on two different dense video benchmarks, i.e., ImageNet VID for video object detection and YouTube VIS for video instance segmentation. Excellent experimental results demonstrate the superior efficiency, effectiveness, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.
Spatio-temporal Prompting Network for Robust Video Feature Extraction
Feb 04, 2024Frame quality deterioration is one of the main challenges in the field of video understanding. To compensate for the information loss caused by deteriorated frames, recent approaches exploit transformer-based integration modules to obtain spatio-temporal information. However, these integration modules are heavy and complex. Furthermore, each integration module is specifically tailored for its target task, making it difficult to generalise to multiple tasks. In this paper, we present a neat and unified framework, called Spatio-Temporal Prompting Network (STPN). It can efficiently extract robust and accurate video features by dynamically adjusting the input features in the backbone network. Specifically, STPN predicts several video prompts containing spatio-temporal information of neighbour frames. Then, these video prompts are prepended to the patch embeddings of the current frame as the updated input for video feature extraction. Moreover, STPN is easy to generalise to various video tasks because it does not contain task-specific modules. Without bells and whistles, STPN achieves state-of-the-art performance on three widely-used datasets for different video understanding tasks, i.e., ImageNetVID for video object detection, YouTubeVIS for video instance segmentation, and GOT-10k for visual object tracking. Code is available at https://github.com/guanxiongsun/vfe.pytorch.