 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-CLIP Uncertainty Modeling for Group Re-Identification
Paper and Code
Feb 10, 2025
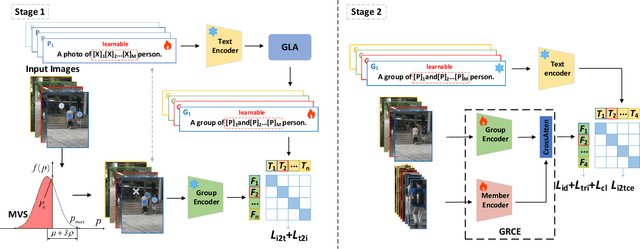


Group Re-Identification (Group ReID) aims matching groups of pedestrians across non-overlapping cameras. Unlike single-person ReID, Group ReID focuses more on the changes in group structure, emphasizing the number of members and their spatial arrangement. However, most methods rely on certainty-based models, which consider only the specific group structures in the group images, often failing to match unseen group configurations. To this end, we propose a novel Group-CLIP UncertaintyModeling (GCUM) approach that adapts group text descriptions to undetermined accommodate member and layout variations. Specifically, we design a Member Variant Simulation (MVS)module that simulates member exclusions using a Bernoulli distribution and a Group Layout Adaptation (GLA) module that generates uncertain group text descriptions with identity-specific tokens. In addition, we design a Group RelationshipConstruction Encoder (GRCE) that uses group features to refine individual features, and employ cross-modal contrastive loss to obtain generalizable knowledge from group text descriptions. It is worth noting that we are the first to employ CLIP to GroupReID, and extensive experiments show that GCUM significantly outperforms state-of-the-art Group ReID methods.