 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSI: One-step Inversion Excels in Extracting Diffusion Watermarks
Feb 10, 2026Watermarking is an important mechanism for provenance and copyright protection of diffusion-generated images. Training-free methods, exemplified by Gaussian Shading, embed watermarks into the initial noise of diffusion models with negligible impact on the quality of generated images. However, extracting this type of watermark typically requires multi-step diffusion inversion to obtain precise initial noise, which is computationally expensive and time-consuming. To address this issue, we propose One-step Inversion (OSI), a significantly faster and more accurate method for extracting Gaussian Shading style watermarks. OSI reformulates watermark extraction as a learnable sign classification problem, which eliminates the need for precise regression of the initial noise. Then, we initialize the OSI model from the diffusion backbone and finetune it on synthesized noise-image pairs with a sign classification objective. In this manner, the OSI model is able to accomplish the watermark extraction efficiently in only one step. Our OSI substantially outperforms the multi-step diffusion inversion method: it is 20x faster, achieves higher extraction accuracy, and doubles the watermark payload capacity. Extensive experiments across diverse schedulers, diffusion backbones, and cryptographic schemes consistently show improvements, demonstrating the generality of our OSI framework.
Jodi: Unification of Visual Generation and Understanding via Joint Modeling
May 25, 2025Visual generation and understanding are two deeply interconnected aspects of human intelligence, yet they have been traditionally treated as separate tasks in machine learning. In this paper, we propose Jodi, a diffusion framework that unifies visual generation and understanding by jointly modeling the image domain and multiple label domains. Specifically, Jodi is built upon a linear diffusion transformer along with a role switch mechanism, which enables it to perform three particular types of tasks: (1) joint generation, where the model simultaneously generates images and multiple labels; (2) controllable generation, where images are generated conditioned on any combination of labels; and (3) image perception, where multiple labels can be predicted at once from a given image. Furthermore, we present the Joint-1.6M dataset, which contains 200,000 high-quality images collected from public sources, automatic labels for 7 visual domains, and LLM-generated captions. Extensive experiments demonstrate that Jodi excels in both generation and understanding tasks and exhibits strong extensibility to a wider range of visual domains. Code is available at https://github.com/VIPL-GENUN/Jodi.
CtrLoRA: An Extensible and Efficient Framework for Controllable Image Generation
Oct 12, 2024Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. Codes and model weights will be released at https://github.com/xyfJASON/ctrlora.
StylizedGS: Controllable Stylization for 3D Gaussian Splatting
Apr 08, 2024
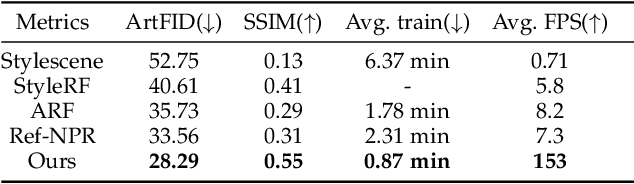
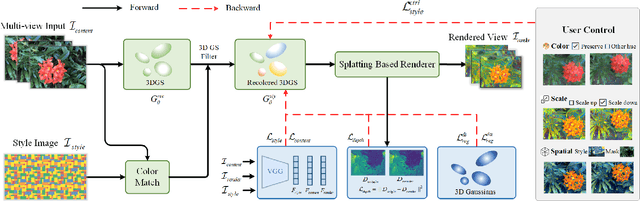

With the rapid development of XR, 3D generation and editing are becoming more and more important, among which, stylization is an important tool of 3D appearance editing. It can achieve consistent 3D artistic stylization given a single reference style image and thus is a user-friendly editing way. However, recent NeRF-based 3D stylization methods face efficiency issues that affect the actual user experience and the implicit nature limits its ability to transfer the geometric pattern styles. Additionally, the ability for artists to exert flexible control over stylized scenes is considered highly desirable, fostering an environment conducive to creative exploration. In this paper, we introduce StylizedGS, a 3D neural style transfer framework with adaptable control over perceptual factors based on 3D Gaussian Splatting (3DGS) representation. The 3DGS brings the benefits of high efficiency. We propose a GS filter to eliminate floaters in the reconstruction which affects the stylization effects before stylization. Then the nearest neighbor-based style loss is introduced to achieve stylization by fine-tuning the geometry and color parameters of 3DGS, while a depth preservation loss with other regularizations is proposed to prevent the tampering of geometry content. Moreover, facilitated by specially designed losses, StylizedGS enables users to control color, stylized scale and regions during the stylization to possess customized capabilities. Our method can attain high-quality stylization results characterized by faithful brushstrokes and geometric consistency with flexible controls. Extensive experiments across various scenes and styles demonstrate the effectiveness and efficiency of our method concerning both stylization quality and inference FPS.
Multimodal deep representation learning for quantum cross-platform verification
Nov 07, 2023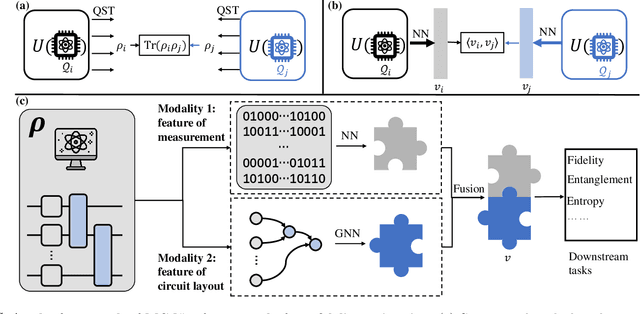
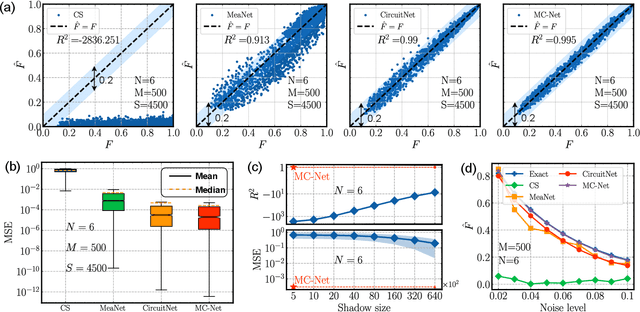
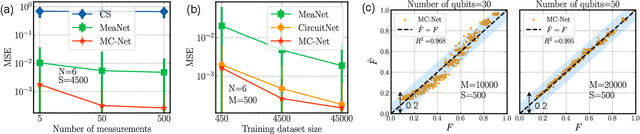
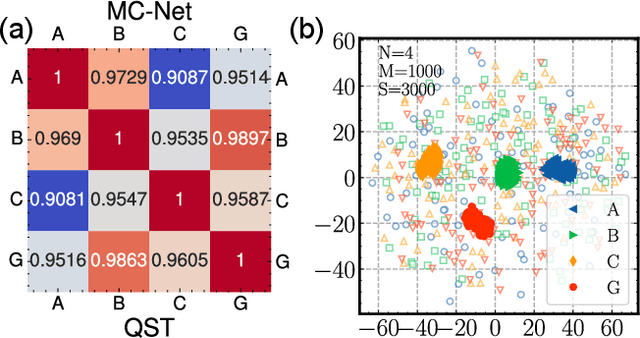
Cross-platform verification, a critical undertaking in the realm of early-stage quantum computing, endeavors to characterize the similarity of two imperfect quantum devices executing identical algorithms, utilizing minimal measurements. While the random measurement approach has been instrumental in this context, the quasi-exponential computational demand with increasing qubit count hurdles its feasibility in large-qubit scenarios. To bridge this knowledge gap, here we introduce an innovative multimodal learning approach, recognizing that the formalism of data in this task embodies two distinct modalities: measurement outcomes and classical description of compiled circuits on explored quantum devices, both enriched with unique information. Building upon this insight, we devise a multimodal neural network to independently extract knowledge from these modalities, followed by a fusion operation to create a comprehensive data representation. The learned representation can effectively characterize the similarity between the explored quantum devices when executing new quantum algorithms not present in the training data. We evaluate our proposal on platforms featuring diverse noise models, encompassing system sizes up to 50 qubits. The achieved results demonstrate a three-orders-of-magnitude improvement in prediction accuracy compared to the random measurements and offer compelling evidence of the complementary roles played by each modality in cross-platform verification. These findings pave the way for harnessing the power of multimodal learning to overcome challenges in wider quantum system learning tasks.
EigenGAN: Layer-Wise Eigen-Learning for GANs
Apr 26, 2021



Recent studies on Generative Adversarial Network (GAN) reveal that different layers of a generative CNN hold different semantics of the synthesized images. However, few GAN models have explicit dimensions to control the semantic attributes represented in a specific layer. This paper proposes EigenGAN which is able to unsupervisedly mine interpretable and controllable dimensions from different generator layers. Specifically, EigenGAN embeds one linear subspace with orthogonal basis into each generator layer. Via the adversarial training to learn a target distribution, these layer-wise subspaces automatically discover a set of "eigen-dimensions" at each layer corresponding to a set of semantic attributes or interpretable variations. By traversing the coefficient of a specific eigen-dimension, the generator can produce samples with continuous changes corresponding to a specific semantic attribute. Taking the human face for example, EigenGAN can discover controllable dimensions for high-level concepts such as pose and gender in the subspace of deep layers, as well as low-level concepts such as hue and color in the subspace of shallow layers. Moreover, under the linear circumstance, we theoretically prove that our algorithm derives the principal components as PCA does. Codes can be found in https://github.com/LynnHo/EigenGAN-Tensorflow.
PA-GAN: Progressive Attention Generative Adversarial Network for Facial Attribute Editing
Jul 12, 2020
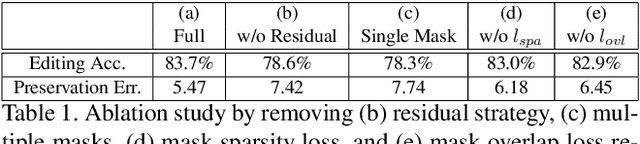

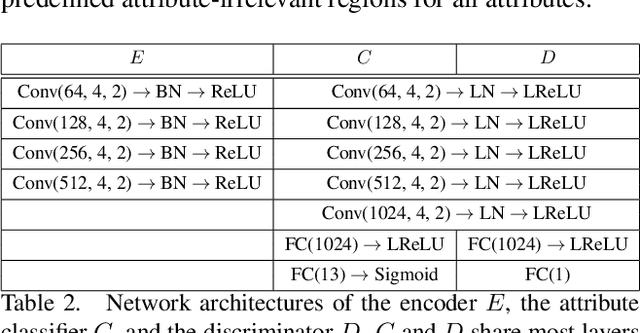
Facial attribute editing aims to manipulate attributes on the human face, e.g., adding a mustache or changing the hair color. Existing approaches suffer from a serious compromise between correct attribute generation and preservation of the other information such as identity and background, because they edit the attributes in the imprecise area. To resolve this dilemma, we propose a progressive attention GAN (PA-GAN) for facial attribute editing. In our approach, the editing is progressively conducted from high to low feature level while being constrained inside a proper attribute area by an attention mask at each level. This manner prevents undesired modifications to the irrelevant regions from the beginning, and then the network can focus more on correctly generating the attributes within a proper boundary at each level. As a result, our approach achieves correct attribute editing with irrelevant details much better preserved compared with the state-of-the-arts. Codes are released at https://github.com/LynnHo/PA-GAN-Tensorflow.
AttGAN: Facial Attribute Editing by Only Changing What You Want
Jul 25, 2018
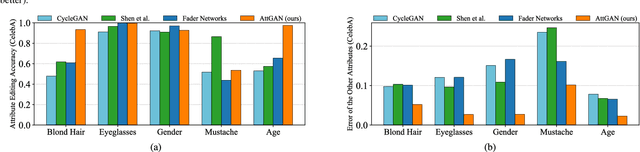
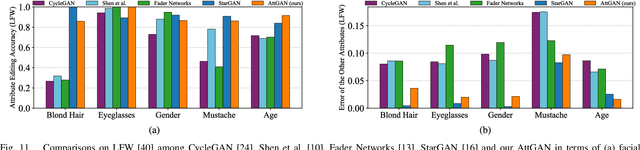

Facial attribute editing aims to manipulate single or multiple attributes of a face image, i.e., to generate a new face with desired attributes while preserving other details. Recently, generative adversarial net (GAN) and encoder-decoder architecture are usually incorporated to handle this task with promising results. Based on the encoder-decoder architecture, facial attribute editing is achieved by decoding the latent representation of the given face conditioned on the desired attributes. Some existing methods attempt to establish an attribute-independent latent representation for further attribute editing. However, such attribute-independent constraint on the latent representation is excessive because it restricts the capacity of the latent representation and may result in information loss, leading to over-smooth and distorted generation. Instead of imposing constraints on the latent representation, in this work we apply an attribute classification constraint to the generated image to just guarantee the correct change of desired attributes, i.e., to "change what you want". Meanwhile, the reconstruction learning is introduced to preserve attribute-excluding details, in other words, to "only change what you want". Besides, the adversarial learning is employed for visually realistic editing. These three components cooperate with each other forming an effective framework for high quality facial attribute editing, referred as AttGAN. Furthermore, our method is also directly applicable for attribute intensity control and can be naturally extended for attribute style manipulation. Experiments on CelebA dataset show that our method outperforms the state-of-the-arts on realistic attribute editing with facial details well preserved.
Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness
Sep 23, 2016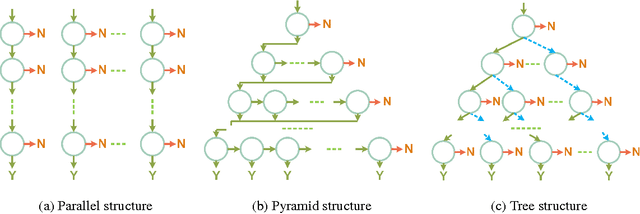

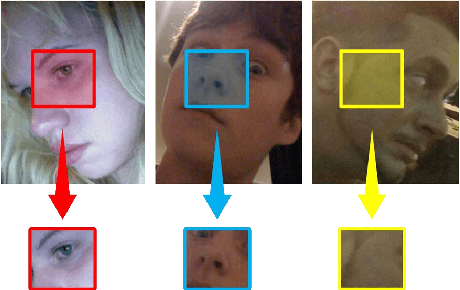

Multi-view face detection in open environment is a challenging task due to diverse variations of face appearances and shapes. Most multi-view face detectors depend on multiple models and organize them in parallel, pyramid or tree structure, which compromise between the accuracy and time-cost. Aiming at a more favorable multi-view face detector, we propose a novel funnel-structured cascade (FuSt) detection framework. In a coarse-to-fine flavor, our FuSt consists of, from top to bottom, 1) multiple view-specific fast LAB cascade for extremely quick face proposal, 2) multiple coarse MLP cascade for further candidate window verification, and 3) a unified fine MLP cascade with shape-indexed features for accurate face detection. Compared with other structures, on the one hand, the proposed one uses multiple computationally efficient distributed classifiers to propose a small number of candidate windows but with a high recall of multi-view faces. On the other hand, by using a unified MLP cascade to examine proposals of all views in a centralized style, it provides a favorable solution for multi-view face detection with high accuracy and low time-cost. Besides, the FuSt detector is alignment-aware and performs a coarse facial part prediction which is beneficial for subsequent face alignment. Extensive experiments on two challenging datasets, FDDB and AFW, demonstrate the effectiveness of our FuSt detector in both accuracy and speed.