 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Collaboration of Multi-Language Models based on Minimal Complete Semantic Units
Aug 26, 2025This paper investigates the enhancement of reasoning capabilities in language models through token-level multi-model collaboration. Our approach selects the optimal tokens from the next token distributions provided by multiple models to perform autoregressive reasoning. Contrary to the assumption that more models yield better results, we introduce a distribution distance-based dynamic selection strategy (DDS) to optimize the multi-model collaboration process. To address the critical challenge of vocabulary misalignment in multi-model collaboration, we propose the concept of minimal complete semantic units (MCSU), which is simple yet enables multiple language models to achieve natural alignment within the linguistic space. Experimental results across various benchmarks demonstrate the superiority of our method. The code will be available at https://github.com/Fanye12/DDS.
Adaptive Tuning of Robotic Polishing Skills based on Force Feedback Model
Oct 23, 2023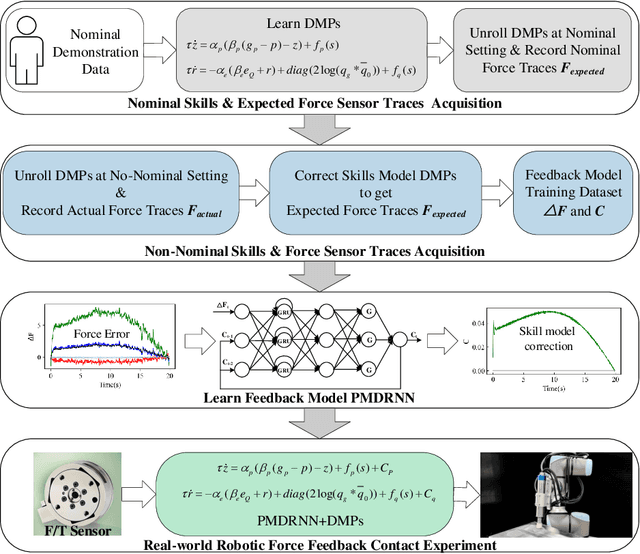
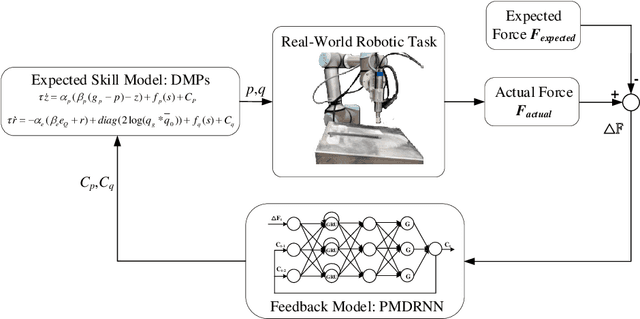
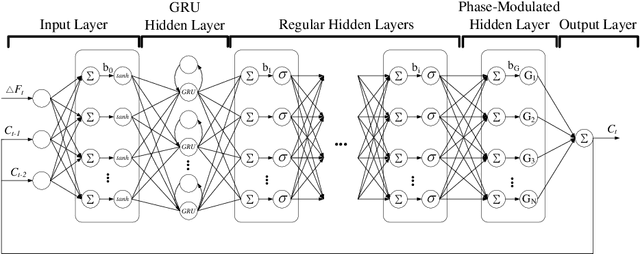

Acquiring human skills offers an efficient approach to tackle complex task planning challenges. When performing a learned skill model for a continuous contact task, such as robot polishing in an uncertain environment, the robot needs to be able to adaptively modify the skill model to suit the environment and perform the desired task. The environmental perturbation of the polishing task is mainly reflected in the variation of contact force. Therefore, adjusting the task skill model by providing feedback on the contact force deviation is an effective way to meet the task requirements. In this study, a phase-modulated diagonal recurrent neural network (PMDRNN) is proposed for force feedback model learning in the robotic polishing task. The contact between the tool and the workpiece in the polishing task can be considered a dynamic system. In comparison to the existing feedforward neural network phase-modulated neural network (PMNN), PMDRNN combines the diagonal recurrent network structure with the phase-modulated neural network layer to improve the learning performance of the feedback model for dynamic systems. Specifically, data from real-world robot polishing experiments are used to learn the feedback model. PMDRNN demonstrates a significant reduction in the training error of the feedback model when compared to PMNN. Building upon this, the combination of PMDRNN and dynamic movement primitives (DMPs) can be used for real-time adjustment of skills for polishing tasks and effectively improve the robustness of the task skill model. Finally, real-world robotic polishing experiments are conducted to demonstrate the effectiveness of the approach.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 18, 2022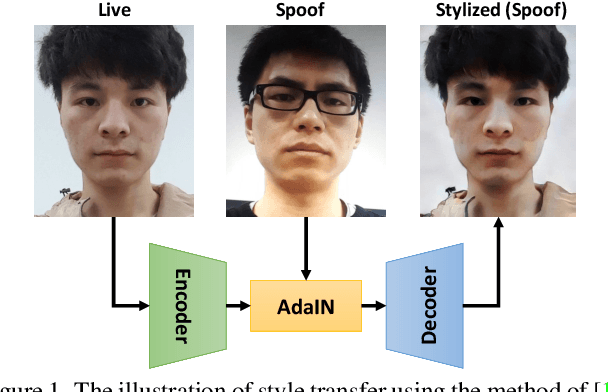
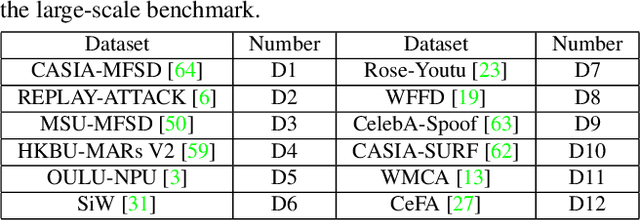
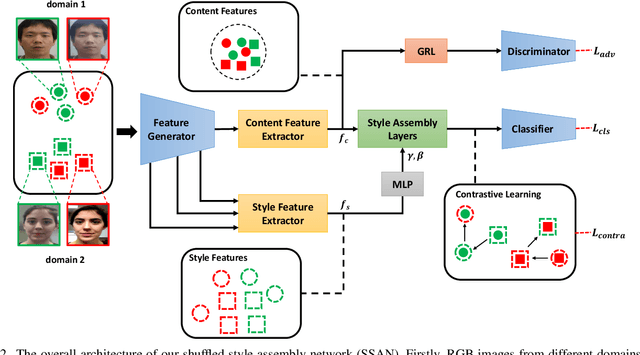
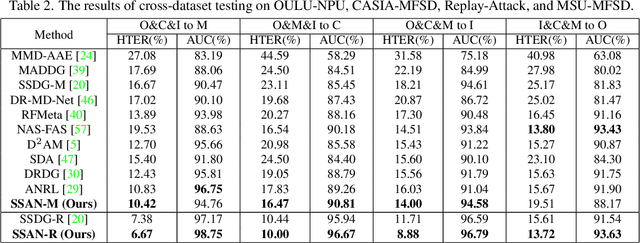
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.
Consistency Regularization for Deep Face Anti-Spoofing
Nov 25, 2021



Face anti-spoofing (FAS) plays a crucial role in securing face recognition systems. Empirically, given an image, a model with more consistent output on different views of this image usually performs better, as shown in Fig.1. Motivated by this exciting observation, we conjecture that encouraging feature consistency of different views may be a promising way to boost FAS models. In this paper, we explore this way thoroughly by enhancing both Embedding-level and Prediction-level Consistency Regularization (EPCR) in FAS. Specifically, at the embedding-level, we design a dense similarity loss to maximize the similarities between all positions of two intermediate feature maps in a self-supervised fashion; while at the prediction-level, we optimize the mean square error between the predictions of two views. Notably, our EPCR is free of annotations and can directly integrate into semi-supervised learning schemes. Considering different application scenarios, we further design five diverse semi-supervised protocols to measure semi-supervised FAS techniques. We conduct extensive experiments to show that EPCR can significantly improve the performance of several supervised and semi-supervised tasks on benchmark datasets. The codes and protocols will be released at https://github.com/clks-wzz/EPCR.
Meta-Teacher For Face Anti-Spoofing
Nov 12, 2021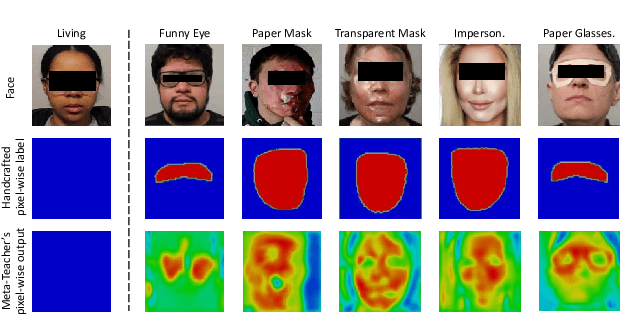
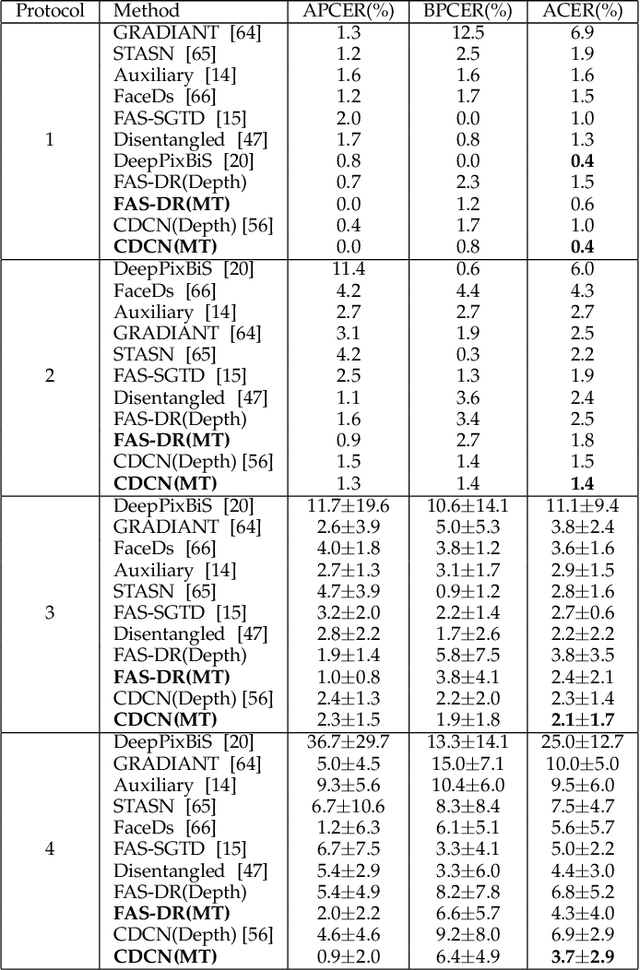
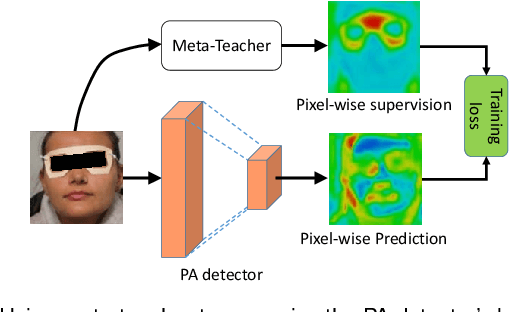
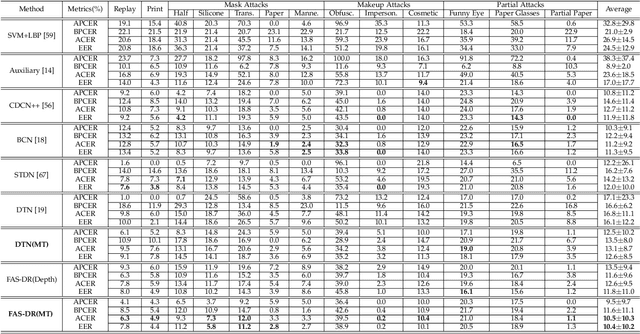
Face anti-spoofing (FAS) secures face recognition from presentation attacks (PAs). Existing FAS methods usually supervise PA detectors with handcrafted binary or pixel-wise labels. However, handcrafted labels may are not the most adequate way to supervise PA detectors learning sufficient and intrinsic spoofing cues. Instead of using the handcrafted labels, we propose a novel Meta-Teacher FAS (MT-FAS) method to train a meta-teacher for supervising PA detectors more effectively. The meta-teacher is trained in a bi-level optimization manner to learn the ability to supervise the PA detectors learning rich spoofing cues. The bi-level optimization contains two key components: 1) a lower-level training in which the meta-teacher supervises the detector's learning process on the training set; and 2) a higher-level training in which the meta-teacher's teaching performance is optimized by minimizing the detector's validation loss. Our meta-teacher differs significantly from existing teacher-student models because the meta-teacher is explicitly trained for better teaching the detector (student), whereas existing teachers are trained for outstanding accuracy neglecting teaching ability. Extensive experiments on five FAS benchmarks show that with the proposed MT-FAS, the trained meta-teacher 1) provides better-suited supervision than both handcrafted labels and existing teacher-student models; and 2) significantly improves the performances of PA detectors.
PoseFace: Pose-Invariant Features and Pose-Adaptive Loss for Face Recognition
Jul 25, 2021
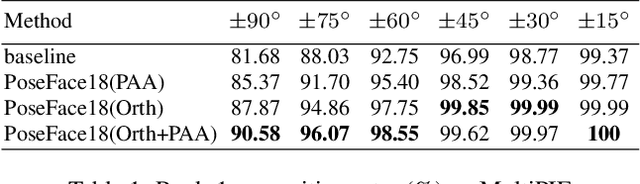
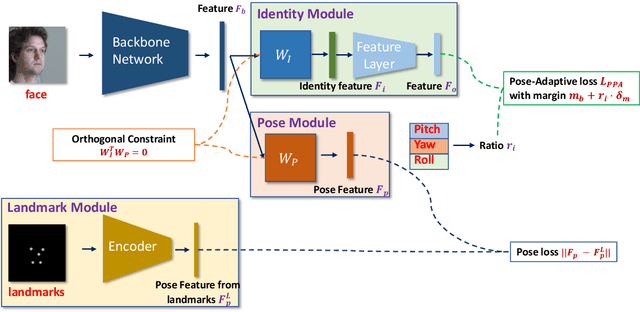
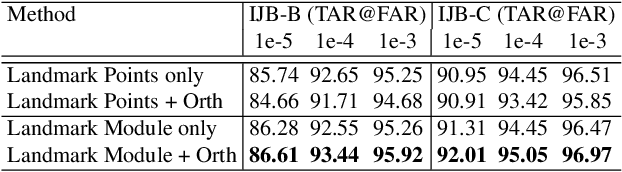
Despite the great success achieved by deep learning methods in face recognition, severe performance drops are observed for large pose variations in unconstrained environments (e.g., in cases of surveillance and photo-tagging). To address it, current methods either deploy pose-specific models or frontalize faces by additional modules. Still, they ignore the fact that identity information should be consistent across poses and are not realizing the data imbalance between frontal and profile face images during training. In this paper, we propose an efficient PoseFace framework which utilizes the facial landmarks to disentangle the pose-invariant features and exploits a pose-adaptive loss to handle the imbalance issue adaptively. Extensive experimental results on the benchmarks of Multi-PIE, CFP, CPLFW and IJB have demonstrated the superiority of our method over the state-of-the-arts.
Layer-Wise Adaptive Updating for Few-Shot Image Classification
Jul 16, 2020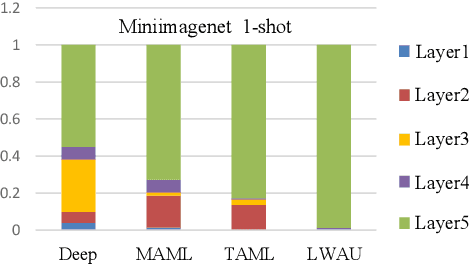
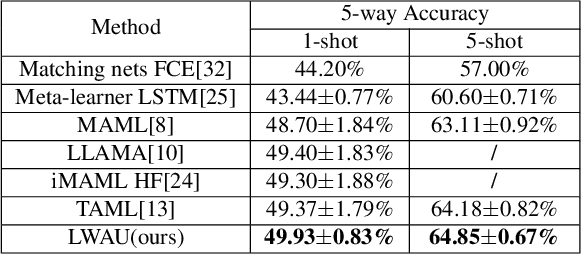
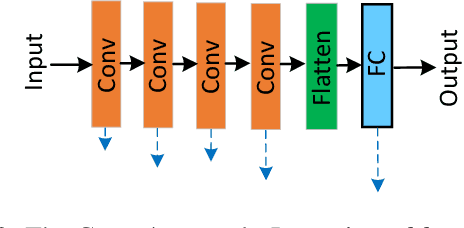

Few-shot image classification (FSIC), which requires a model to recognize new categories via learning from few images of these categories, has attracted lots of attention. Recently, meta-learning based methods have been shown as a promising direction for FSIC. Commonly, they train a meta-learner (meta-learning model) to learn easy fine-tuning weight, and when solving an FSIC task, the meta-learner efficiently fine-tunes itself to a task-specific model by updating itself on few images of the task. In this paper, we propose a novel meta-learning based layer-wise adaptive updating (LWAU) method for FSIC. LWAU is inspired by an interesting finding that compared with common deep models, the meta-learner pays much more attention to update its top layer when learning from few images. According to this finding, we assume that the meta-learner may greatly prefer updating its top layer to updating its bottom layers for better FSIC performance. Therefore, in LWAU, the meta-learner is trained to learn not only the easy fine-tuning model but also its favorite layer-wise adaptive updating rule to improve its learning efficiency. Extensive experiments show that with the layer-wise adaptive updating rule, the proposed LWAU: 1) outperforms existing few-shot classification methods with a clear margin; 2) learns from few images more efficiently by at least 5 times than existing meta-learners when solving FSIC.
Multi-Modal Face Anti-Spoofing Based on Central Difference Networks
Apr 17, 2020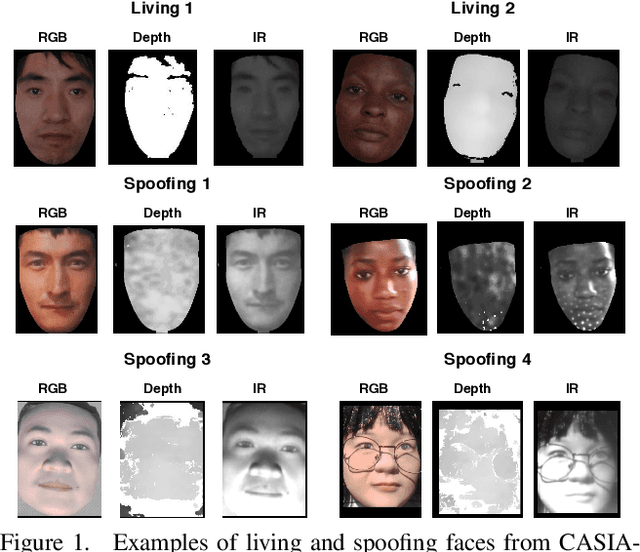
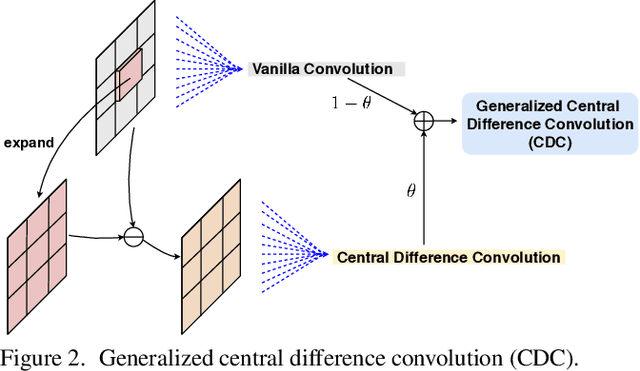
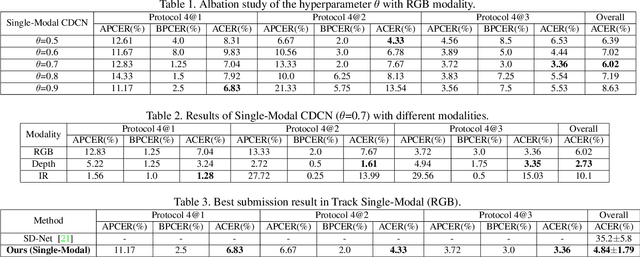
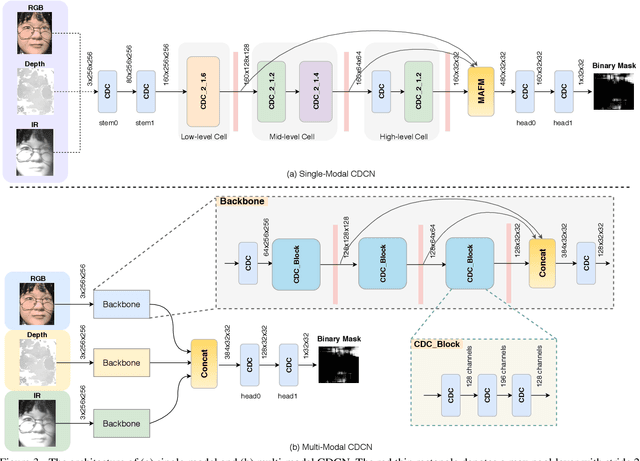
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from presentation attacks. Existing multi-modal FAS methods rely on stacked vanilla convolutions, which is weak in describing detailed intrinsic information from modalities and easily being ineffective when the domain shifts (e.g., cross attack and cross ethnicity). In this paper, we extend the central difference convolutional networks (CDCN) \cite{yu2020searching} to a multi-modal version, intending to capture intrinsic spoofing patterns among three modalities (RGB, depth and infrared). Meanwhile, we also give an elaborate study about single-modal based CDCN. Our approach won the first place in "Track Multi-Modal" as well as the second place in "Track Single-Modal (RGB)" of ChaLearn Face Anti-spoofing Attack Detection Challenge@CVPR2020 \cite{liu2020cross}. Our final submission obtains 1.02$\pm$0.59\% and 4.84$\pm$1.79\% ACER in "Track Multi-Modal" and "Track Single-Modal (RGB)", respectively. The codes are available at{https://github.com/ZitongYu/CDCN}.
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
Mar 18, 2020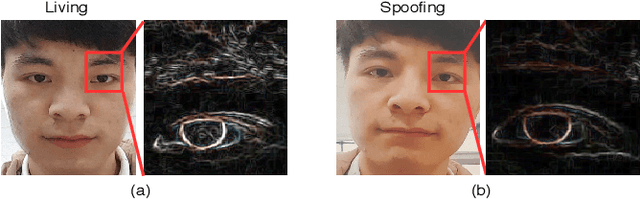
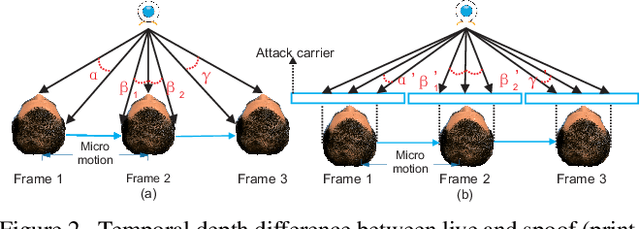

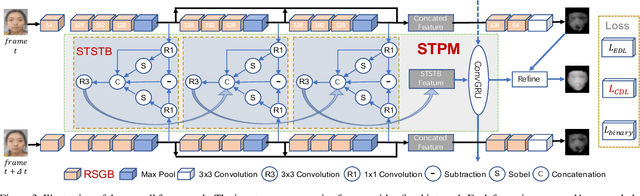
Face anti-spoofing is critical to the security of face recognition systems. Depth supervised learning has been proven as one of the most effective methods for face anti-spoofing. Despite the great success, most previous works still formulate the problem as a single-frame multi-task one by simply augmenting the loss with depth, while neglecting the detailed fine-grained information and the interplay between facial depths and moving patterns. In contrast, we design a new approach to detect presentation attacks from multiple frames based on two insights: 1) detailed discriminative clues (e.g., spatial gradient magnitude) between living and spoofing face may be discarded through stacked vanilla convolutions, and 2) the dynamics of 3D moving faces provide important clues in detecting the spoofing faces. The proposed method is able to capture discriminative details via Residual Spatial Gradient Block (RSGB) and encode spatio-temporal information from Spatio-Temporal Propagation Module (STPM) efficiently. Moreover, a novel Contrastive Depth Loss is presented for more accurate depth supervision. To assess the efficacy of our method, we also collect a Double-modal Anti-spoofing Dataset (DMAD) which provides actual depth for each sample. The experiments demonstrate that the proposed approach achieves state-of-the-art results on five benchmark datasets including OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, and the new DMAD. Codes will be available at https://github.com/clks-wzz/FAS-SGTD.
Searching Central Difference Convolutional Networks for Face Anti-Spoofing
Mar 09, 2020
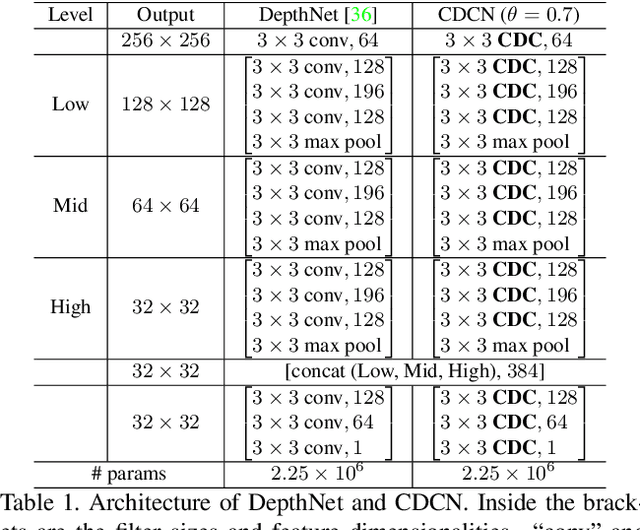
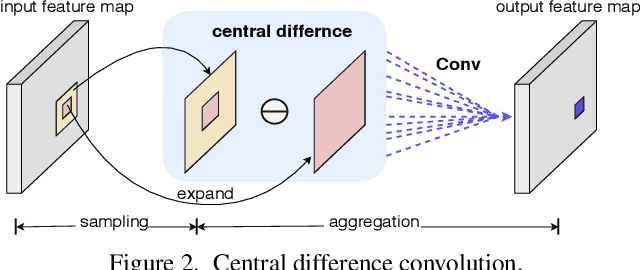

Face anti-spoofing (FAS) plays a vital role in face recognition systems. Most state-of-the-art FAS methods 1) rely on stacked convolutions and expert-designed network, which is weak in describing detailed fine-grained information and easily being ineffective when the environment varies (e.g., different illumination), and 2) prefer to use long sequence as input to extract dynamic features, making them difficult to deploy into scenarios which need quick response. Here we propose a novel frame level FAS method based on Central Difference Convolution (CDC), which is able to capture intrinsic detailed patterns via aggregating both intensity and gradient information. A network built with CDC, called the Central Difference Convolutional Network (CDCN), is able to provide more robust modeling capacity than its counterpart built with vanilla convolution. Furthermore, over a specifically designed CDC search space, Neural Architecture Search (NAS) is utilized to discover a more powerful network structure (CDCN++), which can be assembled with Multiscale Attention Fusion Module (MAFM) for further boosting performance. Comprehensive experiments are performed on six benchmark datasets to show that 1) the proposed method not only achieves superior performance on intra-dataset testing (especially 0.2% ACER in Protocol-1 of OULU-NPU dataset), 2) it also generalizes well on cross-dataset testing (particularly 6.5% HTER from CASIA-MFSD to Replay-Attack datasets). The codes are available at \href{https://github.com/ZitongYu/CDCN}{https://github.com/ZitongYu/CDCN}.