 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-CLIP Uncertainty Modeling for Group Re-Identification
Feb 10, 2025
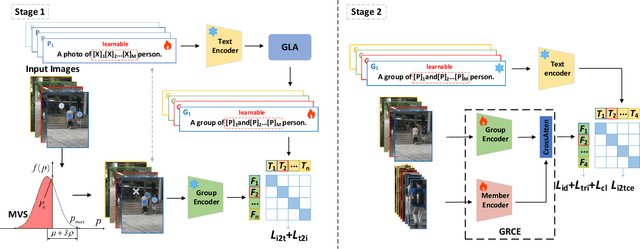


Group Re-Identification (Group ReID) aims matching groups of pedestrians across non-overlapping cameras. Unlike single-person ReID, Group ReID focuses more on the changes in group structure, emphasizing the number of members and their spatial arrangement. However, most methods rely on certainty-based models, which consider only the specific group structures in the group images, often failing to match unseen group configurations. To this end, we propose a novel Group-CLIP UncertaintyModeling (GCUM) approach that adapts group text descriptions to undetermined accommodate member and layout variations. Specifically, we design a Member Variant Simulation (MVS)module that simulates member exclusions using a Bernoulli distribution and a Group Layout Adaptation (GLA) module that generates uncertain group text descriptions with identity-specific tokens. In addition, we design a Group RelationshipConstruction Encoder (GRCE) that uses group features to refine individual features, and employ cross-modal contrastive loss to obtain generalizable knowledge from group text descriptions. It is worth noting that we are the first to employ CLIP to GroupReID, and extensive experiments show that GCUM significantly outperforms state-of-the-art Group ReID methods.
Quantum Machine Learning: A Hands-on Tutorial for Machine Learning Practitioners and Researchers
Feb 03, 2025This tutorial intends to introduce readers with a background in AI to quantum machine learning (QML) -- a rapidly evolving field that seeks to leverage the power of quantum computers to reshape the landscape of machine learning. For self-consistency, this tutorial covers foundational principles, representative QML algorithms, their potential applications, and critical aspects such as trainability, generalization, and computational complexity. In addition, practical code demonstrations are provided in https://qml-tutorial.github.io/ to illustrate real-world implementations and facilitate hands-on learning. Together, these elements offer readers a comprehensive overview of the latest advancements in QML. By bridging the gap between classical machine learning and quantum computing, this tutorial serves as a valuable resource for those looking to engage with QML and explore the forefront of AI in the quantum era.
MG-Net: Learn to Customize QAOA with Circuit Depth Awareness
Sep 27, 2024
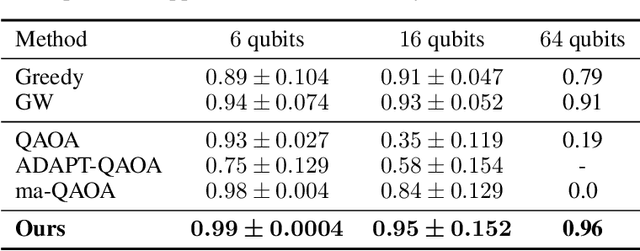


Quantum Approximate Optimization Algorithm (QAOA) and its variants exhibit immense potential in tackling combinatorial optimization challenges. However, their practical realization confronts a dilemma: the requisite circuit depth for satisfactory performance is problem-specific and often exceeds the maximum capability of current quantum devices. To address this dilemma, here we first analyze the convergence behavior of QAOA, uncovering the origins of this dilemma and elucidating the intricate relationship between the employed mixer Hamiltonian, the specific problem at hand, and the permissible maximum circuit depth. Harnessing this understanding, we introduce the Mixer Generator Network (MG-Net), a unified deep learning framework adept at dynamically formulating optimal mixer Hamiltonians tailored to distinct tasks and circuit depths. Systematic simulations, encompassing Ising models and weighted Max-Cut instances with up to 64 qubits, substantiate our theoretical findings, highlighting MG-Net's superior performance in terms of both approximation ratio and efficiency.
Weather Prediction Using CNN-LSTM for Time Series Analysis: A Case Study on Delhi Temperature Data
Sep 14, 2024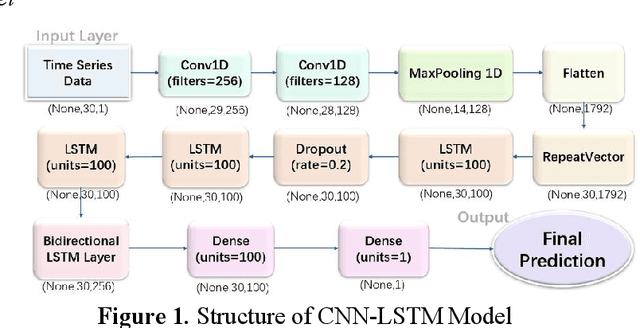

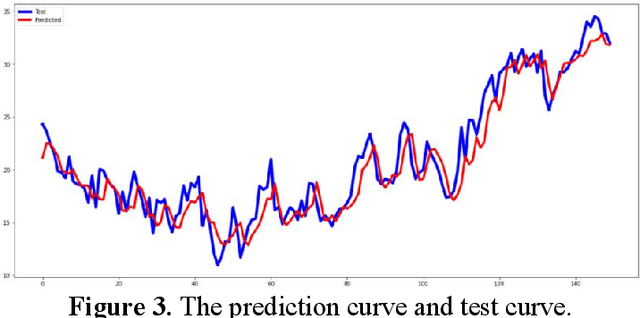
As global climate change intensifies, accurate weather forecasting is increasingly crucial for sectors such as agriculture, energy management, and environmental protection. Traditional methods, which rely on physical and statistical models, often struggle with complex, nonlinear, and time-varying data, underscoring the need for more advanced techniques. This study explores a hybrid CNN-LSTM model to enhance temperature forecasting accuracy for the Delhi region, using historical meteorological data from 1996 to 2017. We employed both direct and indirect methods, including comprehensive data preprocessing and exploratory analysis, to construct and train our model. The CNN component effectively extracts spatial features, while the LSTM captures temporal dependencies, leading to improved prediction accuracy. Experimental results indicate that the CNN-LSTM model significantly outperforms traditional forecasting methods in terms of both accuracy and stability, with a mean square error (MSE) of 3.26217 and a root mean square error (RMSE) of 1.80615. The hybrid model demonstrates its potential as a robust tool for temperature prediction, offering valuable insights for meteorological forecasting and related fields. Future research should focus on optimizing model architecture, exploring additional feature extraction techniques, and addressing challenges such as overfitting and computational complexity. This approach not only advances temperature forecasting but also provides a foundation for applying deep learning to other time series forecasting tasks.
DRAL: Deep Reinforcement Adaptive Learning for Multi-UAVs Navigation in Unknown Indoor Environment
Sep 05, 2024



Autonomous indoor navigation of UAVs presents numerous challenges, primarily due to the limited precision of GPS in enclosed environments. Additionally, UAVs' limited capacity to carry heavy or power-intensive sensors, such as overheight packages, exacerbates the difficulty of achieving autonomous navigation indoors. This paper introduces an advanced system in which a drone autonomously navigates indoor spaces to locate a specific target, such as an unknown Amazon package, using only a single camera. Employing a deep learning approach, a deep reinforcement adaptive learning algorithm is trained to develop a control strategy that emulates the decision-making process of an expert pilot. We demonstrate the efficacy of our system through real-time simulations conducted in various indoor settings. We apply multiple visualization techniques to gain deeper insights into our trained network. Furthermore, we extend our approach to include an adaptive control algorithm for coordinating multiple drones to lift an object in an indoor environment collaboratively. Integrating our DRAL algorithm enables multiple UAVs to learn optimal control strategies that adapt to dynamic conditions and uncertainties. This innovation enhances the robustness and flexibility of indoor navigation and opens new possibilities for complex multi-drone operations in confined spaces. The proposed framework highlights significant advancements in adaptive control and deep reinforcement learning, offering robust solutions for complex multi-agent systems in real-world applications.
TikTokActions: A TikTok-Derived Video Dataset for Human Action Recognition
Feb 14, 2024



The increasing variety and quantity of tagged multimedia content on platforms such as TikTok provides an opportunity to advance computer vision modeling. We have curated a distinctive dataset of 283,582 unique video clips categorized under 386 hashtags relating to modern human actions. We release this dataset as a valuable resource for building domain-specific foundation models for human movement modeling tasks such as action recognition. To validate this dataset, which we name TikTokActions, we perform two sets of experiments. First, we pretrain the state-of-the-art VideoMAEv2 with a ViT-base backbone on TikTokActions subset, and then fine-tune and evaluate on popular datasets such as UCF101 and the HMDB51. We find that the performance of the model pre-trained using our Tik-Tok dataset is comparable to models trained on larger action recognition datasets (95.3% on UCF101 and 53.24% on HMDB51). Furthermore, our investigation into the relationship between pre-training dataset size and fine-tuning performance reveals that beyond a certain threshold, the incremental benefit of larger training sets diminishes. This work introduces a useful TikTok video dataset that is available for public use and provides insights into the marginal benefit of increasing pre-training dataset sizes for video-based foundation models.
Multimodal deep representation learning for quantum cross-platform verification
Nov 07, 2023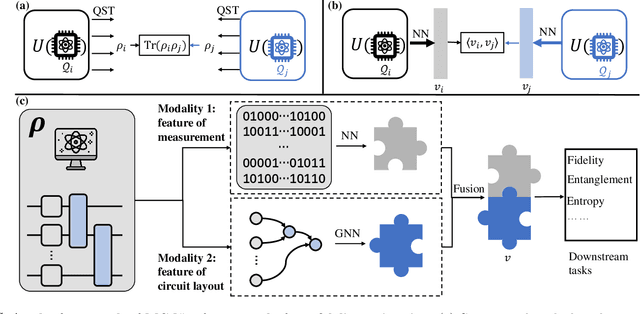
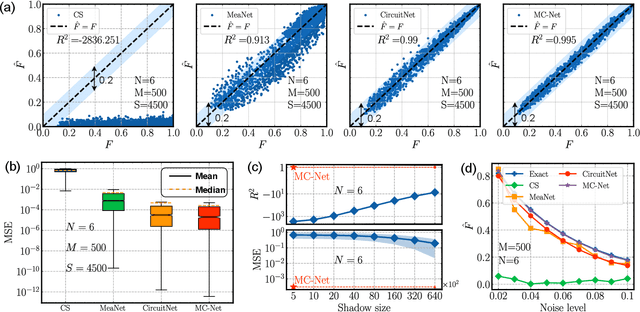
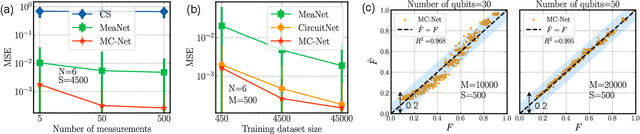
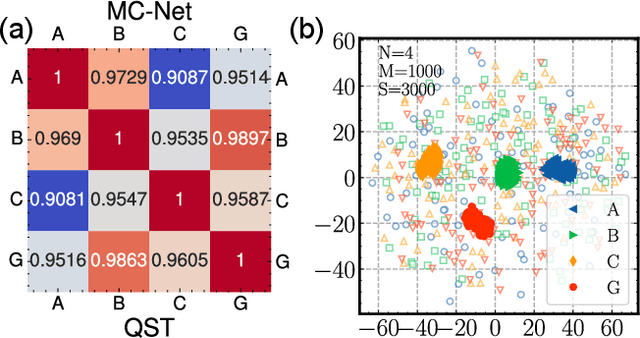
Cross-platform verification, a critical undertaking in the realm of early-stage quantum computing, endeavors to characterize the similarity of two imperfect quantum devices executing identical algorithms, utilizing minimal measurements. While the random measurement approach has been instrumental in this context, the quasi-exponential computational demand with increasing qubit count hurdles its feasibility in large-qubit scenarios. To bridge this knowledge gap, here we introduce an innovative multimodal learning approach, recognizing that the formalism of data in this task embodies two distinct modalities: measurement outcomes and classical description of compiled circuits on explored quantum devices, both enriched with unique information. Building upon this insight, we devise a multimodal neural network to independently extract knowledge from these modalities, followed by a fusion operation to create a comprehensive data representation. The learned representation can effectively characterize the similarity between the explored quantum devices when executing new quantum algorithms not present in the training data. We evaluate our proposal on platforms featuring diverse noise models, encompassing system sizes up to 50 qubits. The achieved results demonstrate a three-orders-of-magnitude improvement in prediction accuracy compared to the random measurements and offer compelling evidence of the complementary roles played by each modality in cross-platform verification. These findings pave the way for harnessing the power of multimodal learning to overcome challenges in wider quantum system learning tasks.
Computer Vision Estimation of Emotion Reaction Intensity in the Wild
Mar 19, 2023

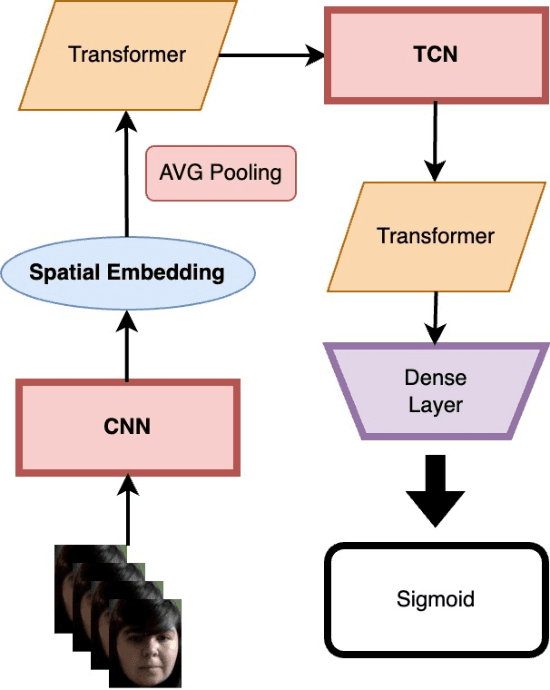
Emotions play an essential role in human communication. Developing computer vision models for automatic recognition of emotion expression can aid in a variety of domains, including robotics, digital behavioral healthcare, and media analytics. There are three types of emotional representations which are traditionally modeled in affective computing research: Action Units, Valence Arousal (VA), and Categorical Emotions. As part of an effort to move beyond these representations towards more fine-grained labels, we describe our submission to the newly introduced Emotional Reaction Intensity (ERI) Estimation challenge in the 5th competition for Affective Behavior Analysis in-the-Wild (ABAW). We developed four deep neural networks trained in the visual domain and a multimodal model trained with both visual and audio features to predict emotion reaction intensity. Our best performing model on the Hume-Reaction dataset achieved an average Pearson correlation coefficient of 0.4080 on the test set using a pre-trained ResNet50 model. This work provides a first step towards the development of production-grade models which predict emotion reaction intensities rather than discrete emotion categories.
Shuffle-QUDIO: accelerate distributed VQE with trainability enhancement and measurement reduction
Sep 26, 2022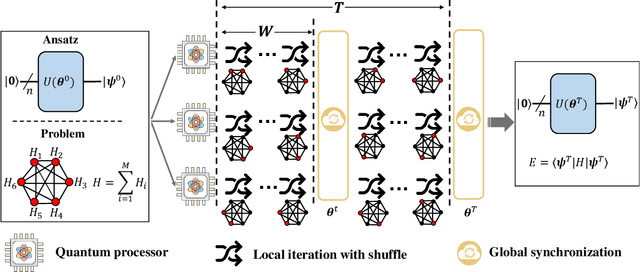

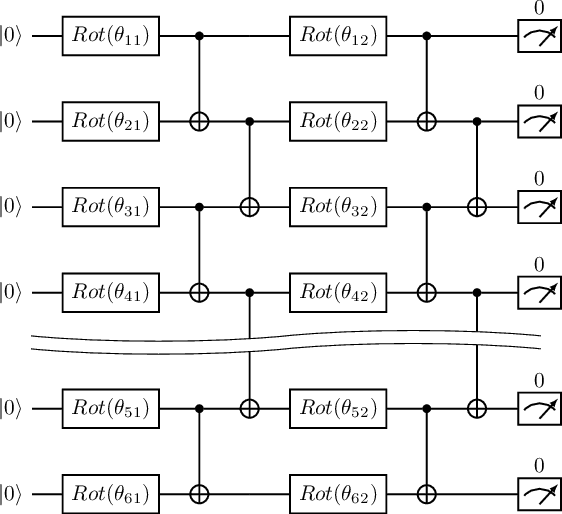
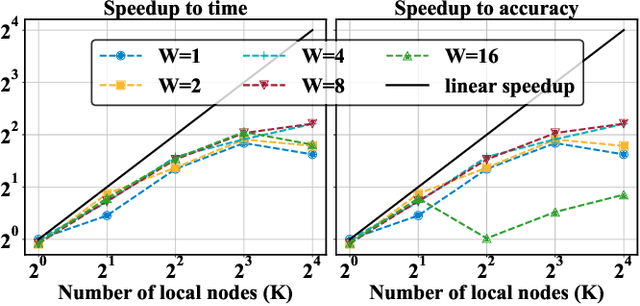
The variational quantum eigensolver (VQE) is a leading strategy that exploits noisy intermediate-scale quantum (NISQ) machines to tackle chemical problems outperforming classical approaches. To gain such computational advantages on large-scale problems, a feasible solution is the QUantum DIstributed Optimization (QUDIO) scheme, which partitions the original problem into $K$ subproblems and allocates them to $K$ quantum machines followed by the parallel optimization. Despite the provable acceleration ratio, the efficiency of QUDIO may heavily degrade by the synchronization operation. To conquer this issue, here we propose Shuffle-QUDIO to involve shuffle operations into local Hamiltonians during the quantum distributed optimization. Compared with QUDIO, Shuffle-QUDIO significantly reduces the communication frequency among quantum processors and simultaneously achieves better trainability. Particularly, we prove that Shuffle-QUDIO enables a faster convergence rate over QUDIO. Extensive numerical experiments are conducted to verify that Shuffle-QUDIO allows both a wall-clock time speedup and low approximation error in the tasks of estimating the ground state energy of molecule. We empirically demonstrate that our proposal can be seamlessly integrated with other acceleration techniques, such as operator grouping, to further improve the efficacy of VQE.
PoseFace: Pose-Invariant Features and Pose-Adaptive Loss for Face Recognition
Jul 25, 2021
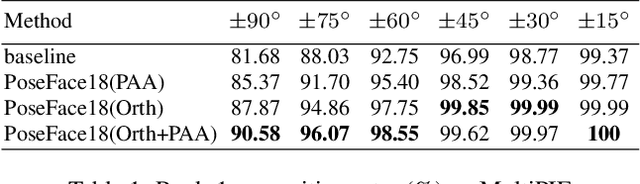
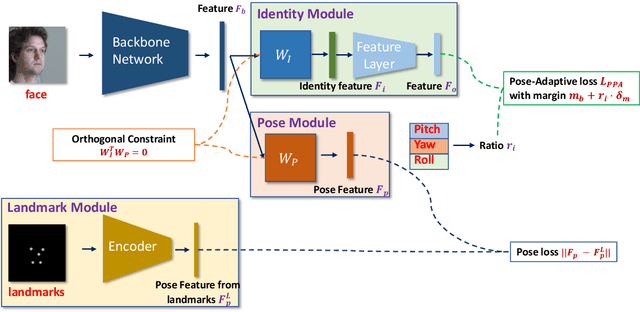
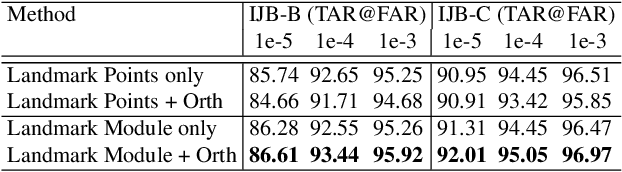
Despite the great success achieved by deep learning methods in face recognition, severe performance drops are observed for large pose variations in unconstrained environments (e.g., in cases of surveillance and photo-tagging). To address it, current methods either deploy pose-specific models or frontalize faces by additional modules. Still, they ignore the fact that identity information should be consistent across poses and are not realizing the data imbalance between frontal and profile face images during training. In this paper, we propose an efficient PoseFace framework which utilizes the facial landmarks to disentangle the pose-invariant features and exploits a pose-adaptive loss to handle the imbalance issue adaptively. Extensive experimental results on the benchmarks of Multi-PIE, CFP, CPLFW and IJB have demonstrated the superiority of our method over the state-of-the-arts.