 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DResT: A Strong Baseline for Semi-Supervised 3D Referring Expression Segmentation
Apr 17, 20253D Referring Expression Segmentation (3D-RES) typically requires extensive instance-level annotations, which are time-consuming and costly. Semi-supervised learning (SSL) mitigates this by using limited labeled data alongside abundant unlabeled data, improving performance while reducing annotation costs. SSL uses a teacher-student paradigm where teacher generates high-confidence-filtered pseudo-labels to guide student. However, in the context of 3D-RES, where each label corresponds to a single mask and labeled data is scarce, existing SSL methods treat high-quality pseudo-labels merely as auxiliary supervision, which limits the model's learning potential. The reliance on high-confidence thresholds for filtering often results in potentially valuable pseudo-labels being discarded, restricting the model's ability to leverage the abundant unlabeled data. Therefore, we identify two critical challenges in semi-supervised 3D-RES, namely, inefficient utilization of high-quality pseudo-labels and wastage of useful information from low-quality pseudo-labels. In this paper, we introduce the first semi-supervised learning framework for 3D-RES, presenting a robust baseline method named 3DResT. To address these challenges, we propose two novel designs called Teacher-Student Consistency-Based Sampling (TSCS) and Quality-Driven Dynamic Weighting (QDW). TSCS aids in the selection of high-quality pseudo-labels, integrating them into the labeled dataset to strengthen the labeled supervision signals. QDW preserves low-quality pseudo-labels by dynamically assigning them lower weights, allowing for the effective extraction of useful information rather than discarding them. Extensive experiments conducted on the widely used benchmark demonstrate the effectiveness of our method. Notably, with only 1% labeled data, 3DResT achieves an mIoU improvement of 8.34 points compared to the fully supervised method.
ROSE: Revolutionizing Open-Set Dense Segmentation with Patch-Wise Perceptual Large Multimodal Model
Nov 29, 2024
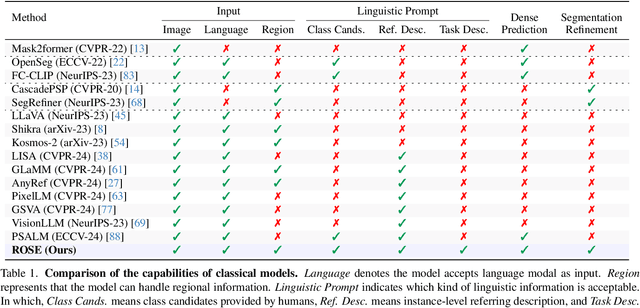
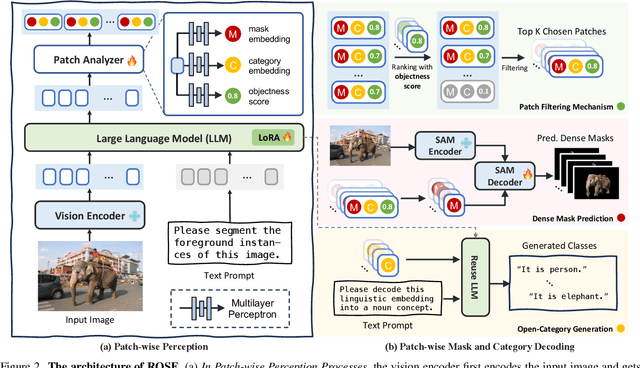
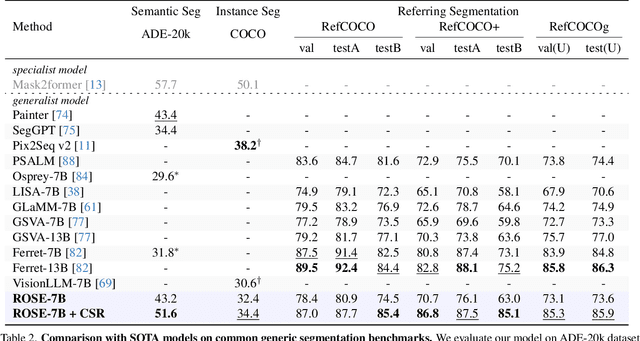
Advances in CLIP and large multimodal models (LMMs) have enabled open-vocabulary and free-text segmentation, yet existing models still require predefined category prompts, limiting free-form category self-generation. Most segmentation LMMs also remain confined to sparse predictions, restricting their applicability in open-set environments. In contrast, we propose ROSE, a Revolutionary Open-set dense SEgmentation LMM, which enables dense mask prediction and open-category generation through patch-wise perception. Our method treats each image patch as an independent region of interest candidate, enabling the model to predict both dense and sparse masks simultaneously. Additionally, a newly designed instruction-response paradigm takes full advantage of the generation and generalization capabilities of LMMs, achieving category prediction independent of closed-set constraints or predefined categories. To further enhance mask detail and category precision, we introduce a conversation-based refinement paradigm, integrating the prediction result from previous step with textual prompt for revision. Extensive experiments demonstrate that ROSE achieves competitive performance across various segmentation tasks in a unified framework. Code will be released.
ACTRESS: Active Retraining for Semi-supervised Visual Grounding
Jul 03, 2024Semi-Supervised Visual Grounding (SSVG) is a new challenge for its sparse labeled data with the need for multimodel understanding. A previous study, RefTeacher, makes the first attempt to tackle this task by adopting the teacher-student framework to provide pseudo confidence supervision and attention-based supervision. However, this approach is incompatible with current state-of-the-art visual grounding models, which follow the Transformer-based pipeline. These pipelines directly regress results without region proposals or foreground binary classification, rendering them unsuitable for fitting in RefTeacher due to the absence of confidence scores. Furthermore, the geometric difference in teacher and student inputs, stemming from different data augmentations, induces natural misalignment in attention-based constraints. To establish a compatible SSVG framework, our paper proposes the ACTive REtraining approach for Semi-Supervised Visual Grounding, abbreviated as ACTRESS. Initially, the model is enhanced by incorporating an additional quantized detection head to expose its detection confidence. Building upon this, ACTRESS consists of an active sampling strategy and a selective retraining strategy. The active sampling strategy iteratively selects high-quality pseudo labels by evaluating three crucial aspects: Faithfulness, Robustness, and Confidence, optimizing the utilization of unlabeled data. The selective retraining strategy retrains the model with periodic re-initialization of specific parameters, facilitating the model's escape from local minima. Extensive experiments demonstrates our superior performance on widely-used benchmark datasets.
Intent3D: 3D Object Detection in RGB-D Scans Based on Human Intention
May 28, 2024



In real-life scenarios, humans seek out objects in the 3D world to fulfill their daily needs or intentions. This inspires us to introduce 3D intention grounding, a new task in 3D object detection employing RGB-D, based on human intention, such as "I want something to support my back". Closely related, 3D visual grounding focuses on understanding human reference. To achieve detection based on human intention, it relies on humans to observe the scene, reason out the target that aligns with their intention ("pillow" in this case), and finally provide a reference to the AI system, such as "A pillow on the couch". Instead, 3D intention grounding challenges AI agents to automatically observe, reason and detect the desired target solely based on human intention. To tackle this challenge, we introduce the new Intent3D dataset, consisting of 44,990 intention texts associated with 209 fine-grained classes from 1,042 scenes of the ScanNet dataset. We also establish several baselines based on different language-based 3D object detection models on our benchmark. Finally, we propose IntentNet, our unique approach, designed to tackle this intention-based detection problem. It focuses on three key aspects: intention understanding, reasoning to identify object candidates, and cascaded adaptive learning that leverages the intrinsic priority logic of different losses for multiple objective optimization.
RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments
Oct 26, 2023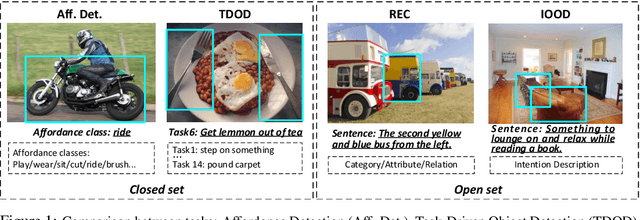
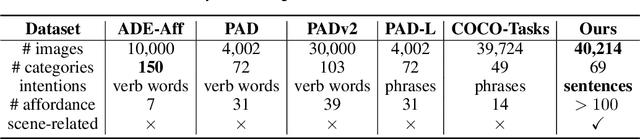
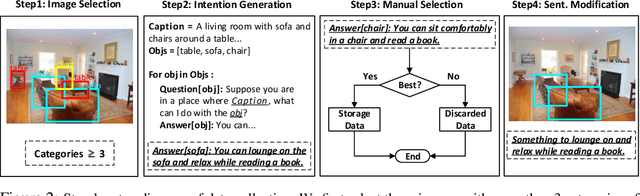
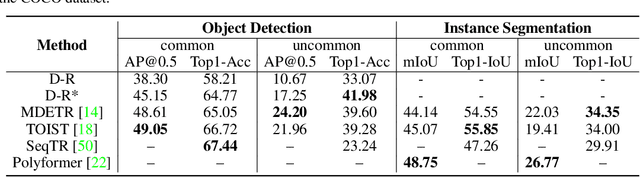
Intention-oriented object detection aims to detect desired objects based on specific intentions or requirements. For instance, when we desire to "lie down and rest", we instinctively seek out a suitable option such as a "bed" or a "sofa" that can fulfill our needs. Previous work in this area is limited either by the number of intention descriptions or by the affordance vocabulary available for intention objects. These limitations make it challenging to handle intentions in open environments effectively. To facilitate this research, we construct a comprehensive dataset called Reasoning Intention-Oriented Objects (RIO). In particular, RIO is specifically designed to incorporate diverse real-world scenarios and a wide range of object categories. It offers the following key features: 1) intention descriptions in RIO are represented as natural sentences rather than a mere word or verb phrase, making them more practical and meaningful; 2) the intention descriptions are contextually relevant to the scene, enabling a broader range of potential functionalities associated with the objects; 3) the dataset comprises a total of 40,214 images and 130,585 intention-object pairs. With the proposed RIO, we evaluate the ability of some existing models to reason intention-oriented objects in open environments.
SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Jul 27, 2022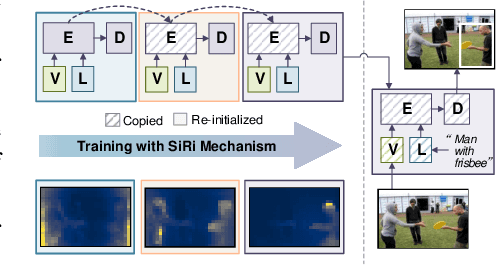
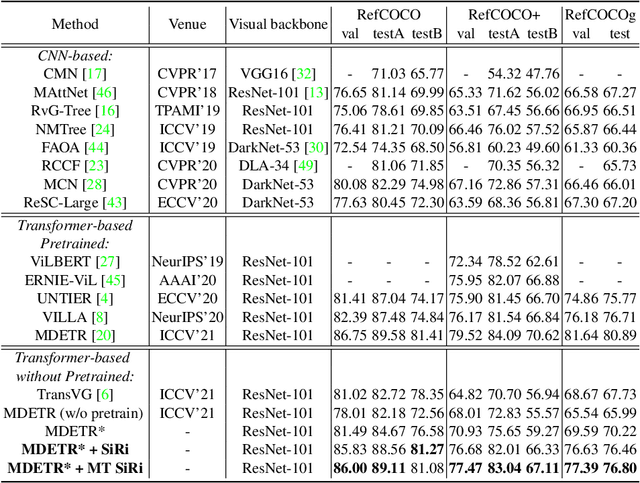
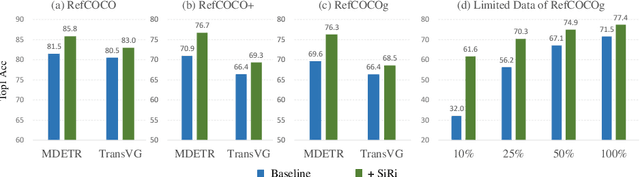
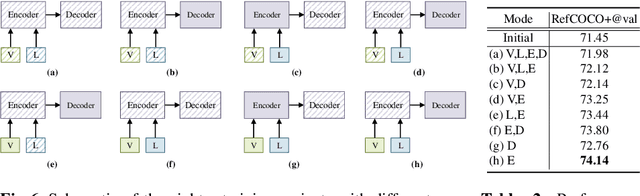
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.