 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Spectral Rectification: Test-Time Defense towards Zero-shot Adversarial Robustness of CLIP
Jan 27, 2026Vision-language models (VLMs) such as CLIP have demonstrated remarkable zero-shot generalization, yet remain highly vulnerable to adversarial examples (AEs). While test-time defenses are promising, existing methods fail to provide sufficient robustness against strong attacks and are often hampered by high inference latency and task-specific applicability. To address these limitations, we start by investigating the intrinsic properties of AEs, which reveals that AEs exhibit severe feature inconsistency under progressive frequency attenuation. We further attribute this to the model's inherent spectral bias. Leveraging this insight, we propose an efficient test-time defense named Contrastive Spectral Rectification (CSR). CSR optimizes a rectification perturbation to realign the input with the natural manifold under a spectral-guided contrastive objective, which is applied input-adaptively. Extensive experiments across 16 classification benchmarks demonstrate that CSR outperforms the SOTA by an average of 18.1% against strong AutoAttack with modest inference overhead. Furthermore, CSR exhibits broad applicability across diverse visual tasks. Code is available at https://github.com/Summu77/CSR.
T2VAttack: Adversarial Attack on Text-to-Video Diffusion Models
Dec 30, 2025The rapid evolution of Text-to-Video (T2V) diffusion models has driven remarkable advancements in generating high-quality, temporally coherent videos from natural language descriptions. Despite these achievements, their vulnerability to adversarial attacks remains largely unexplored. In this paper, we introduce T2VAttack, a comprehensive study of adversarial attacks on T2V diffusion models from both semantic and temporal perspectives. Considering the inherently dynamic nature of video data, we propose two distinct attack objectives: a semantic objective to evaluate video-text alignment and a temporal objective to assess the temporal dynamics. To achieve an effective and efficient attack process, we propose two adversarial attack methods: (i) T2VAttack-S, which identifies semantically or temporally critical words in prompts and replaces them with synonyms via greedy search, and (ii) T2VAttack-I, which iteratively inserts optimized words with minimal perturbation to the prompt. By combining these objectives and strategies, we conduct a comprehensive evaluation on the adversarial robustness of several state-of-the-art T2V models, including ModelScope, CogVideoX, Open-Sora, and HunyuanVideo. Our experiments reveal that even minor prompt modifications, such as the substitution or insertion of a single word, can cause substantial degradation in semantic fidelity and temporal dynamics, highlighting critical vulnerabilities in current T2V diffusion models.
Towards Transferable Defense Against Malicious Image Edits
Dec 16, 2025Recent approaches employing imperceptible perturbations in input images have demonstrated promising potential to counter malicious manipulations in diffusion-based image editing systems. However, existing methods suffer from limited transferability in cross-model evaluations. To address this, we propose Transferable Defense Against Malicious Image Edits (TDAE), a novel bimodal framework that enhances image immunity against malicious edits through coordinated image-text optimization. Specifically, at the visual defense level, we introduce FlatGrad Defense Mechanism (FDM), which incorporates gradient regularization into the adversarial objective. By explicitly steering the perturbations toward flat minima, FDM amplifies immune robustness against unseen editing models. For textual enhancement protection, we propose an adversarial optimization paradigm named Dynamic Prompt Defense (DPD), which periodically refines text embeddings to align the editing outcomes of immunized images with those of the original images, then updates the images under optimized embeddings. Through iterative adversarial updates to diverse embeddings, DPD enforces the generation of immunized images that seek a broader set of immunity-enhancing features, thereby achieving cross-model transferability. Extensive experimental results demonstrate that our TDAE achieves state-of-the-art performance in mitigating malicious edits under both intra- and cross-model evaluations.
Dual Attention Guided Defense Against Malicious Edits
Dec 16, 2025Recent progress in text-to-image diffusion models has transformed image editing via text prompts, yet this also introduces significant ethical challenges from potential misuse in creating deceptive or harmful content. While current defenses seek to mitigate this risk by embedding imperceptible perturbations, their effectiveness is limited against malicious tampering. To address this issue, we propose a Dual Attention-Guided Noise Perturbation (DANP) immunization method that adds imperceptible perturbations to disrupt the model's semantic understanding and generation process. DANP functions over multiple timesteps to manipulate both cross-attention maps and the noise prediction process, using a dynamic threshold to generate masks that identify text-relevant and irrelevant regions. It then reduces attention in relevant areas while increasing it in irrelevant ones, thereby misguides the edit towards incorrect regions and preserves the intended targets. Additionally, our method maximizes the discrepancy between the injected noise and the model's predicted noise to further interfere with the generation. By targeting both attention and noise prediction mechanisms, DANP exhibits impressive immunity against malicious edits, and extensive experiments confirm that our method achieves state-of-the-art performance.
Semantic Mismatch and Perceptual Degradation: A New Perspective on Image Editing Immunity
Dec 16, 2025



Text-guided image editing via diffusion models, while powerful, raises significant concerns about misuse, motivating efforts to immunize images against unauthorized edits using imperceptible perturbations. Prevailing metrics for evaluating immunization success typically rely on measuring the visual dissimilarity between the output generated from a protected image and a reference output generated from the unprotected original. This approach fundamentally overlooks the core requirement of image immunization, which is to disrupt semantic alignment with attacker intent, regardless of deviation from any specific output. We argue that immunization success should instead be defined by the edited output either semantically mismatching the prompt or suffering substantial perceptual degradations, both of which thwart malicious intent. To operationalize this principle, we propose Synergistic Intermediate Feature Manipulation (SIFM), a method that strategically perturbs intermediate diffusion features through dual synergistic objectives: (1) maximizing feature divergence from the original edit trajectory to disrupt semantic alignment with the expected edit, and (2) minimizing feature norms to induce perceptual degradations. Furthermore, we introduce the Immunization Success Rate (ISR), a novel metric designed to rigorously quantify true immunization efficacy for the first time. ISR quantifies the proportion of edits where immunization induces either semantic failure relative to the prompt or significant perceptual degradations, assessed via Multimodal Large Language Models (MLLMs). Extensive experiments show our SIFM achieves the state-of-the-art performance for safeguarding visual content against malicious diffusion-based manipulation.
VisKnow: Constructing Visual Knowledge Base for Object Understanding
Dec 09, 2025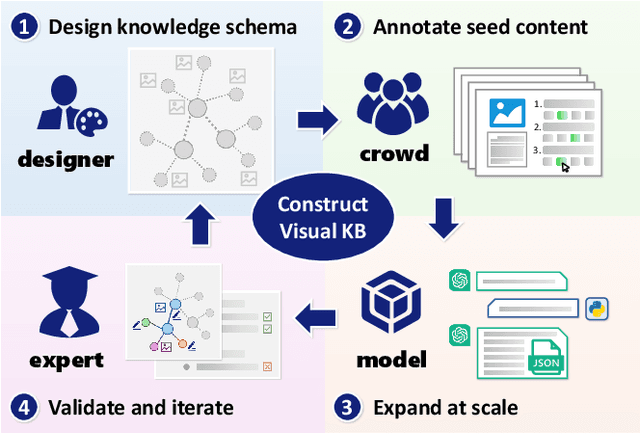



Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at https://vipl-vsu.github.io/VisKnow.
VOPE: Revisiting Hallucination of Vision-Language Models in Voluntary Imagination Task
Nov 17, 2025Most research on hallucinations in Large Vision-Language Models (LVLMs) focuses on factual description tasks that prohibit any output absent from the image. However, little attention has been paid to hallucinations in voluntary imagination tasks, e.g., story writing, where the models are expected to generate novel content beyond the given image. In these tasks, it is inappropriate to simply regard such imagined novel content as hallucinations. To address this limitation, we introduce Voluntary-imagined Object Presence Evaluation (VOPE)-a novel method to assess LVLMs' hallucinations in voluntary imagination tasks via presence evaluation. Specifically, VOPE poses recheck-based questions to evaluate how an LVLM interprets the presence of the imagined objects in its own response. The consistency between the model's interpretation and the object's presence in the image is then used to determine whether the model hallucinates when generating the response. We apply VOPE to several mainstream LVLMs and hallucination mitigation methods, revealing two key findings: (1) most LVLMs hallucinate heavily during voluntary imagination, and their performance in presence evaluation is notably poor on imagined objects; (2) existing hallucination mitigation methods show limited effect in voluntary imagination tasks, making this an important direction for future research.
GLip: A Global-Local Integrated Progressive Framework for Robust Visual Speech Recognition
Sep 19, 2025Visual speech recognition (VSR), also known as lip reading, is the task of recognizing speech from silent video. Despite significant advancements in VSR over recent decades, most existing methods pay limited attention to real-world visual challenges such as illumination variations, occlusions, blurring, and pose changes. To address these challenges, we propose GLip, a Global-Local Integrated Progressive framework designed for robust VSR. GLip is built upon two key insights: (i) learning an initial \textit{coarse} alignment between visual features across varying conditions and corresponding speech content facilitates the subsequent learning of \textit{precise} visual-to-speech mappings in challenging environments; (ii) under adverse conditions, certain local regions (e.g., non-occluded areas) often exhibit more discriminative cues for lip reading than global features. To this end, GLip introduces a dual-path feature extraction architecture that integrates both global and local features within a two-stage progressive learning framework. In the first stage, the model learns to align both global and local visual features with corresponding acoustic speech units using easily accessible audio-visual data, establishing a coarse yet semantically robust foundation. In the second stage, we introduce a Contextual Enhancement Module (CEM) to dynamically integrate local features with relevant global context across both spatial and temporal dimensions, refining the coarse representations into precise visual-speech mappings. Our framework uniquely exploits discriminative local regions through a progressive learning strategy, demonstrating enhanced robustness against various visual challenges and consistently outperforming existing methods on the LRS2 and LRS3 benchmarks. We further validate its effectiveness on a newly introduced challenging Mandarin dataset.
MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
Jun 17, 2025Large multimodal Mixture-of-Experts (MoEs) effectively scale the model size to boost performance while maintaining fixed active parameters. However, previous works primarily utilized full-precision experts during sparse up-cycling. Despite they show superior performance on end tasks, the large amount of experts introduces higher memory footprint, which poses significant challenges for the deployment on edge devices. In this work, we propose MoTE, a scalable and memory-efficient approach to train Mixture-of-Ternary-Experts models from dense checkpoint. Instead of training fewer high-precision experts, we propose to train more low-precision experts during up-cycling. Specifically, we use the pre-trained FFN as a shared expert and train ternary routed experts with parameters in {-1, 0, 1}. Extensive experiments show that our approach has promising scaling trend along model size. MoTE achieves comparable performance to full-precision baseline MoE-LLaVA while offering lower memory footprint. Furthermore, our approach is compatible with post-training quantization methods and the advantage further amplifies when memory-constraint goes lower. Given the same amount of expert memory footprint of 3.4GB and combined with post-training quantization, MoTE outperforms MoE-LLaVA by a gain of 4.3% average accuracy on end tasks, demonstrating its effectiveness and potential for memory-constrained devices.
BitVLA: 1-bit Vision-Language-Action Models for Robotics Manipulation
Jun 09, 2025Vision-Language-Action (VLA) models have shown impressive capabilities across a wide range of robotics manipulation tasks. However, their growing model size poses significant challenges for deployment on resource-constrained robotic systems. While 1-bit pretraining has proven effective for enhancing the inference efficiency of large language models with minimal performance loss, its application to VLA models remains underexplored. In this work, we present BitVLA, the first 1-bit VLA model for robotics manipulation, in which every parameter is ternary, i.e., {-1, 0, 1}. To further reduce the memory footprint of the vision encoder, we propose the distillation-aware training strategy that compresses the full-precision encoder to 1.58-bit weights. During this process, a full-precision encoder serves as a teacher model to better align latent representations. Despite the lack of large-scale robotics pretraining, BitVLA achieves performance comparable to the state-of-the-art model OpenVLA-OFT with 4-bit post-training quantization on the LIBERO benchmark, while consuming only 29.8% of the memory. These results highlight BitVLA's promise for deployment on memory-constrained edge devices. We release the code and model weights in https://github.com/ustcwhy/BitVLA.