 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Vision-Language Action-Incremental Policy Learning
Apr 22, 2025Recently, Transformer-based robotic manipulation methods utilize multi-view spatial representations and language instructions to learn robot motion trajectories by leveraging numerous robot demonstrations. However, the collection of robot data is extremely challenging, and existing methods lack the capability for continuous learning on new tasks with only a few demonstrations. In this paper, we formulate these challenges as the Few-Shot Action-Incremental Learning (FSAIL) task, and accordingly design a Task-prOmpt graPh evolutIon poliCy (TOPIC) to address these issues. Specifically, to address the data scarcity issue in robotic imitation learning, TOPIC learns Task-Specific Prompts (TSP) through the deep interaction of multi-modal information within few-shot demonstrations, thereby effectively extracting the task-specific discriminative information. On the other hand, to enhance the capability for continual learning on new tasks and mitigate the issue of catastrophic forgetting, TOPIC adopts a Continuous Evolution Strategy (CES). CES leverages the intrinsic relationships between tasks to construct a task relation graph, which effectively facilitates the adaptation of new tasks by reusing skills learned from previous tasks. TOPIC pioneers few-shot continual learning in the robotic manipulation task, and extensive experimental results demonstrate that TOPIC outperforms state-of-the-art baselines by over 26$\%$ in success rate, significantly enhancing the continual learning capabilities of existing Transformer-based policies.
Dynamic Degradation Decomposition Network for All-in-One Image Restoration
Feb 26, 2025Currently, restoring clean images from a variety of degradation types using a single model is still a challenging task. Existing all-in-one image restoration approaches struggle with addressing complex and ambiguously defined degradation types. In this paper, we introduce a dynamic degradation decomposition network for all-in-one image restoration, named D$^3$Net. D$^3$Net achieves degradation-adaptive image restoration with guided prompt through cross-domain interaction and dynamic degradation decomposition. Concretely, in D$^3$Net, the proposed Cross-Domain Degradation Analyzer (CDDA) engages in deep interaction between frequency domain degradation characteristics and spatial domain image features to identify and model variations of different degradation types on the image manifold, generating degradation correction prompt and strategy prompt, which guide the following decomposition process. Furthermore, the prompt-based Dynamic Decomposition Mechanism (DDM) for progressive degradation decomposition, that encourages the network to adaptively select restoration strategies utilizing the two-level prompt generated by CDDA. Thanks to the synergistic cooperation between CDDA and DDM, D$^3$Net achieves superior flexibility and scalability in handling unknown degradation, while effectively reducing unnecessary computational overhead. Extensive experiments on multiple image restoration tasks demonstrate that D$^3$Net significantly outperforms the state-of-the-art approaches, especially improving PSNR by 5.47dB and 3.30dB on the SOTS-Outdoor and GoPro datasets, respectively.
MuMath-Code: Combining Tool-Use Large Language Models with Multi-perspective Data Augmentation for Mathematical Reasoning
May 13, 2024The tool-use Large Language Models (LLMs) that integrate with external Python interpreters have significantly enhanced mathematical reasoning capabilities for open-source LLMs, while tool-free methods chose another track: augmenting math reasoning data. However, a great method to integrate the above two research paths and combine their advantages remains to be explored. In this work, we firstly include new math questions via multi-perspective data augmenting methods and then synthesize code-nested solutions to them. The open LLMs (i.e., Llama-2) are finetuned on the augmented dataset to get the resulting models, MuMath-Code ($\mu$-Math-Code). During the inference phase, our MuMath-Code generates code and interacts with the external python interpreter to get the execution results. Therefore, MuMath-Code leverages the advantages of both the external tool and data augmentation. To fully leverage the advantages of our augmented data, we propose a two-stage training strategy: In Stage-1, we finetune Llama-2 on pure CoT data to get an intermediate model, which then is trained on the code-nested data in Stage-2 to get the resulting MuMath-Code. Our MuMath-Code-7B achieves 83.8 on GSM8K and 52.4 on MATH, while MuMath-Code-70B model achieves new state-of-the-art performance among open methods -- achieving 90.7% on GSM8K and 55.1% on MATH. Extensive experiments validate the combination of tool use and data augmentation, as well as our two-stage training strategy. We release the proposed dataset along with the associated code for public use.
Hybrid quantum-classical convolutional neural network for phytoplankton classification
Mar 07, 2023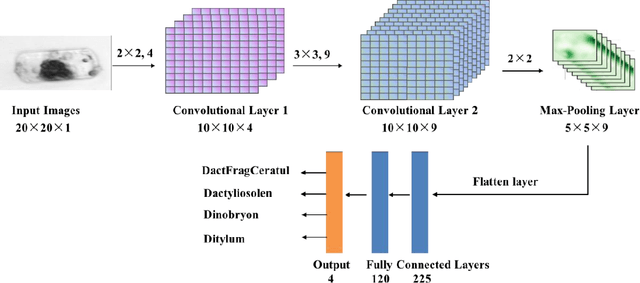

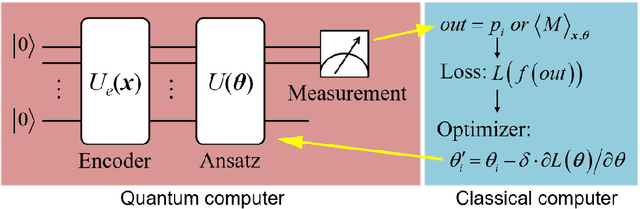
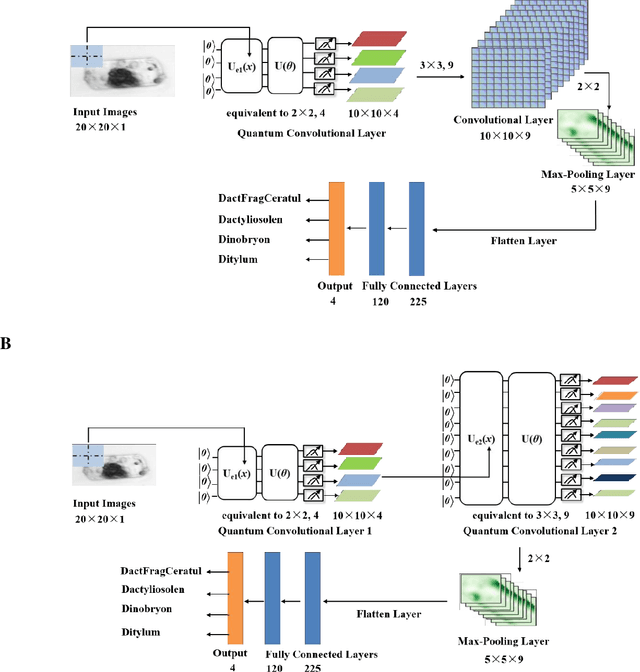
The taxonomic composition and abundance of phytoplankton, having direct impact on marine ecosystem dynamic and global environment change, are listed as essential ocean variables. Phytoplankton classification is very crucial for Phytoplankton analysis, but it is very difficult because of the huge amount and tiny volume of Phytoplankton. Machine learning is the principle way of performing phytoplankton image classification automatically. When carrying out large-scale research on the marine phytoplankton, the volume of data increases overwhelmingly and more powerful computational resources are required for the success of machine learning algorithms. Recently, quantum machine learning has emerged as the potential solution for large-scale data processing by harnessing the exponentially computational power of quantum computer. Here, for the first time, we demonstrate the feasibility of quantum deep neural networks for phytoplankton classification. Hybrid quantum-classical convolutional and residual neural networks are developed based on the classical architectures. These models make a proper balance between the limited function of the current quantum devices and the large size of phytoplankton images, which make it possible to perform phytoplankton classification on the near-term quantum computers. Better performance is obtained by the quantum-enhanced models against the classical counterparts. In particular, quantum models converge much faster than classical ones. The present quantum models are versatile, and can be applied for various tasks of image classification in the field of marine science.
Quantum Recurrent Neural Networks for Sequential Learning
Feb 07, 2023



Quantum neural network (QNN) is one of the promising directions where the near-term noisy intermediate-scale quantum (NISQ) devices could find advantageous applications against classical resources. Recurrent neural networks are the most fundamental networks for sequential learning, but up to now there is still a lack of canonical model of quantum recurrent neural network (QRNN), which certainly restricts the research in the field of quantum deep learning. In the present work, we propose a new kind of QRNN which would be a good candidate as the canonical QRNN model, where, the quantum recurrent blocks (QRBs) are constructed in the hardware-efficient way, and the QRNN is built by stacking the QRBs in a staggered way that can greatly reduce the algorithm's requirement with regard to the coherent time of quantum devices. That is, our QRNN is much more accessible on NISQ devices. Furthermore, the performance of the present QRNN model is verified concretely using three different kinds of classical sequential data, i.e., meteorological indicators, stock price, and text categorization. The numerical experiments show that our QRNN achieves much better performance in prediction (classification) accuracy against the classical RNN and state-of-the-art QNN models for sequential learning, and can predict the changing details of temporal sequence data. The practical circuit structure and superior performance indicate that the present QRNN is a promising learning model to find quantum advantageous applications in the near term.
Progressively Unfreezing Perceptual GAN
Jun 18, 2020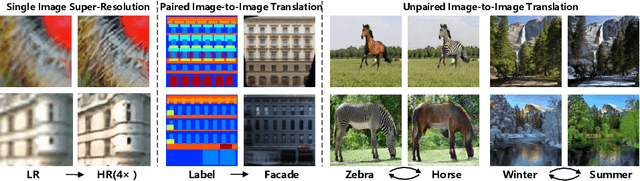
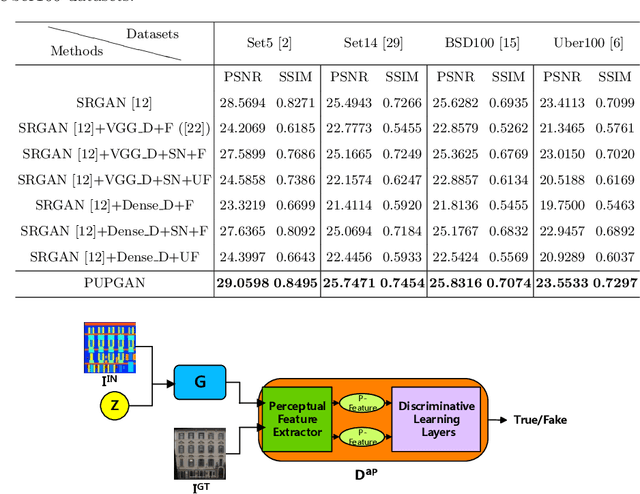
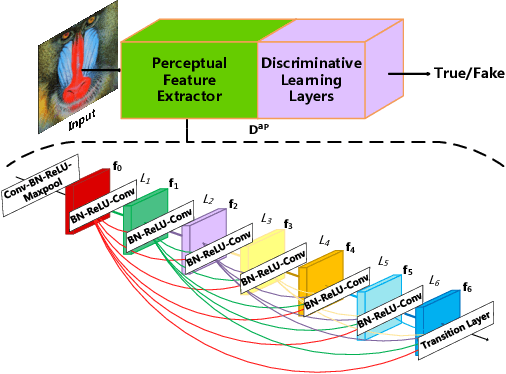
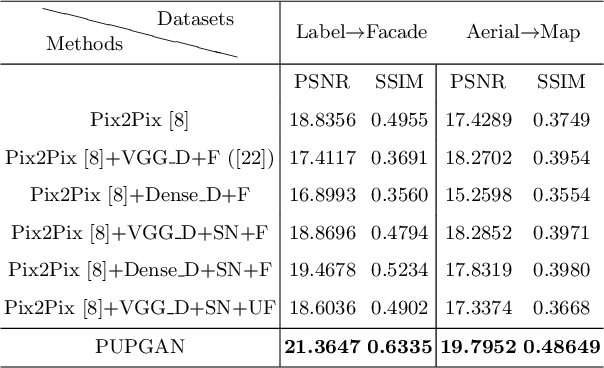
Generative adversarial networks (GANs) are widely used in image generation tasks, yet the generated images are usually lack of texture details. In this paper, we propose a general framework, called Progressively Unfreezing Perceptual GAN (PUPGAN), which can generate images with fine texture details. Particularly, we propose an adaptive perceptual discriminator with a pre-trained perceptual feature extractor, which can efficiently measure the discrepancy between multi-level features of the generated and real images. In addition, we propose a progressively unfreezing scheme for the adaptive perceptual discriminator, which ensures a smooth transfer process from a large scale classification task to a specified image generation task. The qualitative and quantitative experiments with comparison to the classical baselines on three image generation tasks, i.e. single image super-resolution, paired image-to-image translation and unpaired image-to-image translation demonstrate the superiority of PUPGAN over the compared approaches.
SymmetricNet: A mesoscale eddy detection method based on multivariate fusion data
Sep 30, 2019
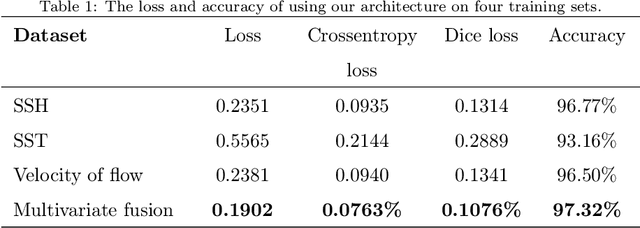


Mesoscale eddies play a significant role in marine energy transport, marine biological environment and marine climate. Due to their huge impact on the ocean, mesoscale eddy detection has become a hot research area in recent years. Therefore, more and more people are entering the field of mesoscale eddy detection. However, the existing detection methods mainly based on traditional detection methods typically only use Sea Surface Height (SSH) as a variable to detect, resulting in inaccurate performance. In this paper, we propose a mesoscale eddy detection method based on multivariate fusion data to solve this problem. We not only use the SSH variable, but also add the two variables: Sea Surface Temperature (SST) and velocity of flow, achieving a multivariate information fusion input. We design a novel symmetric network, which merges low-level feature maps from the downsampling pathway and high-level feature maps from the upsampling pathway by lateral connection. In addition, we apply dilated convolutions to network structure to increase the receptive field and obtain more contextual information in the case of constant parameter. In the end, we demonstrate the effectiveness of our method on dataset provided by us, achieving the test set performance of 97.06% , greatly improved the performance of previous methods of mesoscale eddy detection.
Weak Edge Identification Nets for Ocean Front Detection
Sep 17, 2019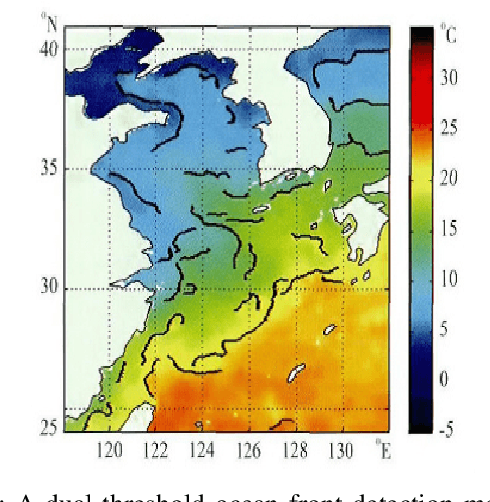
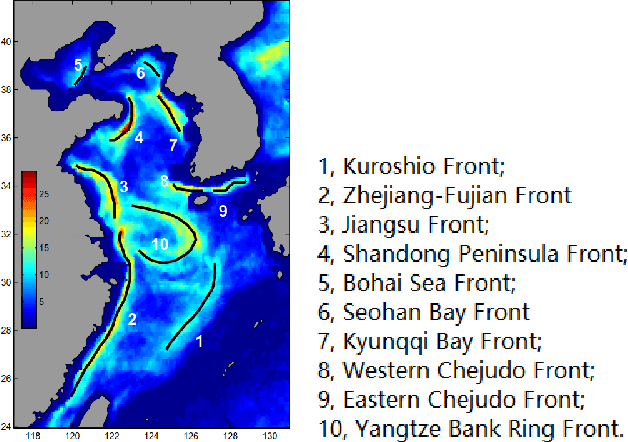
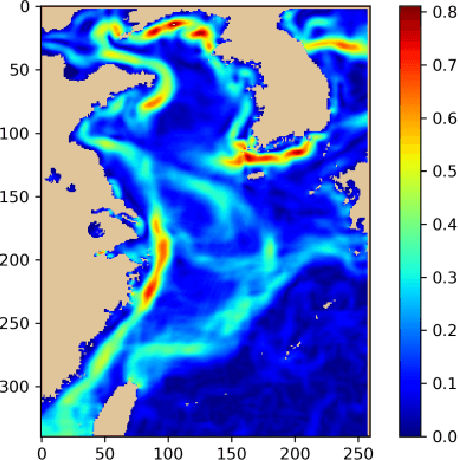
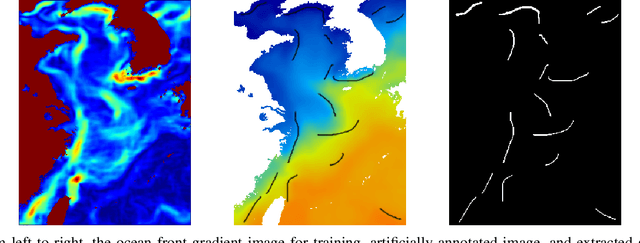
The ocean front has an important impact in many areas, it is meaningful to obtain accurate ocean front positioning, therefore, ocean front detection is a very important task. However, the traditional edge detection algorithm does not detect the weak edge information of the ocean front very well. In response to this problem, we collected relevant ocean front gradient images and found relevant experts to calibrate the ocean front data to obtain groundtruth, and proposed a weak edge identification nets(WEIN) for ocean front detection. Whether it is qualitative or quantitative, our methods perform best. The method uses a welltrained deep learning model to accurately extract the ocean front from the ocean front gradient image. The detection network is divided into multiple stages, and the final output is a multi-stage output image fusion. The method uses the stochastic gradient descent and the correlation loss function to obtain a good ocean front image output.
Student's t-Generative Adversarial Networks
Nov 06, 2018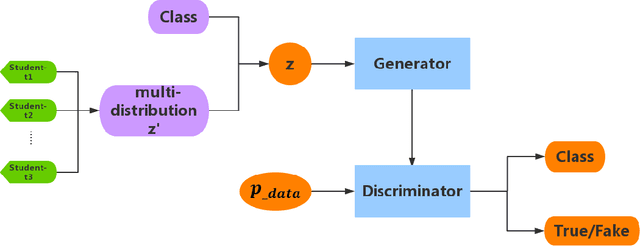
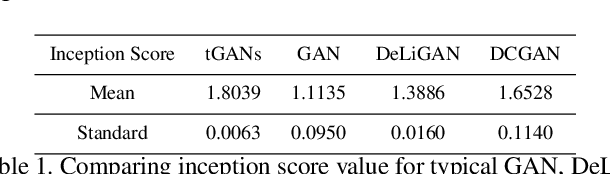

Generative Adversarial Networks (GANs) have a great performance in image generation, but they need a large scale of data to train the entire framework, and often result in nonsensical results. We propose a new method referring to conditional GAN, which equipments the latent noise with mixture of Student's t-distribution with attention mechanism in addition to class information. Student's t-distribution has long tails that can provide more diversity to the latent noise. Meanwhile, the discriminator in our model implements two tasks simultaneously, judging whether the images come from the true data distribution, and identifying the class of each generated images. The parameters of the mixture model can be learned along with those of GANs. Moreover, we mathematically prove that any multivariate Student's t-distribution can be obtained by a linear transformation of a normal multivariate Student's t-distribution. Experiments comparing the proposed method with typical GAN, DeliGAN and DCGAN indicate that, our method has a great performance on generating diverse and legible objects with limited data.
Structure Learning of Deep Neural Networks with Q-Learning
Oct 31, 2018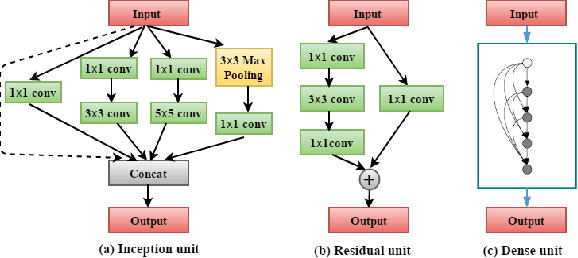



Recently, with convolutional neural networks gaining significant achievements in many challenging machine learning fields, hand-crafted neural networks no longer satisfy our requirements as designing a network will cost a lot, and automatically generating architectures has attracted increasingly more attention and focus. Some research on auto-generated networks has achieved promising results. However, they mainly aim at picking a series of single layers such as convolution or pooling layers one by one. There are many elegant and creative designs in the carefully hand-crafted neural networks, such as Inception-block in GoogLeNet, residual block in residual network and dense block in dense convolutional network. Based on reinforcement learning and taking advantages of the superiority of these networks, we propose a novel automatic process to design a multi-block neural network, whose architecture contains multiple types of blocks mentioned above, with the purpose to do structure learning of deep neural networks and explore the possibility whether different blocks can be composed together to form a well-behaved neural network. The optimal network is created by the Q-learning agent who is trained to sequentially pick different types of blocks. To verify the validity of our proposed method, we use the auto-generated multi-block neural network to conduct experiments on image benchmark datasets MNIST, SVHN and CIFAR-10 image classification task with restricted computational resources. The results demonstrate that our method is very effective, achieving comparable or better performance than hand-crafted networks and advanced auto-generated neural networks.