 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSE: Revolutionizing Open-Set Dense Segmentation with Patch-Wise Perceptual Large Multimodal Model
Paper and Code
Nov 29, 2024
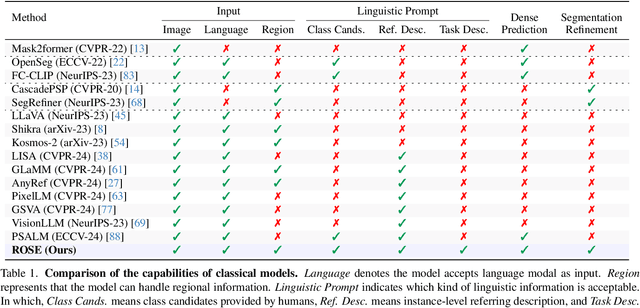
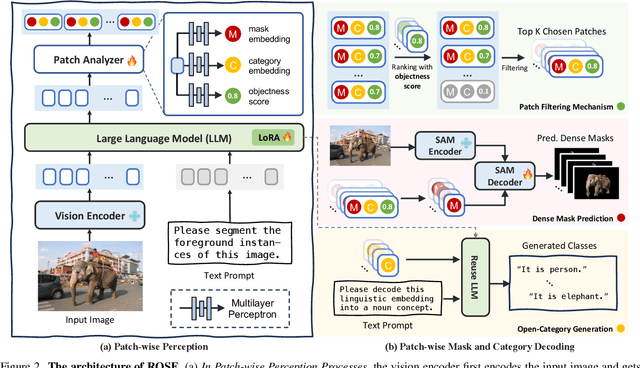
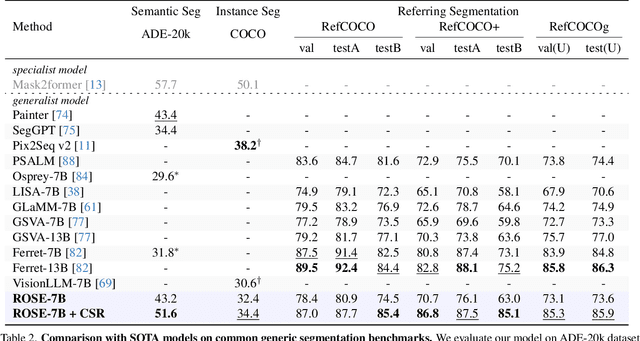
Advances in CLIP and large multimodal models (LMMs) have enabled open-vocabulary and free-text segmentation, yet existing models still require predefined category prompts, limiting free-form category self-generation. Most segmentation LMMs also remain confined to sparse predictions, restricting their applicability in open-set environments. In contrast, we propose ROSE, a Revolutionary Open-set dense SEgmentation LMM, which enables dense mask prediction and open-category generation through patch-wise perception. Our method treats each image patch as an independent region of interest candidate, enabling the model to predict both dense and sparse masks simultaneously. Additionally, a newly designed instruction-response paradigm takes full advantage of the generation and generalization capabilities of LMMs, achieving category prediction independent of closed-set constraints or predefined categories. To further enhance mask detail and category precision, we introduce a conversation-based refinement paradigm, integrating the prediction result from previous step with textual prompt for revision. Extensive experiments demonstrate that ROSE achieves competitive performance across various segmentation tasks in a unified framework. Code will be released.