 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models
Jan 13, 2026Large Language Models (LLMs) have shown strong capabilities across many domains, yet their evaluation in financial quantitative tasks remains fragmented and mostly limited to knowledge-centric question answering. We introduce QuantEval, a benchmark that evaluates LLMs across three essential dimensions of quantitative finance: knowledge-based QA, quantitative mathematical reasoning, and quantitative strategy coding. Unlike prior financial benchmarks, QuantEval integrates a CTA-style backtesting framework that executes model-generated strategies and evaluates them using financial performance metrics, enabling a more realistic assessment of quantitative coding ability. We evaluate some state-of-the-art open-source and proprietary LLMs and observe substantial gaps to human experts, particularly in reasoning and strategy coding. Finally, we conduct large-scale supervised fine-tuning and reinforcement learning experiments on domain-aligned data, demonstrating consistent improvements. We hope QuantEval will facilitate research on LLMs' quantitative finance capabilities and accelerate their practical adoption in real-world trading workflows. We additionally release the full deterministic backtesting configuration (asset universe, cost model, and metric definitions) to ensure strict reproducibility.
Codebook-Centric Deep Hashing: End-to-End Joint Learning of Semantic Hash Centers and Neural Hash Function
Nov 15, 2025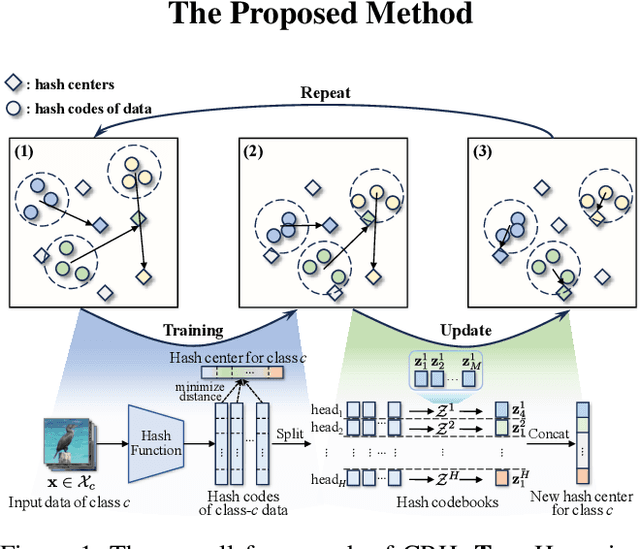
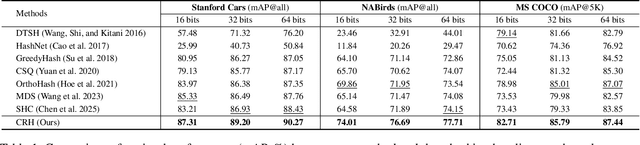

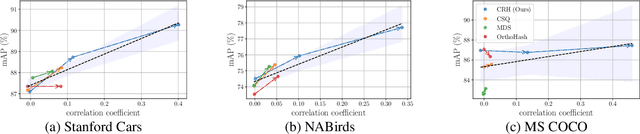
Hash center-based deep hashing methods improve upon pairwise or triplet-based approaches by assigning fixed hash centers to each class as learning targets, thereby avoiding the inefficiency of local similarity optimization. However, random center initialization often disregards inter-class semantic relationships. While existing two-stage methods mitigate this by first refining hash centers with semantics and then training the hash function, they introduce additional complexity, computational overhead, and suboptimal performance due to stage-wise discrepancies. To address these limitations, we propose $\textbf{Center-Reassigned Hashing (CRH)}$, an end-to-end framework that $\textbf{dynamically reassigns hash centers}$ from a preset codebook while jointly optimizing the hash function. Unlike previous methods, CRH adapts hash centers to the data distribution $\textbf{without explicit center optimization phases}$, enabling seamless integration of semantic relationships into the learning process. Furthermore, $\textbf{a multi-head mechanism}$ enhances the representational capacity of hash centers, capturing richer semantic structures. Extensive experiments on three benchmarks demonstrate that CRH learns semantically meaningful hash centers and outperforms state-of-the-art deep hashing methods in retrieval tasks.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
MuMath-Code: Combining Tool-Use Large Language Models with Multi-perspective Data Augmentation for Mathematical Reasoning
May 13, 2024The tool-use Large Language Models (LLMs) that integrate with external Python interpreters have significantly enhanced mathematical reasoning capabilities for open-source LLMs, while tool-free methods chose another track: augmenting math reasoning data. However, a great method to integrate the above two research paths and combine their advantages remains to be explored. In this work, we firstly include new math questions via multi-perspective data augmenting methods and then synthesize code-nested solutions to them. The open LLMs (i.e., Llama-2) are finetuned on the augmented dataset to get the resulting models, MuMath-Code ($\mu$-Math-Code). During the inference phase, our MuMath-Code generates code and interacts with the external python interpreter to get the execution results. Therefore, MuMath-Code leverages the advantages of both the external tool and data augmentation. To fully leverage the advantages of our augmented data, we propose a two-stage training strategy: In Stage-1, we finetune Llama-2 on pure CoT data to get an intermediate model, which then is trained on the code-nested data in Stage-2 to get the resulting MuMath-Code. Our MuMath-Code-7B achieves 83.8 on GSM8K and 52.4 on MATH, while MuMath-Code-70B model achieves new state-of-the-art performance among open methods -- achieving 90.7% on GSM8K and 55.1% on MATH. Extensive experiments validate the combination of tool use and data augmentation, as well as our two-stage training strategy. We release the proposed dataset along with the associated code for public use.
High-Dimensional Yield Estimation using Shrinkage Deep Features and Maximization of Integral Entropy Reduction
Dec 05, 2022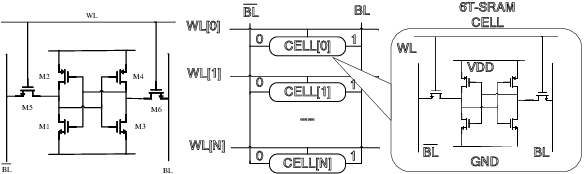
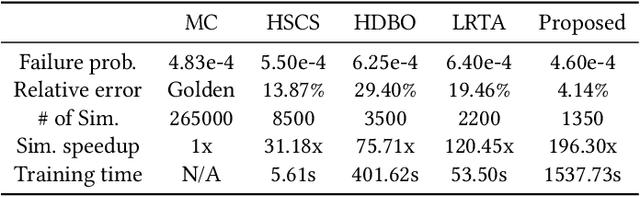
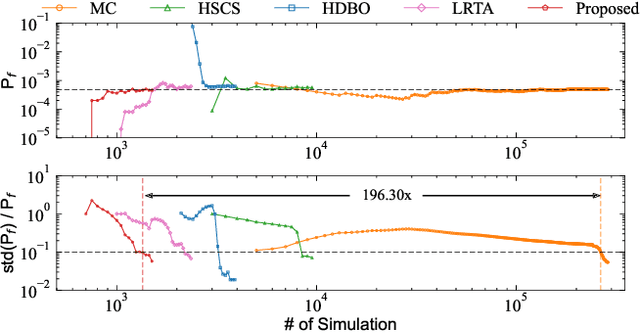
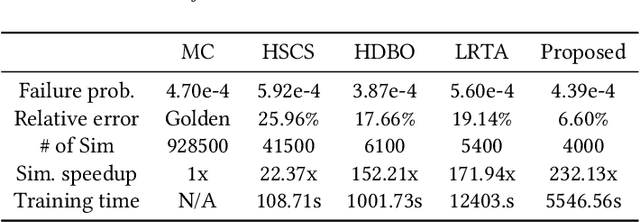
Despite the fast advances in high-sigma yield analysis with the help of machine learning techniques in the past decade, one of the main challenges, the curse of dimensionality, which is inevitable when dealing with modern large-scale circuits, remains unsolved. To resolve this challenge, we propose an absolute shrinkage deep kernel learning, ASDK, which automatically identifies the dominant process variation parameters in a nonlinear-correlated deep kernel and acts as a surrogate model to emulate the expensive SPICE simulation. To further improve the yield estimation efficiency, we propose a novel maximization of approximated entropy reduction for an efficient model update, which is also enhanced with parallel batch sampling for parallel computing, making it ready for practical deployment. Experiments on SRAM column circuits demonstrate the superiority of ASDK over the state-of-the-art (SOTA) approaches in terms of accuracy and efficiency with up to 10.3x speedup over SOTA methods.