 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: A vision-language foundation model for embodied intelligence
Jan 29, 2026When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expression
Dec 13, 2024



Audio-driven talking head generation necessitates seamless integration of audio and visual data amidst the challenges posed by diverse input portraits and intricate correlations between audio and facial motions. In response, we propose a robust framework GoHD designed to produce highly realistic, expressive, and controllable portrait videos from any reference identity with any motion. GoHD innovates with three key modules: Firstly, an animation module utilizing latent navigation is introduced to improve the generalization ability across unseen input styles. This module achieves high disentanglement of motion and identity, and it also incorporates gaze orientation to rectify unnatural eye movements that were previously overlooked. Secondly, a conformer-structured conditional diffusion model is designed to guarantee head poses that are aware of prosody. Thirdly, to estimate lip-synchronized and realistic expressions from the input audio within limited training data, a two-stage training strategy is devised to decouple frequent and frame-wise lip motion distillation from the generation of other more temporally dependent but less audio-related motions, e.g., blinks and frowns. Extensive experiments validate GoHD's advanced generalization capabilities, demonstrating its effectiveness in generating realistic talking face results on arbitrary subjects.
ROSE: Revolutionizing Open-Set Dense Segmentation with Patch-Wise Perceptual Large Multimodal Model
Nov 29, 2024Advances in CLIP and large multimodal models (LMMs) have enabled open-vocabulary and free-text segmentation, yet existing models still require predefined category prompts, limiting free-form category self-generation. Most segmentation LMMs also remain confined to sparse predictions, restricting their applicability in open-set environments. In contrast, we propose ROSE, a Revolutionary Open-set dense SEgmentation LMM, which enables dense mask prediction and open-category generation through patch-wise perception. Our method treats each image patch as an independent region of interest candidate, enabling the model to predict both dense and sparse masks simultaneously. Additionally, a newly designed instruction-response paradigm takes full advantage of the generation and generalization capabilities of LMMs, achieving category prediction independent of closed-set constraints or predefined categories. To further enhance mask detail and category precision, we introduce a conversation-based refinement paradigm, integrating the prediction result from previous step with textual prompt for revision. Extensive experiments demonstrate that ROSE achieves competitive performance across various segmentation tasks in a unified framework. Code will be released.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024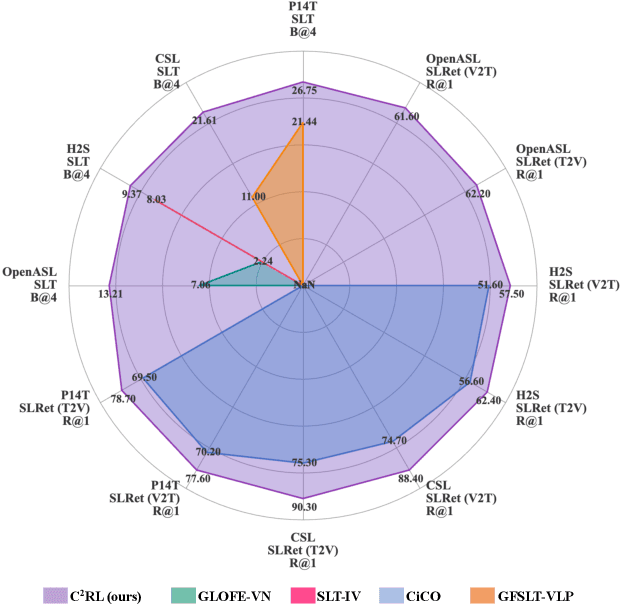
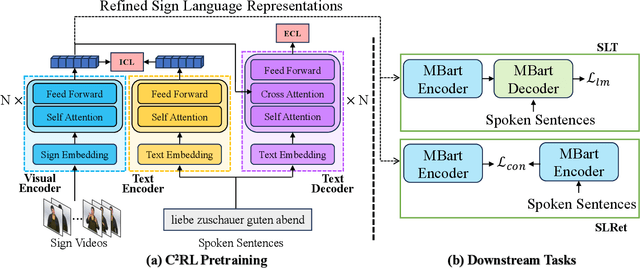
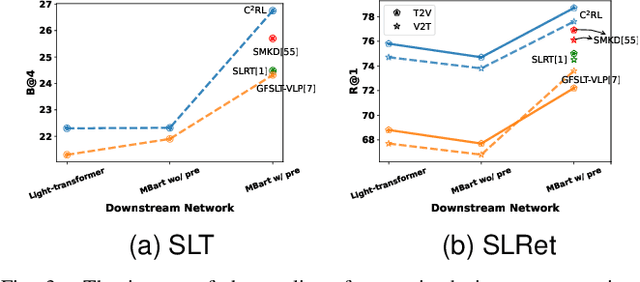
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
I2Edit: Towards Multi-turn Interactive Image Editing via Dialogue
Mar 23, 2023Although there have been considerable research efforts on controllable facial image editing, the desirable interactive setting where the users can interact with the system to adjust their requirements dynamically hasn't been well explored. This paper focuses on facial image editing via dialogue and introduces a new benchmark dataset, Multi-turn Interactive Image Editing (I2Edit), for evaluating image editing quality and interaction ability in real-world interactive facial editing scenarios. The dataset is constructed upon the CelebA-HQ dataset with images annotated with a multi-turn dialogue that corresponds to the user editing requirements. I2Edit is challenging, as it needs to 1) track the dynamically updated user requirements and edit the images accordingly, as well as 2) generate the appropriate natural language response to communicate with the user. To address these challenges, we propose a framework consisting of a dialogue module and an image editing module. The former is for user edit requirements tracking and generating the corresponding indicative responses, while the latter edits the images conditioned on the tracked user edit requirements. In contrast to previous works that simply treat multi-turn interaction as a sequence of single-turn interactions, we extract the user edit requirements from the whole dialogue history instead of the current single turn. The extracted global user edit requirements enable us to directly edit the input raw image to avoid error accumulation and attribute forgetting issues. Extensive quantitative and qualitative experiments on the I2Edit dataset demonstrate the advantage of our proposed framework over the previous single-turn methods. We believe our new dataset could serve as a valuable resource to push forward the exploration of real-world, complex interactive image editing. Code and data will be made public.
Scale Attention for Learning Deep Face Representation: A Study Against Visual Scale Variation
Sep 19, 2022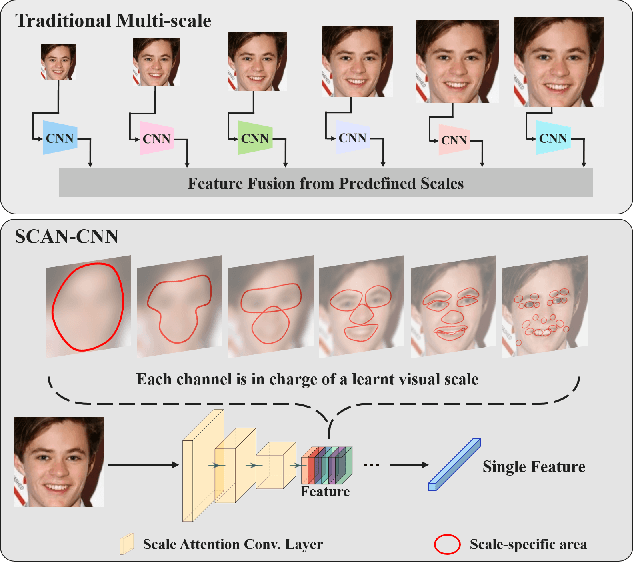
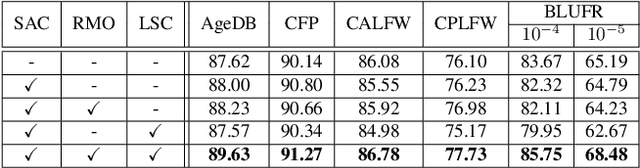
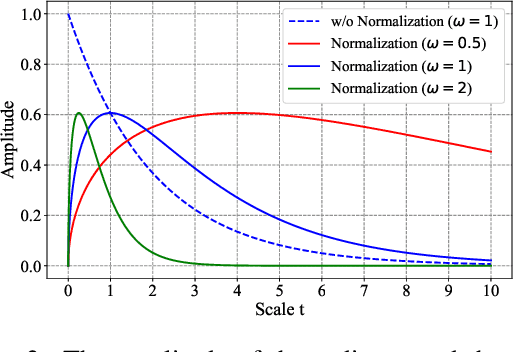
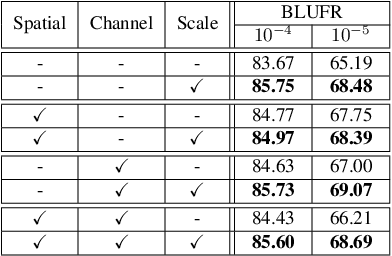
Human face images usually appear with wide range of visual scales. The existing face representations pursue the bandwidth of handling scale variation via multi-scale scheme that assembles a finite series of predefined scales. Such multi-shot scheme brings inference burden, and the predefined scales inevitably have gap from real data. Instead, learning scale parameters from data, and using them for one-shot feature inference, is a decent solution. To this end, we reform the conv layer by resorting to the scale-space theory, and achieve two-fold facilities: 1) the conv layer learns a set of scales from real data distribution, each of which is fulfilled by a conv kernel; 2) the layer automatically highlights the feature at the proper channel and location corresponding to the input pattern scale and its presence. Then, we accomplish the hierarchical scale attention by stacking the reformed layers, building a novel style named SCale AttentioN Conv Neural Network (\textbf{SCAN-CNN}). We apply SCAN-CNN to the face recognition task and push the frontier of SOTA performance. The accuracy gain is more evident when the face images are blurry. Meanwhile, as a single-shot scheme, the inference is more efficient than multi-shot fusion. A set of tools are made to ensure the fast training of SCAN-CNN and zero increase of inference cost compared with the plain CNN.
PetsGAN: Rethinking Priors for Single Image Generation
Mar 03, 2022
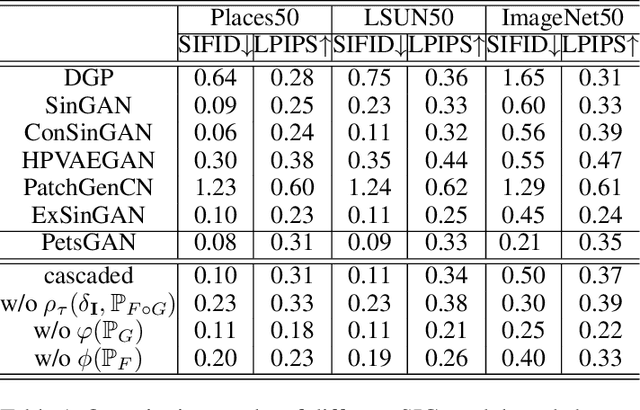

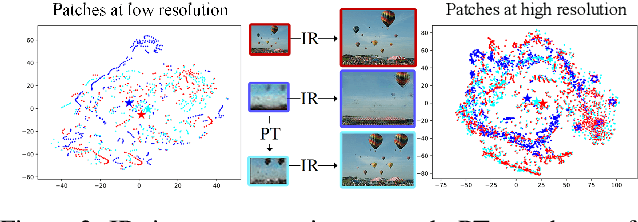
Single image generation (SIG), described as generating diverse samples that have similar visual content with the given single image, is first introduced by SinGAN which builds a pyramid of GANs to progressively learn the internal patch distribution of the single image. It also shows great potentials in a wide range of image manipulation tasks. However, the paradigm of SinGAN has limitations in terms of generation quality and training time. Firstly, due to the lack of high-level information, SinGAN cannot handle the object images well as it does on the scene and texture images. Secondly, the separate progressive training scheme is time-consuming and easy to cause artifact accumulation. To tackle these problems, in this paper, we dig into the SIG problem and improve SinGAN by fully-utilization of internal and external priors. The main contributions of this paper include: 1) We introduce to SIG a regularized latent variable model. To the best of our knowledge, it is the first time to give a clear formulation and optimization goal of SIG, and all the existing methods for SIG can be regarded as special cases of this model. 2) We design a novel Prior-based end-to-end training GAN (PetsGAN) to overcome the problems of SinGAN. Our method gets rid of the time-consuming progressive training scheme and can be trained end-to-end. 3) We construct abundant qualitative and quantitative experiments to show the superiority of our method on both generated image quality, diversity, and the training speed. Moreover, we apply our method to other image manipulation tasks (e.g., style transfer, harmonization), and the results further prove the effectiveness and efficiency of our method.
Dual Spoof Disentanglement Generation for Face Anti-spoofing with Depth Uncertainty Learning
Dec 01, 2021

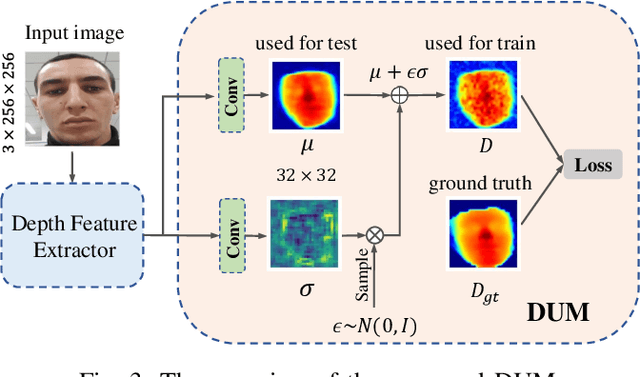

Face anti-spoofing (FAS) plays a vital role in preventing face recognition systems from presentation attacks. Existing face anti-spoofing datasets lack diversity due to the insufficient identity and insignificant variance, which limits the generalization ability of FAS model. In this paper, we propose Dual Spoof Disentanglement Generation (DSDG) framework to tackle this challenge by "anti-spoofing via generation". Depending on the interpretable factorized latent disentanglement in Variational Autoencoder (VAE), DSDG learns a joint distribution of the identity representation and the spoofing pattern representation in the latent space. Then, large-scale paired live and spoofing images can be generated from random noise to boost the diversity of the training set. However, some generated face images are partially distorted due to the inherent defect of VAE. Such noisy samples are hard to predict precise depth values, thus may obstruct the widely-used depth supervised optimization. To tackle this issue, we further introduce a lightweight Depth Uncertainty Module (DUM), which alleviates the adverse effects of noisy samples by depth uncertainty learning. DUM is developed without extra-dependency, thus can be flexibly integrated with any depth supervised network for face anti-spoofing. We evaluate the effectiveness of the proposed method on five popular benchmarks and achieve state-of-the-art results under both intra- and inter- test settings. The codes are available at https://github.com/JDAI-CV/FaceX-Zoo/tree/main/addition_module/DSDG.
FasterPose: A Faster Simple Baseline for Human Pose Estimation
Jul 07, 2021
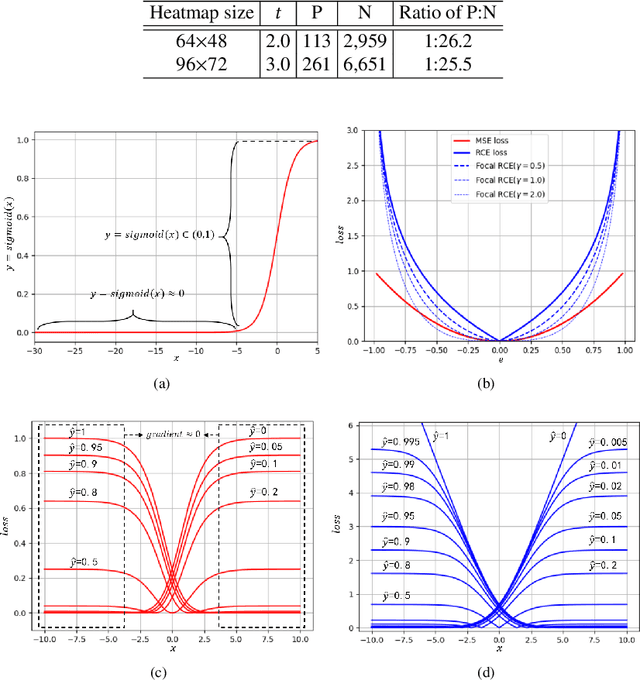
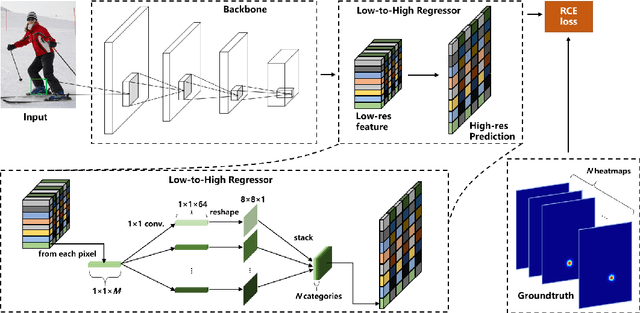

The performance of human pose estimation depends on the spatial accuracy of keypoint localization. Most existing methods pursue the spatial accuracy through learning the high-resolution (HR) representation from input images. By the experimental analysis, we find that the HR representation leads to a sharp increase of computational cost, while the accuracy improvement remains marginal compared with the low-resolution (LR) representation. In this paper, we propose a design paradigm for cost-effective network with LR representation for efficient pose estimation, named FasterPose. Whereas the LR design largely shrinks the model complexity, yet how to effectively train the network with respect to the spatial accuracy is a concomitant challenge. We study the training behavior of FasterPose, and formulate a novel regressive cross-entropy (RCE) loss function for accelerating the convergence and promoting the accuracy. The RCE loss generalizes the ordinary cross-entropy loss from the binary supervision to a continuous range, thus the training of pose estimation network is able to benefit from the sigmoid function. By doing so, the output heatmap can be inferred from the LR features without loss of spatial accuracy, while the computational cost and model size has been significantly reduced. Compared with the previously dominant network of pose estimation, our method reduces 58% of the FLOPs and simultaneously gains 1.3% improvement of accuracy. Extensive experiments show that FasterPose yields promising results on the common benchmarks, i.e., COCO and MPII, consistently validating the effectiveness and efficiency for practical utilization, especially the low-latency and low-energy-budget applications in the non-GPU scenarios.
Boosting Semi-Supervised Face Recognition with Noise Robustness
May 10, 2021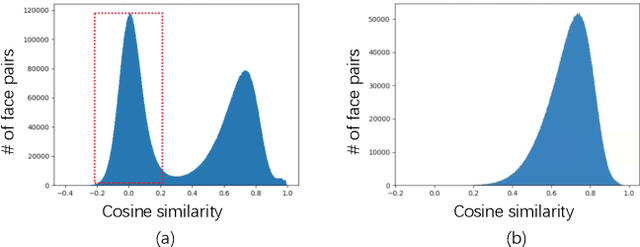


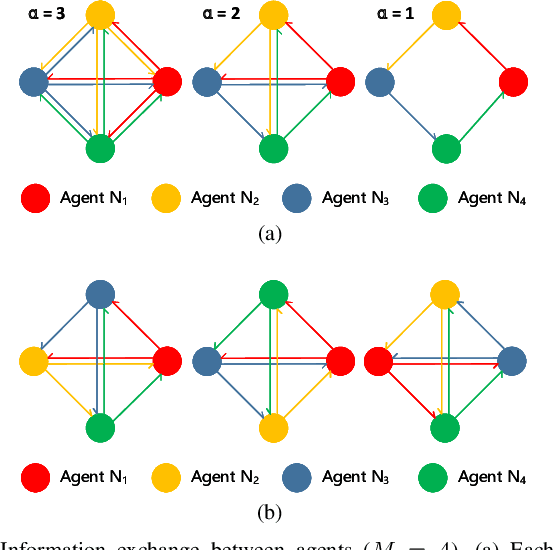
Although deep face recognition benefits significantly from large-scale training data, a current bottleneck is the labelling cost. A feasible solution to this problem is semi-supervised learning, exploiting a small portion of labelled data and large amounts of unlabelled data. The major challenge, however, is the accumulated label errors through auto-labelling, compromising the training. This paper presents an effective solution to semi-supervised face recognition that is robust to the label noise aroused by the auto-labelling. Specifically, we introduce a multi-agent method, named GroupNet (GN), to endow our solution with the ability to identify the wrongly labelled samples and preserve the clean samples. We show that GN alone achieves the leading accuracy in traditional supervised face recognition even when the noisy labels take over 50\% of the training data. Further, we develop a semi-supervised face recognition solution, named Noise Robust Learning-Labelling (NRoLL), which is based on the robust training ability empowered by GN. It starts with a small amount of labelled data and consequently conducts high-confidence labelling on a large amount of unlabelled data to boost further training. The more data is labelled by NRoLL, the higher confidence is with the label in the dataset. To evaluate the competitiveness of our method, we run NRoLL with a rough condition that only one-fifth of the labelled MSCeleb is available and the rest is used as unlabelled data. On a wide range of benchmarks, our method compares favorably against the state-of-the-art methods.