 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientMT: Efficient Temporal Adaptation for Motion Transfer in Text-to-Video Diffusion Models
Mar 26, 2025



The progress on generative models has led to significant advances on text-to-video (T2V) generation, yet the motion controllability of generated videos remains limited. Existing motion transfer methods explored the motion representations of reference videos to guide generation. Nevertheless, these methods typically rely on sample-specific optimization strategy, resulting in high computational burdens. In this paper, we propose EfficientMT, a novel and efficient end-to-end framework for video motion transfer. By leveraging a small set of synthetic paired motion transfer samples, EfficientMT effectively adapts a pretrained T2V model into a general motion transfer framework that can accurately capture and reproduce diverse motion patterns. Specifically, we repurpose the backbone of the T2V model to extract temporal information from reference videos, and further propose a scaler module to distill motion-related information. Subsequently, we introduce a temporal integration mechanism that seamlessly incorporates reference motion features into the video generation process. After training on our self-collected synthetic paired samples, EfficientMT enables general video motion transfer without requiring test-time optimization. Extensive experiments demonstrate that our EfficientMT outperforms existing methods in efficiency while maintaining flexible motion controllability. Our code will be available https://github.com/PrototypeNx/EfficientMT.
Decoupled Textual Embeddings for Customized Image Generation
Dec 19, 2023
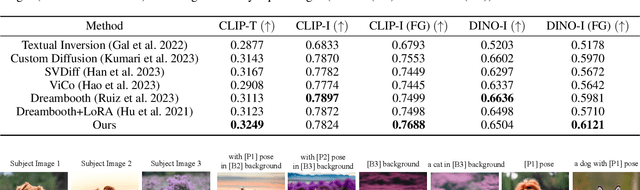
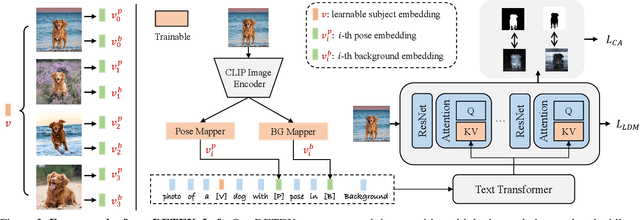
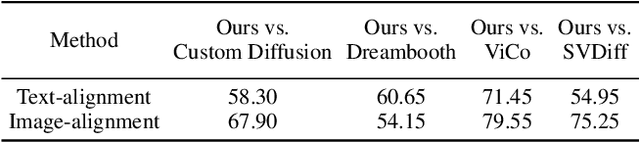
Customized text-to-image generation, which aims to learn user-specified concepts with a few images, has drawn significant attention recently. However, existing methods usually suffer from overfitting issues and entangle the subject-unrelated information (e.g., background and pose) with the learned concept, limiting the potential to compose concept into new scenes. To address these issues, we propose the DETEX, a novel approach that learns the disentangled concept embedding for flexible customized text-to-image generation. Unlike conventional methods that learn a single concept embedding from the given images, our DETEX represents each image using multiple word embeddings during training, i.e., a learnable image-shared subject embedding and several image-specific subject-unrelated embeddings. To decouple irrelevant attributes (i.e., background and pose) from the subject embedding, we further present several attribute mappers that encode each image as several image-specific subject-unrelated embeddings. To encourage these unrelated embeddings to capture the irrelevant information, we incorporate them with corresponding attribute words and propose a joint training strategy to facilitate the disentanglement. During inference, we only use the subject embedding for image generation, while selectively using image-specific embeddings to retain image-specified attributes. Extensive experiments demonstrate that the subject embedding obtained by our method can faithfully represent the target concept, while showing superior editability compared to the state-of-the-art methods. Our code will be made published available.