 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
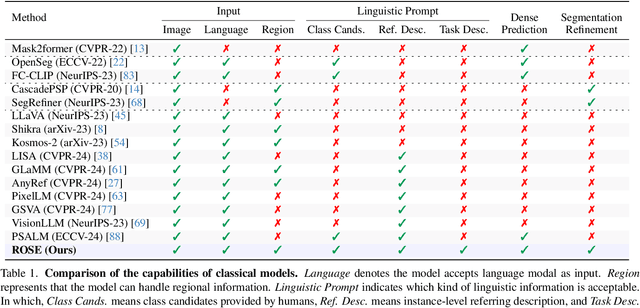
Add to EdgeWhen Better Codebooks Are Not Enough: Predictive Performance and Behavioral Reliability in LLM Political Event Coding
Jun 04, 2026High accuracy does not necessarily make an LLM a faithful coder. This issue matters because many social-science studies rely on expert-written codebooks to turn text into structured data. We study this problem in political event coding, a challenging source-target relation classification task beyond ordinary sentence-level classification, where models must determine what one actor did to another using detailed coding rules. We test whether expert codebooks become more effective when operationalized into LLM-friendly forms with clearer definitions, examples, retrieved context, and rules for difficult cases. We then evaluate behavioral reliability under controlled changes to label names, codebook order, and label-definition mappings. Clearer codebooks substantially improve classification performance, especially for fine-grained event classification. However, these predictive gains do not fully translate into behavioral reliability. Models may produce valid labels and recover definitions while still failing behavioral reliability tests under controlled codebook changes. These findings suggest that codebook-guided LLM systems should be evaluated not only by accuracy, but also by whether they preserve the coding logic that makes coded outputs meaningful for social-science research.
Can I Take Another Dose? Evaluating LLM Decision-Making Under Temporal Uncertainty in OTC Dosing QA
Jun 02, 2026Large language models (LLMs) are increasingly used for everyday health questions, including whether a user can safely take another dose of an over-the-counter (OTC) medication. Yet this common safety-relevant setting remains underexplored in existing medical QA evaluations, where correct answers require tracking dose timing, computing rolling 24-hour intake, following product-label constraints, and handling incomplete medication histories. We introduce DOSEBENCH, a focused benchmark of 81 curated OTC dosing scenarios focused on adult acetaminophen and ibuprofen use, with manually annotated gold references. We evaluate four LLMs across repeated runs using metrics for decision correctness, consistency, explanation verifiability, failure types, and confidence-related signals, resulting in 1,620 model responses. Our results show that models frequently struggle with rolling-window reasoning and ambiguity-sensitive cases and that stable or confident-looking responses can still violate dosing constraints. These findings suggest that OTC dosing QA provides a narrow yet practical testbed for evaluating temporal reasoning, constraint following, and safety-relevant uncertainty handling in medical QA.
Easier to Mislead Than to Correct: Harmful and Beneficial Revision in LLM Conformity
Jun 01, 2026Large language models are increasingly used in multi-agent systems, where they see and respond to other agents' answers. A key risk is conformity: a model may abandon its own answer simply because others agree on a different one. Prior studies show that LLMs often revise toward a majority answer, but it remains unclear whether these revisions help correct mistakes as often as they introduce new errors. In this paper, we conduct a controlled study in which an LLM first answers a question, then sees simulated peer responses before making a final decision. We manipulate two social cues: consensus structure and authority labels assigned to peers, and measure how they influence beneficial and harmful revisions. Across four open-weight LLMs and seven QA datasets, we find that peer agreement makes it much easier to mislead initially correct models than to correct initially wrong ones. Authority labels make models more likely to choose the endorsed answer, regardless of whether it is correct. More concerningly, generic reasoning interventions such as chain-of-thought and reflection do not reliably reduce harmful revision while preserving beneficial revision. These findings suggest that multi-agent LLM systems should verify peer answers rather than simply aggregate them.
Enabling Extensible Embodied Capabilities with Tools
May 26, 2026Most existing embodied intelligence methods formulate perception, reasoning, planning, and control within a unified parameterized policy. Yet these capabilities are inherently hierarchical and heterogeneous, making them difficult to reliably learn and modularize within a single model. We propose a capability externalization approach that decouples heterogeneous capabilities into independently optimized tools, dynamically invoked at inference time. To this end, we introduce Embodied Tool Protocol (ETP), a standardized protocol for embodied tool registration, discovery, invocation, and execution, and curate 100+ validated tools spanning perception, cognition, reasoning, and execution as the tool base. Building on this, we construct EmbodiedToolBench to evaluate both whether tool augmentation improves embodied performance and how well current models use tools across tool-necessity recognition, tool selection, tool execution, and tool-chain composition. Experiments across simulation and real-world platforms confirm that capability externalization consistently improves embodied performance (avg. gain 31% on EB-ALFRED and 36% on EB-Navigation), yet reveal a clear boundary: gains are substantial for cognition and perception but are limited for execution-type capabilities. Moreover, our analysis reveals that knowing when, which, and how to invoke tools remains a persistent challenge across all models, thereby highlighting embodied tool competence as a critical direction for future research.
Attention Grounded Enhancement for Visual Document Retrieval
Nov 17, 2025Visual document retrieval requires understanding heterogeneous and multi-modal content to satisfy information needs. Recent advances use screenshot-based document encoding with fine-grained late interaction, significantly improving retrieval performance. However, retrievers are still trained with coarse global relevance labels, without revealing which regions support the match. As a result, retrievers tend to rely on surface-level cues and struggle to capture implicit semantic connections, hindering their ability to handle non-extractive queries. To alleviate this problem, we propose a \textbf{A}ttention-\textbf{G}rounded \textbf{RE}triever \textbf{E}nhancement (AGREE) framework. AGREE leverages cross-modal attention from multimodal large language models as proxy local supervision to guide the identification of relevant document regions. During training, AGREE combines local signals with the global signals to jointly optimize the retriever, enabling it to learn not only whether documents match, but also which content drives relevance. Experiments on the challenging ViDoRe V2 benchmark show that AGREE significantly outperforms the global-supervision-only baseline. Quantitative and qualitative analyses further demonstrate that AGREE promotes deeper alignment between query terms and document regions, moving beyond surface-level matching toward more accurate and interpretable retrieval. Our code is available at: https://anonymous.4open.science/r/AGREE-2025.
The Influence of Text Variation on User Engagement in Cross-Platform Content Sharing
Apr 26, 2025In today's cross-platform social media landscape, understanding factors that drive engagement for multimodal content, especially text paired with visuals, remains complex. This study investigates how rewriting Reddit post titles adapted from YouTube video titles affects user engagement. First, we build and analyze a large dataset of Reddit posts sharing YouTube videos, revealing that 21% of post titles are minimally modified. Statistical analysis demonstrates that title rewrites measurably improve engagement. Second, we design a controlled, multi-phase experiment to rigorously isolate the effects of textual variations by neutralizing confounding factors like video popularity, timing, and community norms. Comprehensive statistical tests reveal that effective title rewrites tend to feature emotional resonance, lexical richness, and alignment with community-specific norms. Lastly, pairwise ranking prediction experiments using a fine-tuned BERT classifier achieves 74% accuracy, significantly outperforming near-random baselines, including GPT-4o. These results validate that our controlled dataset effectively minimizes confounding effects, allowing advanced models to both learn and demonstrate the impact of textual features on engagement. By bridging quantitative rigor with qualitative insights, this study uncovers engagement dynamics and offers a robust framework for future cross-platform, multimodal content strategies.
Ensuring Force Safety in Vision-Guided Robotic Manipulation via Implicit Tactile Calibration
Dec 13, 2024In dynamic environments, robots often encounter constrained movement trajectories when manipulating objects with specific properties, such as doors. Therefore, applying the appropriate force is crucial to prevent damage to both the robots and the objects. However, current vision-guided robot state generation methods often falter in this regard, as they lack the integration of tactile perception. To tackle this issue, this paper introduces a novel state diffusion framework termed SafeDiff. It generates a prospective state sequence from the current robot state and visual context observation while incorporating real-time tactile feedback to refine the sequence. As far as we know, this is the first study specifically focused on ensuring force safety in robotic manipulation. It significantly enhances the rationality of state planning, and the safe action trajectory is derived from inverse dynamics based on this refined planning. In practice, unlike previous approaches that concatenate visual and tactile data to generate future robot state sequences, our method employs tactile data as a calibration signal to adjust the robot's state within the state space implicitly. Additionally, we've developed a large-scale simulation dataset called SafeDoorManip50k, offering extensive multimodal data to train and evaluate the proposed method. Extensive experiments show that our visual-tactile model substantially mitigates the risk of harmful forces in the door opening, across both simulated and real-world settings.
ROSE: Revolutionizing Open-Set Dense Segmentation with Patch-Wise Perceptual Large Multimodal Model
Nov 29, 2024
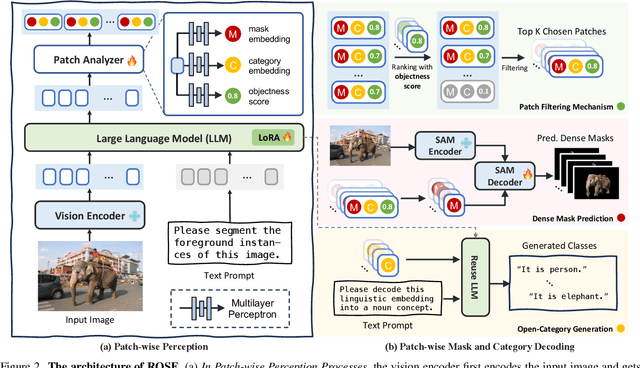
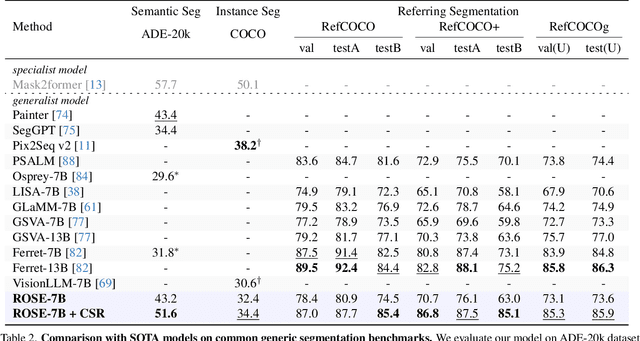
Advances in CLIP and large multimodal models (LMMs) have enabled open-vocabulary and free-text segmentation, yet existing models still require predefined category prompts, limiting free-form category self-generation. Most segmentation LMMs also remain confined to sparse predictions, restricting their applicability in open-set environments. In contrast, we propose ROSE, a Revolutionary Open-set dense SEgmentation LMM, which enables dense mask prediction and open-category generation through patch-wise perception. Our method treats each image patch as an independent region of interest candidate, enabling the model to predict both dense and sparse masks simultaneously. Additionally, a newly designed instruction-response paradigm takes full advantage of the generation and generalization capabilities of LMMs, achieving category prediction independent of closed-set constraints or predefined categories. To further enhance mask detail and category precision, we introduce a conversation-based refinement paradigm, integrating the prediction result from previous step with textual prompt for revision. Extensive experiments demonstrate that ROSE achieves competitive performance across various segmentation tasks in a unified framework. Code will be released.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024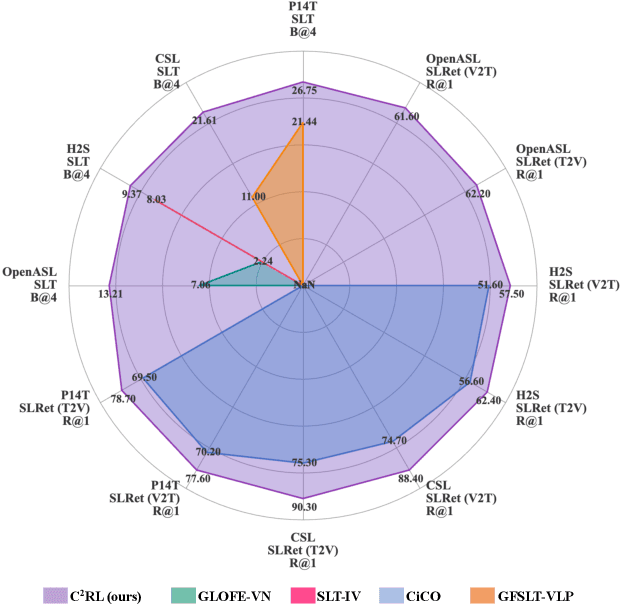
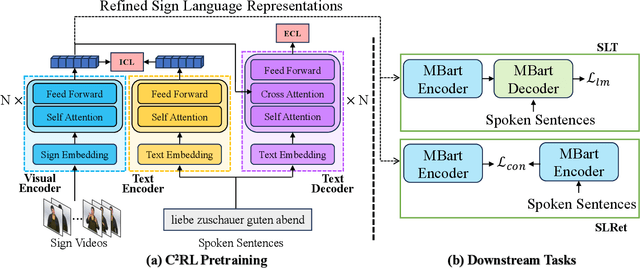
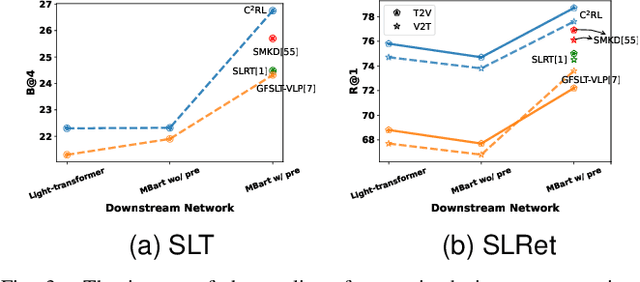
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
Oct 23, 2023Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically-derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions: correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.