 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDIQA: Unified Image Quality Assessment for Multi-dimensional Evaluation and Restoration
Aug 23, 2025



Recent advancements in image quality assessment (IQA), driven by sophisticated deep neural network designs, have significantly improved the ability to approach human perceptions. However, most existing methods are obsessed with fitting the overall score, neglecting the fact that humans typically evaluate image quality from different dimensions before arriving at an overall quality assessment. To overcome this problem, we propose a multi-dimensional image quality assessment (MDIQA) framework. Specifically, we model image quality across various perceptual dimensions, including five technical and four aesthetic dimensions, to capture the multifaceted nature of human visual perception within distinct branches. Each branch of our MDIQA is initially trained under the guidance of a separate dimension, and the respective features are then amalgamated to generate the final IQA score. Additionally, when the MDIQA model is ready, we can deploy it for a flexible training of image restoration (IR) models, enabling the restoration results to better align with varying user preferences through the adjustment of perceptual dimension weights. Extensive experiments demonstrate that our MDIQA achieves superior performance and can be effectively and flexibly applied to image restoration tasks. The code is available: https://github.com/YaoShunyu19/MDIQA.
Decoupled Visual Interpretation and Linguistic Reasoning for Math Problem Solving
May 23, 2025Current large vision-language models (LVLMs) typically employ a connector module to link visual features with text embeddings of large language models (LLMs) and use end-to-end training to achieve multi-modal understanding in a unified process. Well alignment needs high-quality pre-training data and a carefully designed training process. Current LVLMs face challenges when addressing complex vision-language reasoning tasks, with their reasoning capabilities notably lagging behind those of LLMs. This paper proposes a paradigm shift: instead of training end-to-end vision-language reasoning models, we advocate for developing a decoupled reasoning framework based on existing visual interpretation specialists and text-based reasoning LLMs. Our approach leverages (1) a dedicated vision-language model to transform the visual content of images into textual descriptions and (2) an LLM to perform reasoning according to the visual-derived text and the original question. This method presents a cost-efficient solution for multi-modal model development by optimizing existing models to work collaboratively, avoiding end-to-end development of vision-language models from scratch. By transforming images into language model-compatible text representations, it facilitates future low-cost and flexible upgrades to upcoming powerful LLMs. We introduce an outcome-rewarded joint-tuning strategy to optimize the cooperation between the visual interpretation and linguistic reasoning model. Evaluation results on vision-language benchmarks demonstrate that the decoupled reasoning framework outperforms recent LVLMs. Our approach yields particularly significant performance gains on visually intensive geometric mathematics problems. The code is available: https://github.com/guozix/DVLR.
Personalized Image Generation with Deep Generative Models: A Decade Survey
Feb 18, 2025



Recent advancements in generative models have significantly facilitated the development of personalized content creation. Given a small set of images with user-specific concept, personalized image generation allows to create images that incorporate the specified concept and adhere to provided text descriptions. Due to its wide applications in content creation, significant effort has been devoted to this field in recent years. Nonetheless, the technologies used for personalization have evolved alongside the development of generative models, with their distinct and interrelated components. In this survey, we present a comprehensive review of generalized personalized image generation across various generative models, including traditional GANs, contemporary text-to-image diffusion models, and emerging multi-model autoregressive models. We first define a unified framework that standardizes the personalization process across different generative models, encompassing three key components, i.e., inversion spaces, inversion methods, and personalization schemes. This unified framework offers a structured approach to dissecting and comparing personalization techniques across different generative architectures. Building upon this unified framework, we further provide an in-depth analysis of personalization techniques within each generative model, highlighting their unique contributions and innovations. Through comparative analysis, this survey elucidates the current landscape of personalized image generation, identifying commonalities and distinguishing features among existing methods. Finally, we discuss the open challenges in the field and propose potential directions for future research. We keep tracing related works at https://github.com/csyxwei/Awesome-Personalized-Image-Generation.
Explicit Relational Reasoning Network for Scene Text Detection
Dec 19, 2024
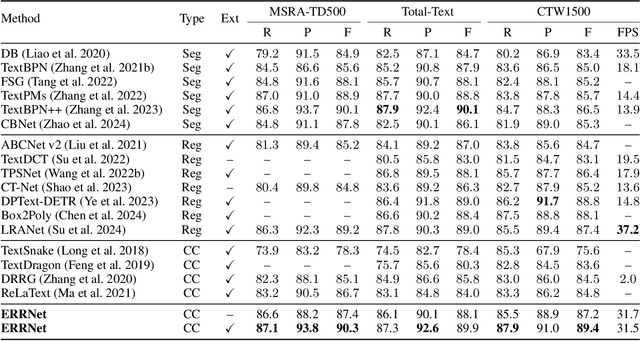

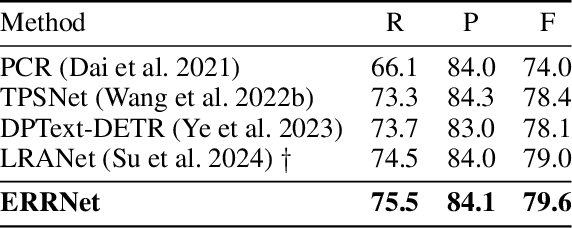
Connected component (CC) is a proper text shape representation that aligns with human reading intuition. However, CC-based text detection methods have recently faced a developmental bottleneck that their time-consuming post-processing is difficult to eliminate. To address this issue, we introduce an explicit relational reasoning network (ERRNet) to elegantly model the component relationships without post-processing. Concretely, we first represent each text instance as multiple ordered text components, and then treat these components as objects in sequential movement. In this way, scene text detection can be innovatively viewed as a tracking problem. From this perspective, we design an end-to-end tracking decoder to achieve a CC-based method dispensing with post-processing entirely. Additionally, we observe that there is an inconsistency between classification confidence and localization quality, so we propose a Polygon Monte-Carlo method to quickly and accurately evaluate the localization quality. Based on this, we introduce a position-supervised classification loss to guide the task-aligned learning of ERRNet. Experiments on challenging benchmarks demonstrate the effectiveness of our ERRNet. It consistently achieves state-of-the-art accuracy while holding highly competitive inference speed.
VitaGlyph: Vitalizing Artistic Typography with Flexible Dual-branch Diffusion Models
Oct 02, 2024



Artistic typography is a technique to visualize the meaning of input character in an imaginable and readable manner. With powerful text-to-image diffusion models, existing methods directly design the overall geometry and texture of input character, making it challenging to ensure both creativity and legibility. In this paper, we introduce a dual-branch and training-free method, namely VitaGlyph, enabling flexible artistic typography along with controllable geometry change to maintain the readability. The key insight of VitaGlyph is to treat input character as a scene composed of Subject and Surrounding, followed by rendering them under varying degrees of geometry transformation. The subject flexibly expresses the essential concept of input character, while the surrounding enriches relevant background without altering the shape. Specifically, we implement VitaGlyph through a three-phase framework: (i) Knowledge Acquisition leverages large language models to design text descriptions of subject and surrounding. (ii) Regional decomposition detects the part that most matches the subject description and divides input glyph image into subject and surrounding regions. (iii) Typography Stylization firstly refines the structure of subject region via Semantic Typography, and then separately renders the textures of Subject and Surrounding regions through Controllable Compositional Generation. Experimental results demonstrate that VitaGlyph not only achieves better artistry and readability, but also manages to depict multiple customize concepts, facilitating more creative and pleasing artistic typography generation. Our code will be made publicly at https://github.com/Carlofkl/VitaGlyph.
Two Optimizers Are Better Than One: LLM Catalyst for Enhancing Gradient-Based Optimization
May 31, 2024



Learning a skill generally relies on both practical experience by doer and insightful high-level guidance by instructor. Will this strategy also work well for solving complex non-convex optimization problems? Here, a common gradient-based optimizer acts like a disciplined doer, making locally optimal update at each step. Recent methods utilize large language models (LLMs) to optimize solutions for concrete problems by inferring from natural language instructions, akin to a high-level instructor. In this paper, we show that these two optimizers are complementary to each other, suggesting a collaborative optimization approach. The gradient-based optimizer and LLM-based optimizer are combined in an interleaved manner. We instruct LLMs using task descriptions and timely optimization trajectories recorded during gradient-based optimization. Inferred results from LLMs are used as restarting points for the next stage of gradient optimization. By leveraging both the locally rigorous gradient-based optimizer and the high-level deductive LLM-based optimizer, our combined optimization method consistently yields improvements over competitive baseline prompt tuning methods. Our results demonstrate the synergistic effect of conventional gradient-based optimization and the inference ability of LLMs. The code is released at https://github.com/guozix/LLM-catalyst.
MuMath-Code: Combining Tool-Use Large Language Models with Multi-perspective Data Augmentation for Mathematical Reasoning
May 13, 2024The tool-use Large Language Models (LLMs) that integrate with external Python interpreters have significantly enhanced mathematical reasoning capabilities for open-source LLMs, while tool-free methods chose another track: augmenting math reasoning data. However, a great method to integrate the above two research paths and combine their advantages remains to be explored. In this work, we firstly include new math questions via multi-perspective data augmenting methods and then synthesize code-nested solutions to them. The open LLMs (i.e., Llama-2) are finetuned on the augmented dataset to get the resulting models, MuMath-Code ($\mu$-Math-Code). During the inference phase, our MuMath-Code generates code and interacts with the external python interpreter to get the execution results. Therefore, MuMath-Code leverages the advantages of both the external tool and data augmentation. To fully leverage the advantages of our augmented data, we propose a two-stage training strategy: In Stage-1, we finetune Llama-2 on pure CoT data to get an intermediate model, which then is trained on the code-nested data in Stage-2 to get the resulting MuMath-Code. Our MuMath-Code-7B achieves 83.8 on GSM8K and 52.4 on MATH, while MuMath-Code-70B model achieves new state-of-the-art performance among open methods -- achieving 90.7% on GSM8K and 55.1% on MATH. Extensive experiments validate the combination of tool use and data augmentation, as well as our two-stage training strategy. We release the proposed dataset along with the associated code for public use.
MasterWeaver: Taming Editability and Identity for Personalized Text-to-Image Generation
May 10, 2024Text-to-image (T2I) diffusion models have shown significant success in personalized text-to-image generation, which aims to generate novel images with human identities indicated by the reference images. Despite promising identity fidelity has been achieved by several tuning-free methods, they usually suffer from overfitting issues. The learned identity tends to entangle with irrelevant information, resulting in unsatisfied text controllability, especially on faces. In this work, we present MasterWeaver, a test-time tuning-free method designed to generate personalized images with both faithful identity fidelity and flexible editability. Specifically, MasterWeaver adopts an encoder to extract identity features and steers the image generation through additional introduced cross attention. To improve editability while maintaining identity fidelity, we propose an editing direction loss for training, which aligns the editing directions of our MasterWeaver with those of the original T2I model. Additionally, a face-augmented dataset is constructed to facilitate disentangled identity learning, and further improve the editability. Extensive experiments demonstrate that our MasterWeaver can not only generate personalized images with faithful identity, but also exhibit superiority in text controllability. Our code will be publicly available at https://github.com/csyxwei/MasterWeaver.
HPNet: Dynamic Trajectory Forecasting with Historical Prediction Attention
Apr 11, 2024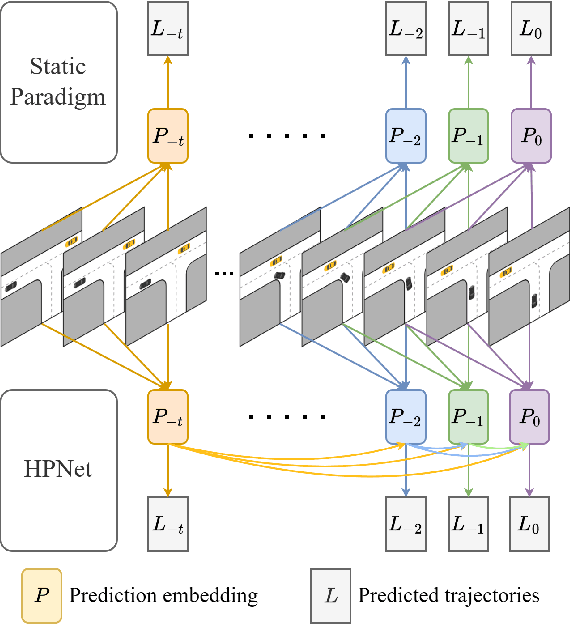
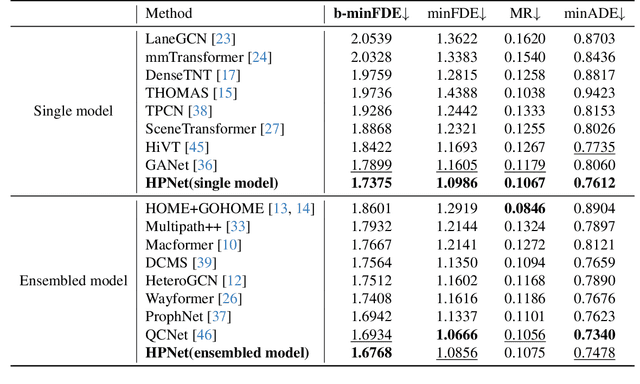
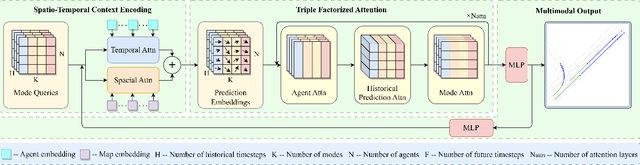
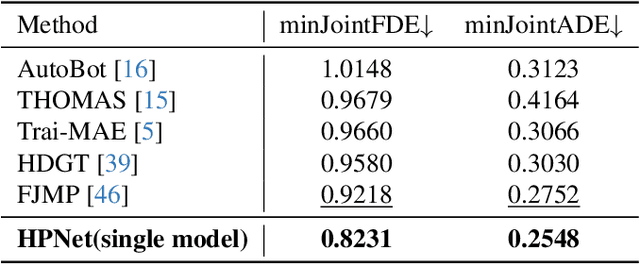
Predicting the trajectories of road agents is essential for autonomous driving systems. The recent mainstream methods follow a static paradigm, which predicts the future trajectory by using a fixed duration of historical frames. These methods make the predictions independently even at adjacent time steps, which leads to potential instability and temporal inconsistency. As successive time steps have largely overlapping historical frames, their forecasting should have intrinsic correlation, such as overlapping predicted trajectories should be consistent, or be different but share the same motion goal depending on the road situation. Motivated by this, in this work, we introduce HPNet, a novel dynamic trajectory forecasting method. Aiming for stable and accurate trajectory forecasting, our method leverages not only historical frames including maps and agent states, but also historical predictions. Specifically, we newly design a Historical Prediction Attention module to automatically encode the dynamic relationship between successive predictions. Besides, it also extends the attention range beyond the currently visible window benefitting from the use of historical predictions. The proposed Historical Prediction Attention together with the Agent Attention and Mode Attention is further formulated as the Triple Factorized Attention module, serving as the core design of HPNet.Experiments on the Argoverse and INTERACTION datasets show that HPNet achieves state-of-the-art performance, and generates accurate and stable future trajectories. Our code are available at https://github.com/XiaolongTang23/HPNet.
Black-Box Tuning of Vision-Language Models with Effective Gradient Approximation
Dec 26, 2023Parameter-efficient fine-tuning (PEFT) methods have provided an effective way for adapting large vision-language models to specific tasks or scenarios. Typically, they learn a very small scale of parameters for pre-trained models in a white-box formulation, which assumes model architectures to be known and parameters to be accessible. However, large models are often not open-source due to considerations of preventing abuse or commercial factors, hence posing a barrier to the deployment of white-box PEFT methods. To alleviate the dependence on model accessibility, we introduce collaborative black-box tuning (CBBT) for both textual prompt optimization and output feature adaptation for black-box models. Specifically, considering that the backpropagation gradients are blocked, we approximate the gradients of textual prompts by analyzing the predictions with perturbed prompts. Secondly, a lightweight adapter is deployed over the output feature of the inaccessible model, further facilitating the model adaptation process. Empowered with these designs, our CBBT is extensively evaluated on eleven downstream benchmarks and achieves remarkable improvements compared to existing black-box VL adaptation methods. Code is released at https://github.com/guozix/cbbt.