 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024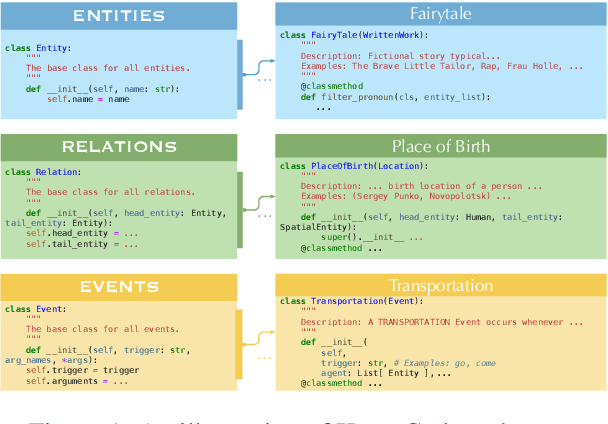
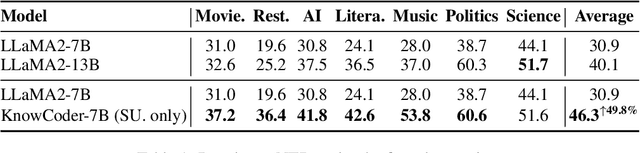
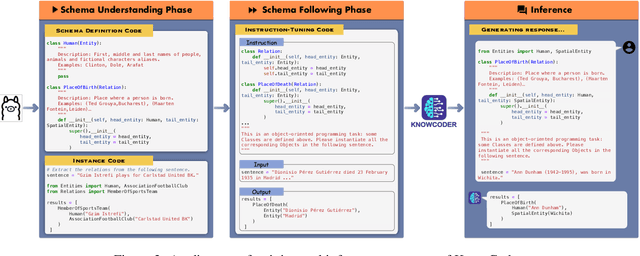
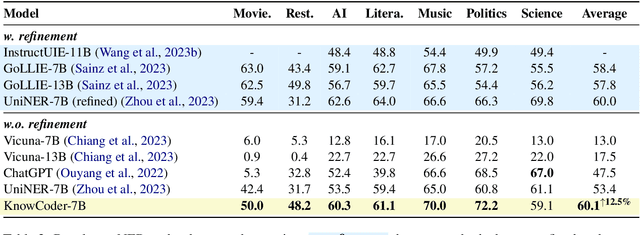
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.
GitAgent: Facilitating Autonomous Agent with GitHub by Tool Extension
Dec 28, 2023While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated exceptional proficiency in natural language processing, their efficacy in addressing complex, multifaceted tasks remains limited. A growing area of research focuses on LLM-based agents equipped with external tools capable of performing diverse tasks. However, existing LLM-based agents only support a limited set of tools which is unable to cover a diverse range of user queries, especially for those involving expertise domains. It remains a challenge for LLM-based agents to extend their tools autonomously when confronted with various user queries. As GitHub has hosted a multitude of repositories which can be seen as a good resource for tools, a promising solution is that LLM-based agents can autonomously integrate the repositories in GitHub according to the user queries to extend their tool set. In this paper, we introduce GitAgent, an agent capable of achieving the autonomous tool extension from GitHub. GitAgent follows a four-phase procedure to incorporate repositories and it can learn human experience by resorting to GitHub Issues/PRs to solve problems encountered during the procedure. Experimental evaluation involving 30 user queries demonstrates GitAgent's effectiveness, achieving a 69.4% success rate on average.
Retrieval-Augmented Code Generation for Universal Information Extraction
Nov 06, 2023



Information Extraction (IE) aims to extract structural knowledge (e.g., entities, relations, events) from natural language texts, which brings challenges to existing methods due to task-specific schemas and complex text expressions. Code, as a typical kind of formalized language, is capable of describing structural knowledge under various schemas in a universal way. On the other hand, Large Language Models (LLMs) trained on both codes and texts have demonstrated powerful capabilities of transforming texts into codes, which provides a feasible solution to IE tasks. Therefore, in this paper, we propose a universal retrieval-augmented code generation framework based on LLMs, called Code4UIE, for IE tasks. Specifically, Code4UIE adopts Python classes to define task-specific schemas of various structural knowledge in a universal way. By so doing, extracting knowledge under these schemas can be transformed into generating codes that instantiate the predefined Python classes with the information in texts. To generate these codes more precisely, Code4UIE adopts the in-context learning mechanism to instruct LLMs with examples. In order to obtain appropriate examples for different tasks, Code4UIE explores several example retrieval strategies, which can retrieve examples semantically similar to the given texts. Extensive experiments on five representative IE tasks across nine datasets demonstrate the effectiveness of the Code4UIE framework.
A Variational Auto-Encoder Enabled Multi-Band Channel Prediction Scheme for Indoor Localization
Sep 19, 2023
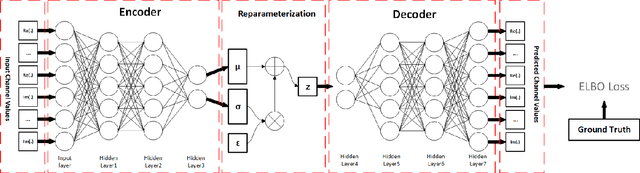

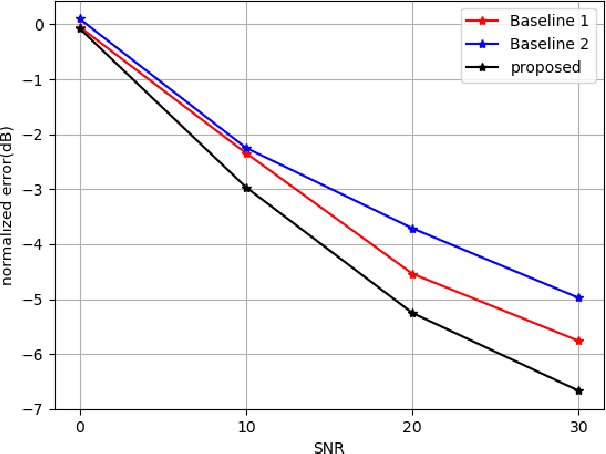
Indoor localization is getting increasing demands for various cutting-edged technologies, like Virtual/Augmented reality and smart home. Traditional model-based localization suffers from significant computational overhead, so fingerprint localization is getting increasing attention, which needs lower computation cost after the fingerprint database is built. However, the accuracy of indoor localization is limited by the complicated indoor environment which brings the multipath signal refraction. In this paper, we provided a scheme to improve the accuracy of indoor fingerprint localization from the frequency domain by predicting the channel state information (CSI) values from another transmitting channel and spliced the multi-band information together to get more precise localization results. We tested our proposed scheme on COST 2100 simulation data and real time orthogonal frequency division multiplexing (OFDM) WiFi data collected from an office scenario.
Enhanced Language Representation with Label Knowledge for Span Extraction
Nov 01, 2021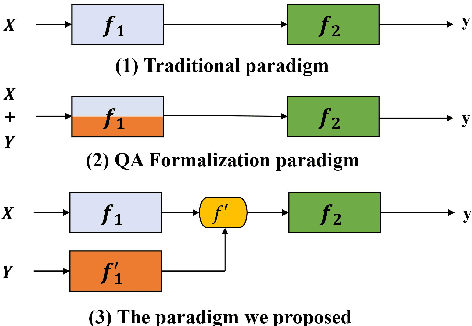


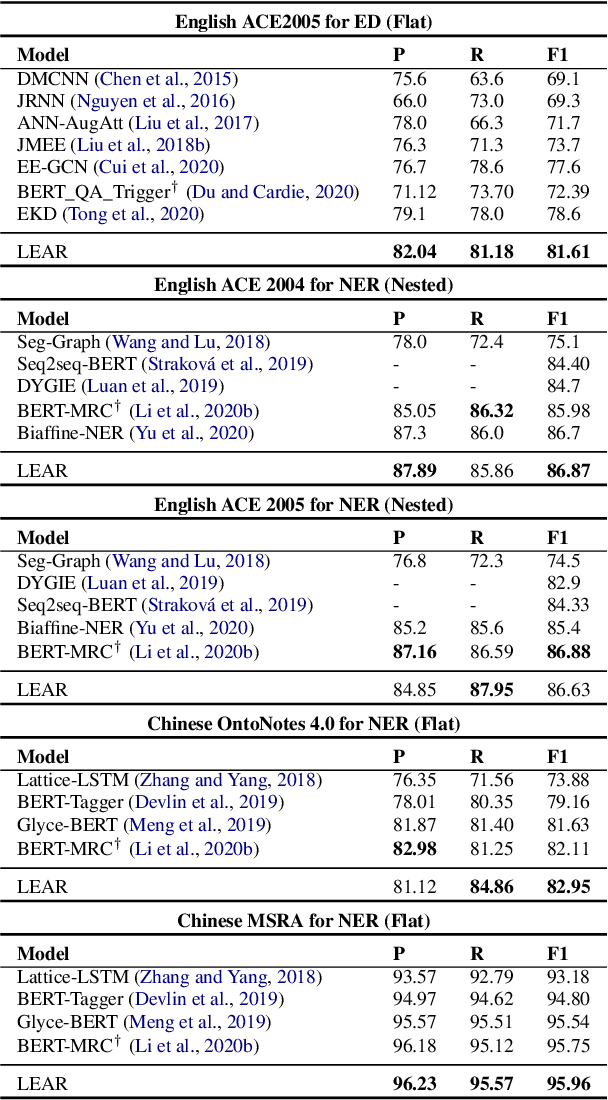
Span extraction, aiming to extract text spans (such as words or phrases) from plain texts, is a fundamental process in Information Extraction. Recent works introduce the label knowledge to enhance the text representation by formalizing the span extraction task into a question answering problem (QA Formalization), which achieves state-of-the-art performance. However, QA Formalization does not fully exploit the label knowledge and suffers from low efficiency in training/inference. To address those problems, we introduce a new paradigm to integrate label knowledge and further propose a novel model to explicitly and efficiently integrate label knowledge into text representations. Specifically, it encodes texts and label annotations independently and then integrates label knowledge into text representation with an elaborate-designed semantics fusion module. We conduct extensive experiments on three typical span extraction tasks: flat NER, nested NER, and event detection. The empirical results show that 1) our method achieves state-of-the-art performance on four benchmarks, and 2) reduces training time and inference time by 76% and 77% on average, respectively, compared with the QA Formalization paradigm. Our code and data are available at https://github.com/Akeepers/LEAR.
A Deep Hashing Learning Network
Jul 16, 2015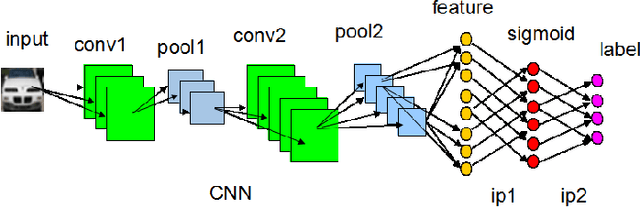
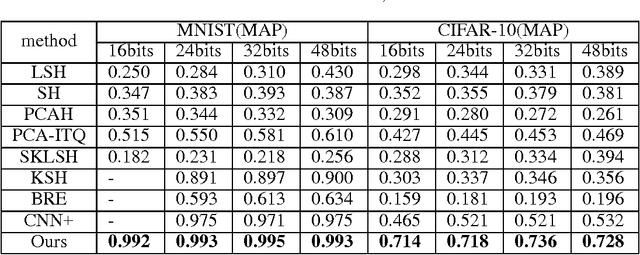
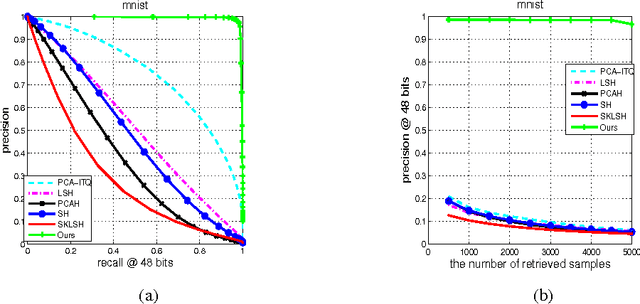
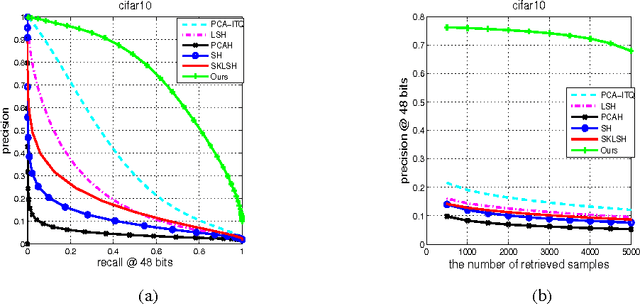
Hashing-based methods seek compact and efficient binary codes that preserve the neighborhood structure in the original data space. For most existing hashing methods, an image is first encoded as a vector of hand-crafted visual feature, followed by a hash projection and quantization step to get the compact binary vector. Most of the hand-crafted features just encode the low-level information of the input, the feature may not preserve the semantic similarities of images pairs. Meanwhile, the hashing function learning process is independent with the feature representation, so the feature may not be optimal for the hashing projection. In this paper, we propose a supervised hashing method based on a well designed deep convolutional neural network, which tries to learn hashing code and compact representations of data simultaneously. The proposed model learn the binary codes by adding a compact sigmoid layer before the loss layer. Experiments on several image data sets show that the proposed model outperforms other state-of-the-art methods.