 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIneq-Comp: Benchmarking Human-Intuitive Compositional Reasoning in Automated Theorem Proving on Inequalities
May 19, 2025LLM-based formal proof assistants (e.g., in Lean) hold great promise for automating mathematical discovery. But beyond syntactic correctness, do these systems truly understand mathematical structure as humans do? We investigate this question through the lens of mathematical inequalities -- a fundamental tool across many domains. While modern provers can solve basic inequalities, we probe their ability to handle human-intuitive compositionality. We introduce Ineq-Comp, a benchmark built from elementary inequalities through systematic transformations, including variable duplication, algebraic rewriting, and multi-step composition. Although these problems remain easy for humans, we find that most provers -- including Goedel, STP, and Kimina-7B -- struggle significantly. DeepSeek-Prover-V2-7B shows relative robustness -- possibly because it is trained to decompose the problems into sub-problems -- but still suffers a 20\% performance drop (pass@32). Strikingly, performance remains poor for all models even when formal proofs of the constituent parts are provided in context, revealing that the source of weakness is indeed in compositional reasoning. Our results expose a persisting gap between the generalization behavior of current AI provers and human mathematical intuition.
Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
Feb 11, 2025We introduce Goedel-Prover, an open-source large language model (LLM) that achieves the state-of-the-art (SOTA) performance in automated formal proof generation for mathematical problems. The key challenge in this field is the scarcity of formalized math statements and proofs, which we tackle in the following ways. We train statement formalizers to translate the natural language math problems from Numina into formal language (Lean 4), creating a dataset of 1.64 million formal statements. LLMs are used to check that the formal statements accurately preserve the content of the original natural language problems. We then iteratively build a large dataset of formal proofs by training a series of provers. Each prover succeeds in proving many statements that the previous ones could not, and these new proofs are added to the training set for the next prover. The final prover outperforms all existing open-source models in whole-proof generation. On the miniF2F benchmark, it achieves a 57.6% success rate (Pass@32), exceeding the previous best open-source model by 7.6%. On PutnamBench, Goedel-Prover successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by earlier works.
Adapting While Learning: Grounding LLMs for Scientific Problems with Intelligent Tool Usage Adaptation
Nov 01, 2024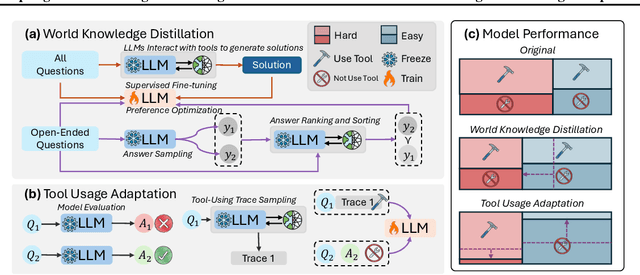
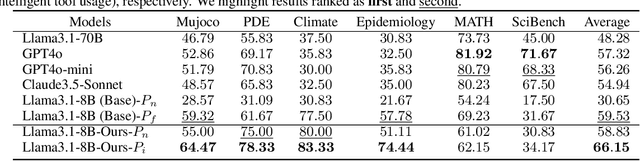
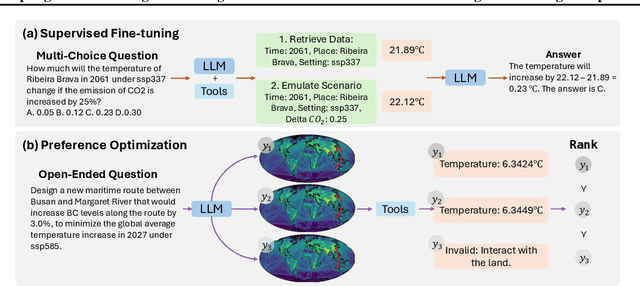
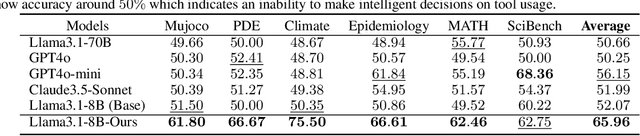
Large Language Models (LLMs) demonstrate promising capabilities in solving simple scientific problems but often produce hallucinations for complex ones. While integrating LLMs with tools can increase reliability, this approach typically results in over-reliance on tools, diminishing the model's ability to solve simple problems through basic reasoning. In contrast, human experts first assess problem complexity using domain knowledge before choosing an appropriate solution approach. Inspired by this human problem-solving process, we propose a novel two-component fine-tuning method. In the first component World Knowledge Distillation (WKD), LLMs learn directly from solutions generated using tool's information to internalize domain knowledge. In the second component Tool Usage Adaptation (TUA), we partition problems into easy and hard categories based on the model's direct answering accuracy. While maintaining the same alignment target for easy problems as in WKD, we train the model to intelligently switch to tool usage for more challenging problems. We validate our method on six scientific benchmark datasets, spanning mathematics, climate science and epidemiology. On average, our models demonstrate a 28.18% improvement in answer accuracy and a 13.89% increase in tool usage precision across all datasets, surpassing state-of-the-art models including GPT-4o and Claude-3.5.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024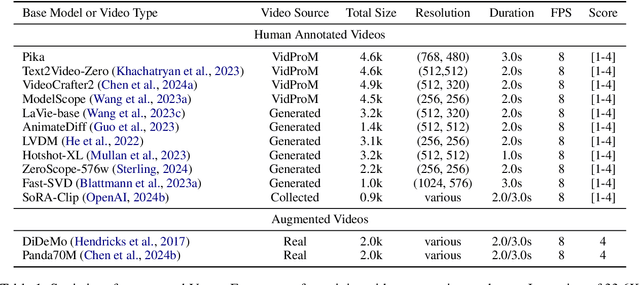

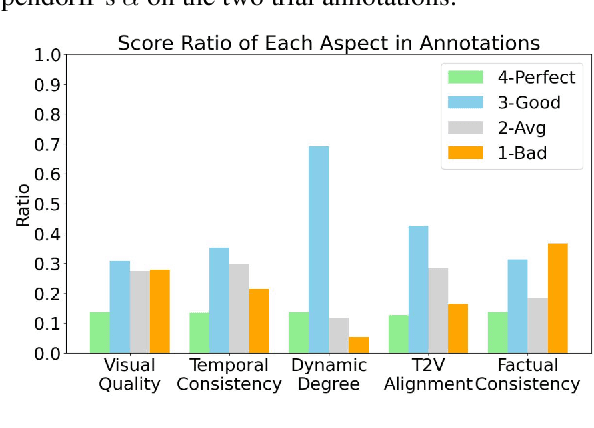

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
Exploring Diffusion Models' Corruption Stage in Few-Shot Fine-tuning and Mitigating with Bayesian Neural Networks
May 30, 2024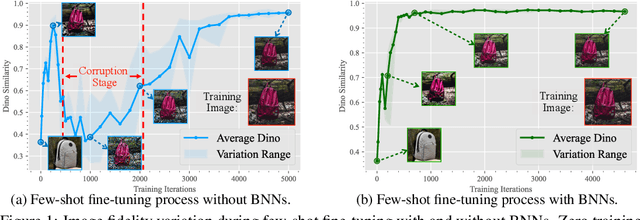
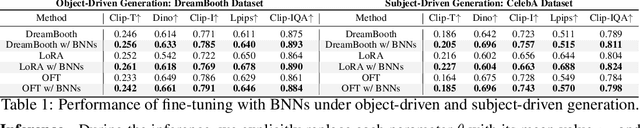
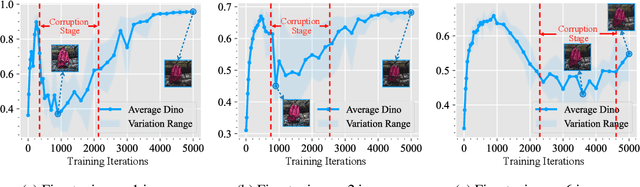
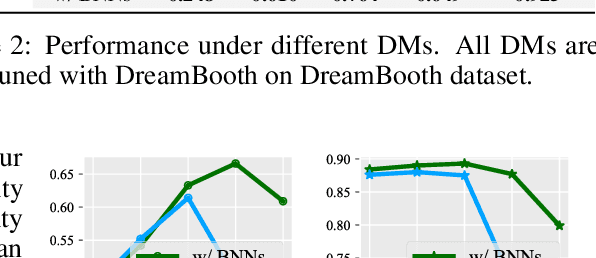
Few-shot fine-tuning of Diffusion Models (DMs) is a key advancement, significantly reducing training costs and enabling personalized AI applications. However, we explore the training dynamics of DMs and observe an unanticipated phenomenon: during the training process, image fidelity initially improves, then unexpectedly deteriorates with the emergence of noisy patterns, only to recover later with severe overfitting. We term the stage with generated noisy patterns as corruption stage. To understand this corruption stage, we begin by theoretically modeling the one-shot fine-tuning scenario, and then extend this modeling to more general cases. Through this modeling, we identify the primary cause of this corruption stage: a narrowed learning distribution inherent in the nature of few-shot fine-tuning. To tackle this, we apply Bayesian Neural Networks (BNNs) on DMs with variational inference to implicitly broaden the learned distribution, and present that the learning target of the BNNs can be naturally regarded as an expectation of the diffusion loss and a further regularization with the pretrained DMs. This approach is highly compatible with current few-shot fine-tuning methods in DMs and does not introduce any extra inference costs. Experimental results demonstrate that our method significantly mitigates corruption, and improves the fidelity, quality and diversity of the generated images in both object-driven and subject-driven generation tasks.
GitAgent: Facilitating Autonomous Agent with GitHub by Tool Extension
Dec 28, 2023While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated exceptional proficiency in natural language processing, their efficacy in addressing complex, multifaceted tasks remains limited. A growing area of research focuses on LLM-based agents equipped with external tools capable of performing diverse tasks. However, existing LLM-based agents only support a limited set of tools which is unable to cover a diverse range of user queries, especially for those involving expertise domains. It remains a challenge for LLM-based agents to extend their tools autonomously when confronted with various user queries. As GitHub has hosted a multitude of repositories which can be seen as a good resource for tools, a promising solution is that LLM-based agents can autonomously integrate the repositories in GitHub according to the user queries to extend their tool set. In this paper, we introduce GitAgent, an agent capable of achieving the autonomous tool extension from GitHub. GitAgent follows a four-phase procedure to incorporate repositories and it can learn human experience by resorting to GitHub Issues/PRs to solve problems encountered during the procedure. Experimental evaluation involving 30 user queries demonstrates GitAgent's effectiveness, achieving a 69.4% success rate on average.
An Efficient Data Analysis Method for Big Data using Multiple-Model Linear Regression
Aug 24, 2023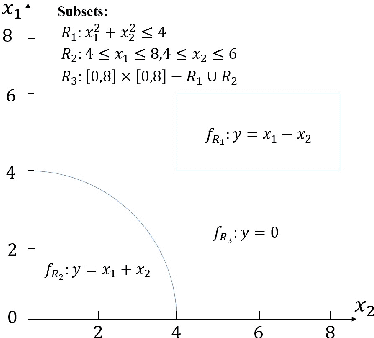
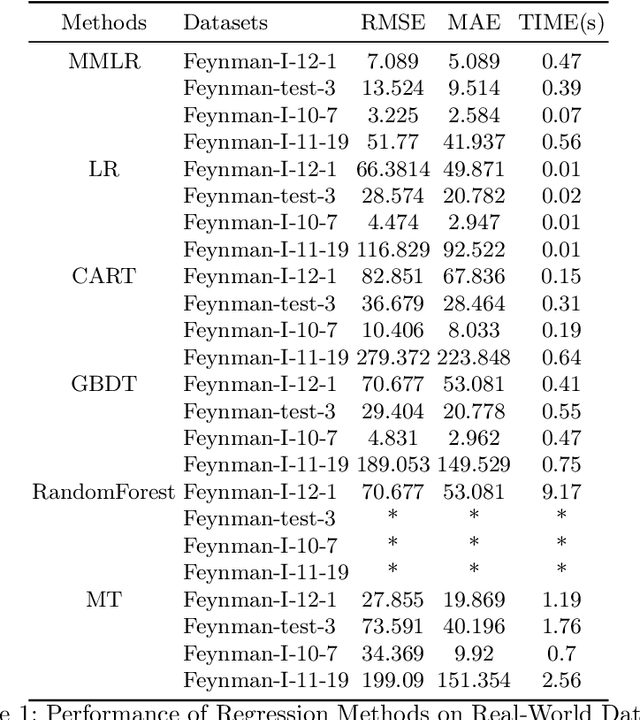
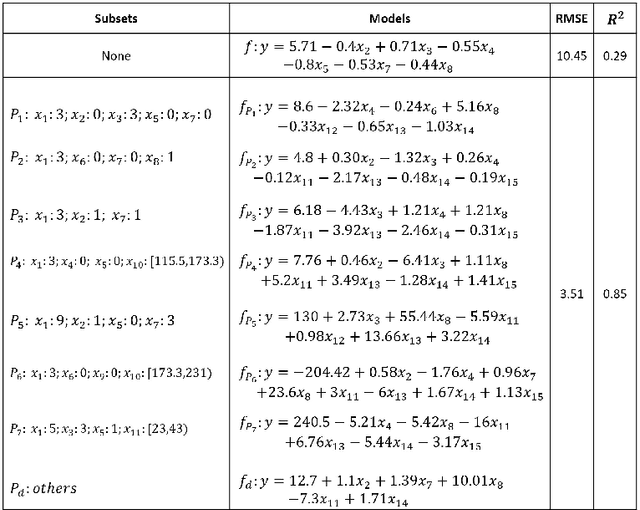
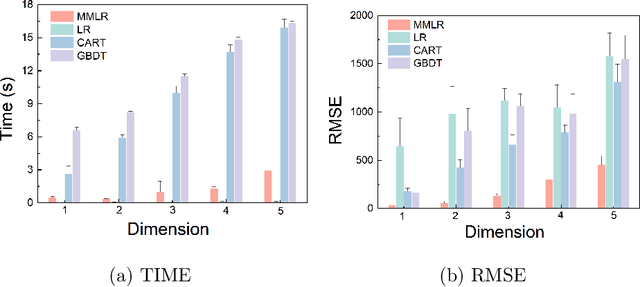
This paper introduces a new data analysis method for big data using a newly defined regression model named multiple model linear regression(MMLR), which separates input datasets into subsets and construct local linear regression models of them. The proposed data analysis method is shown to be more efficient and flexible than other regression based methods. This paper also proposes an approximate algorithm to construct MMLR models based on $(\epsilon,\delta)$-estimator, and gives mathematical proofs of the correctness and efficiency of MMLR algorithm, of which the time complexity is linear with respect to the size of input datasets. This paper also empirically implements the method on both synthetic and real-world datasets, the algorithm shows to have comparable performance to existing regression methods in many cases, while it takes almost the shortest time to provide a high prediction accuracy.