 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024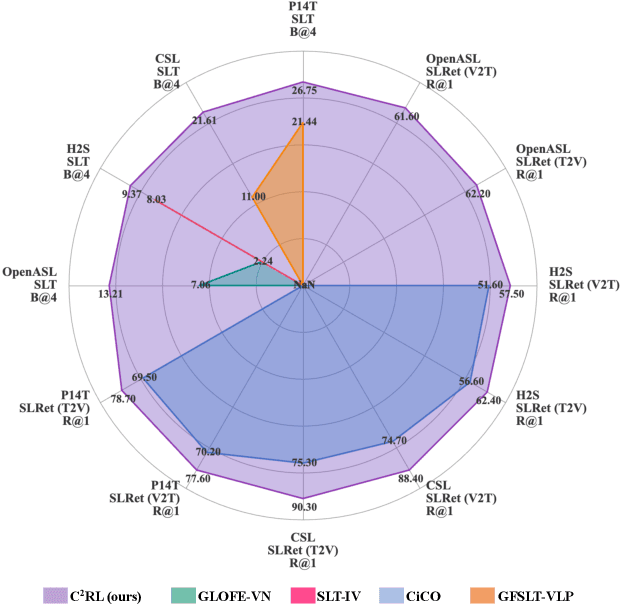
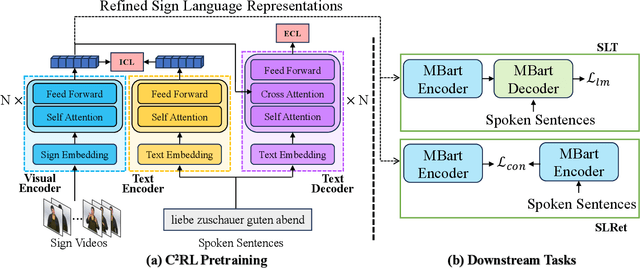
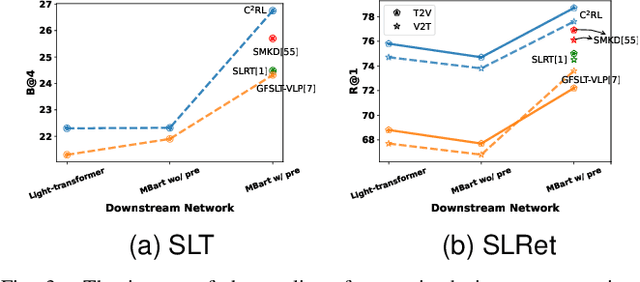
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
FeTT: Continual Class Incremental Learning via Feature Transformation Tuning
May 20, 2024Continual learning (CL) aims to extend deep models from static and enclosed environments to dynamic and complex scenarios, enabling systems to continuously acquire new knowledge of novel categories without forgetting previously learned knowledge. Recent CL models have gradually shifted towards the utilization of pre-trained models (PTMs) with parameter-efficient fine-tuning (PEFT) strategies. However, continual fine-tuning still presents a serious challenge of catastrophic forgetting due to the absence of previous task data. Additionally, the fine-tune-then-frozen mechanism suffers from performance limitations due to feature channels suppression and insufficient training data in the first CL task. To this end, this paper proposes feature transformation tuning (FeTT) model to non-parametrically fine-tune backbone features across all tasks, which not only operates independently of CL training data but also smooths feature channels to prevent excessive suppression. Then, the extended ensemble strategy incorporating different PTMs with FeTT model facilitates further performance improvement. We further elaborate on the discussions of the fine-tune-then-frozen paradigm and the FeTT model from the perspectives of discrepancy in class marginal distributions and feature channels. Extensive experiments on CL benchmarks validate the effectiveness of our proposed method.
Dynamic Feature Learning and Matching for Class-Incremental Learning
May 14, 2024Class-incremental learning (CIL) has emerged as a means to learn new classes incrementally without catastrophic forgetting of previous classes. Recently, CIL has undergone a paradigm shift towards dynamic architectures due to their superior performance. However, these models are still limited by the following aspects: (i) Data augmentation (DA), which are tightly coupled with CIL, remains under-explored in dynamic architecture scenarios. (ii) Feature representation. The discriminativeness of dynamic feature are sub-optimal and possess potential for refinement. (iii) Classifier. The misalignment between dynamic feature and classifier constrains the capabilities of the model. To tackle the aforementioned drawbacks, we propose the Dynamic Feature Learning and Matching (DFLM) model in this paper from above three perspectives. Specifically, we firstly introduce class weight information and non-stationary functions to extend the mix DA method for dynamically adjusting the focus on memory during training. Then, von Mises-Fisher (vMF) classifier is employed to effectively model the dynamic feature distribution and implicitly learn their discriminative properties. Finally, the matching loss is proposed to facilitate the alignment between the learned dynamic features and the classifier by minimizing the distribution distance. Extensive experiments on CIL benchmarks validate that our proposed model achieves significant performance improvements over existing methods.
Continual Learning on Graphs: A Survey
Feb 09, 2024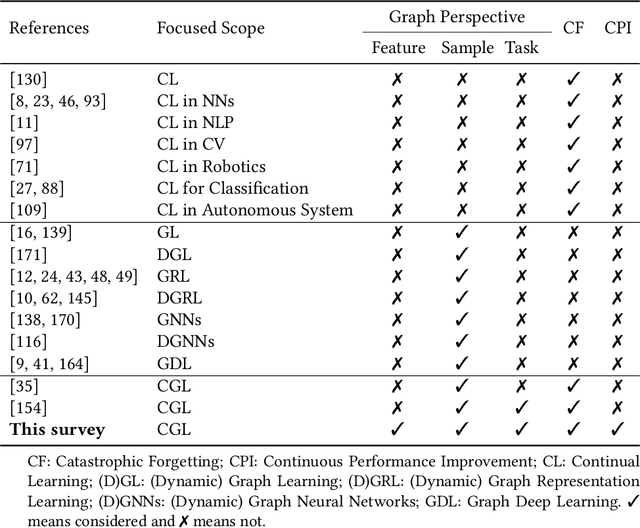
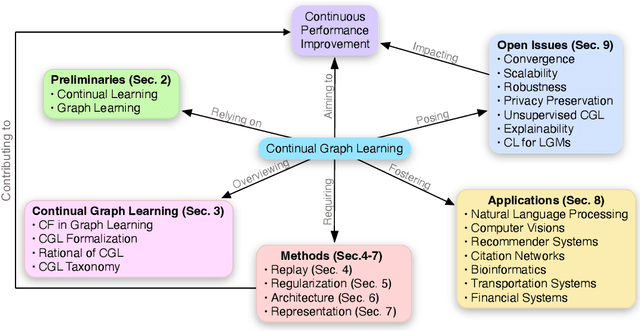
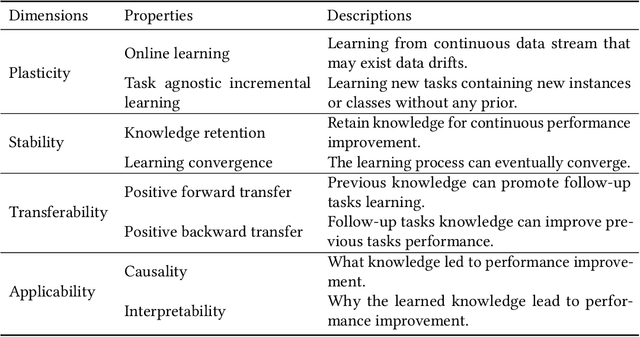
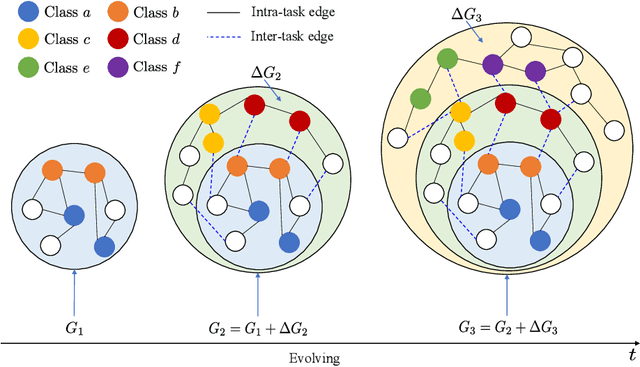
Recently, continual graph learning has been increasingly adopted for diverse graph-structured data processing tasks in non-stationary environments. Despite its promising learning capability, current studies on continual graph learning mainly focus on mitigating the catastrophic forgetting problem while ignoring continuous performance improvement. To bridge this gap, this article aims to provide a comprehensive survey of recent efforts on continual graph learning. Specifically, we introduce a new taxonomy of continual graph learning from the perspective of overcoming catastrophic forgetting. Moreover, we systematically analyze the challenges of applying these continual graph learning methods in improving performance continuously and then discuss the possible solutions. Finally, we present open issues and future directions pertaining to the development of continual graph learning and discuss how they impact continuous performance improvement.
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023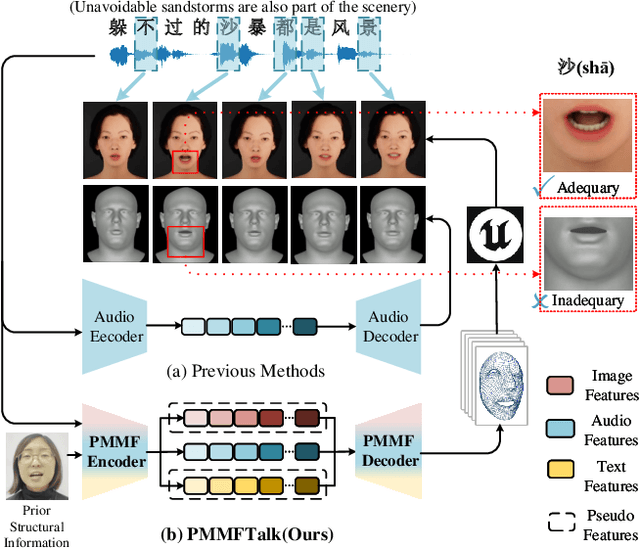
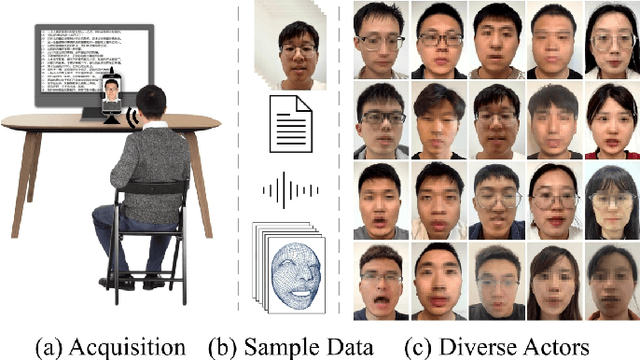
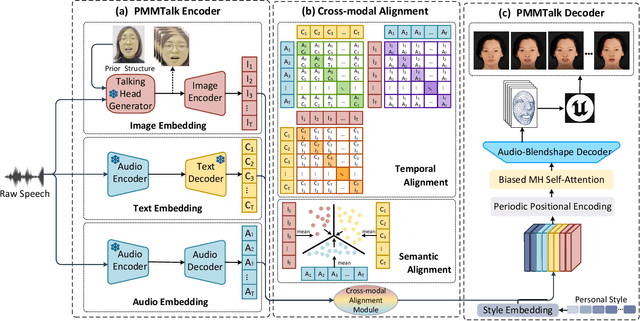
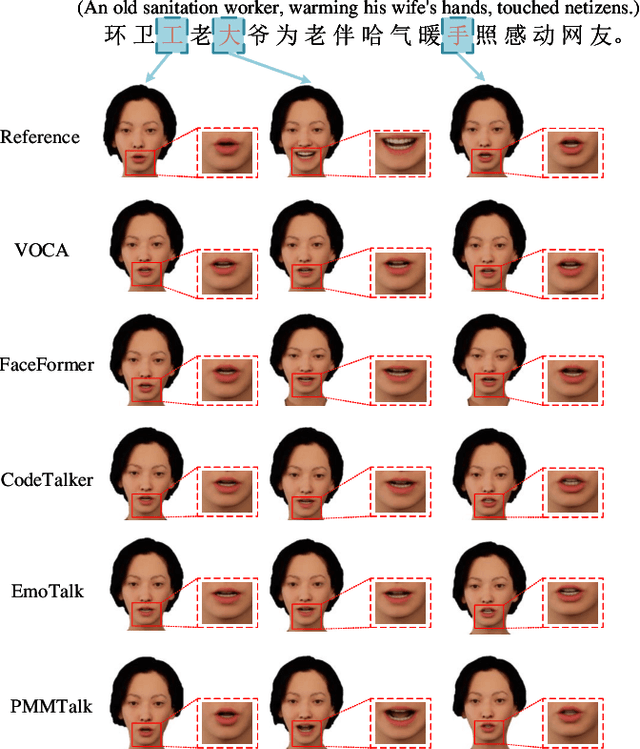
Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
Jul 27, 2023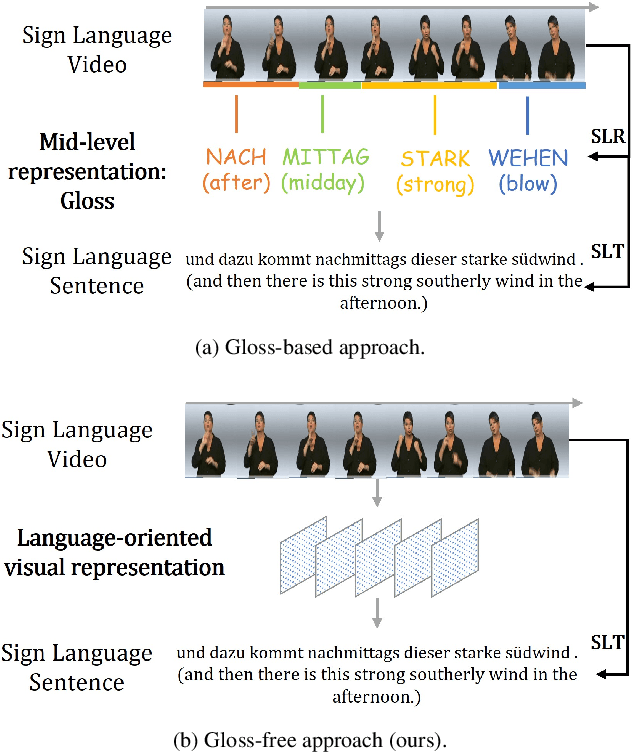
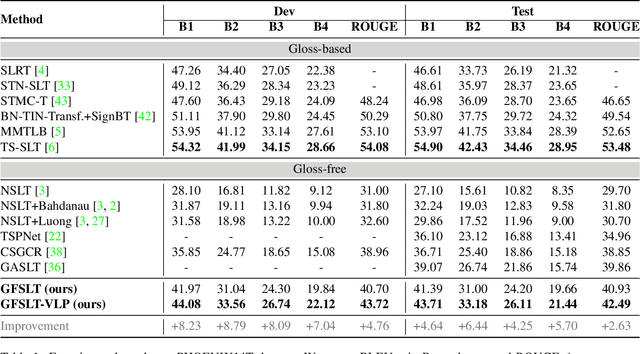
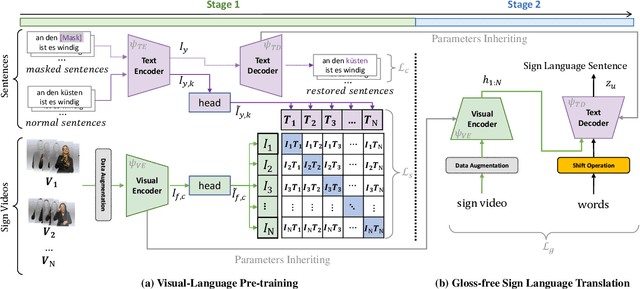

Sign Language Translation (SLT) is a challenging task due to its cross-domain nature, involving the translation of visual-gestural language to text. Many previous methods employ an intermediate representation, i.e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT). However, the scarcity of gloss-annotated sign language data, combined with the information bottleneck in the mid-level gloss representation, has hindered the further development of the SLT task. To address this challenge, we propose a novel Gloss-Free SLT based on Visual-Language Pretraining (GFSLT-VLP), which improves SLT by inheriting language-oriented prior knowledge from pre-trained models, without any gloss annotation assistance. Our approach involves two stages: (i) integrating Contrastive Language-Image Pre-training (CLIP) with masked self-supervised learning to create pre-tasks that bridge the semantic gap between visual and textual representations and restore masked sentences, and (ii) constructing an end-to-end architecture with an encoder-decoder-like structure that inherits the parameters of the pre-trained Visual Encoder and Text Decoder from the first stage. The seamless combination of these novel designs forms a robust sign language representation and significantly improves gloss-free sign language translation. In particular, we have achieved unprecedented improvements in terms of BLEU-4 score on the PHOENIX14T dataset (>+5) and the CSL-Daily dataset (>+3) compared to state-of-the-art gloss-free SLT methods. Furthermore, our approach also achieves competitive results on the PHOENIX14T dataset when compared with most of the gloss-based methods. Our code is available at https://github.com/zhoubenjia/GFSLT-VLP.
FM-ViT: Flexible Modal Vision Transformers for Face Anti-Spoofing
May 05, 2023The availability of handy multi-modal (i.e., RGB-D) sensors has brought about a surge of face anti-spoofing research. However, the current multi-modal face presentation attack detection (PAD) has two defects: (1) The framework based on multi-modal fusion requires providing modalities consistent with the training input, which seriously limits the deployment scenario. (2) The performance of ConvNet-based model on high fidelity datasets is increasingly limited. In this work, we present a pure transformer-based framework, dubbed the Flexible Modal Vision Transformer (FM-ViT), for face anti-spoofing to flexibly target any single-modal (i.e., RGB) attack scenarios with the help of available multi-modal data. Specifically, FM-ViT retains a specific branch for each modality to capture different modal information and introduces the Cross-Modal Transformer Block (CMTB), which consists of two cascaded attentions named Multi-headed Mutual-Attention (MMA) and Fusion-Attention (MFA) to guide each modal branch to mine potential features from informative patch tokens, and to learn modality-agnostic liveness features by enriching the modal information of own CLS token, respectively. Experiments demonstrate that the single model trained based on FM-ViT can not only flexibly evaluate different modal samples, but also outperforms existing single-modal frameworks by a large margin, and approaches the multi-modal frameworks introduced with smaller FLOPs and model parameters.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021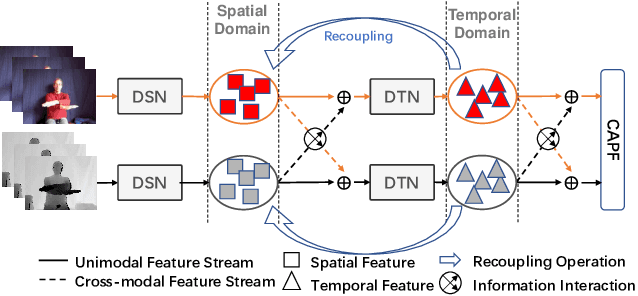
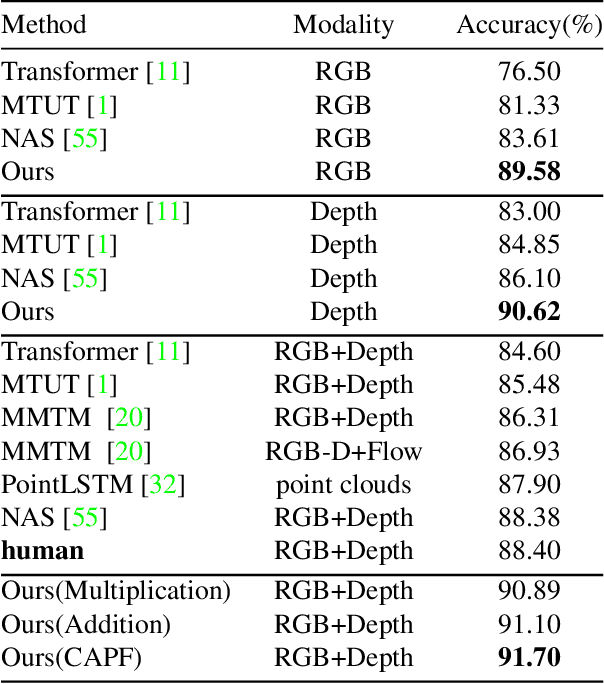
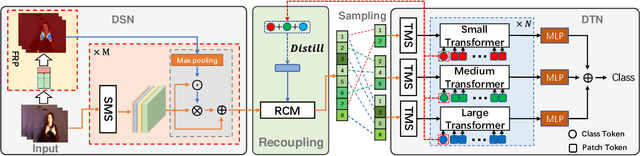
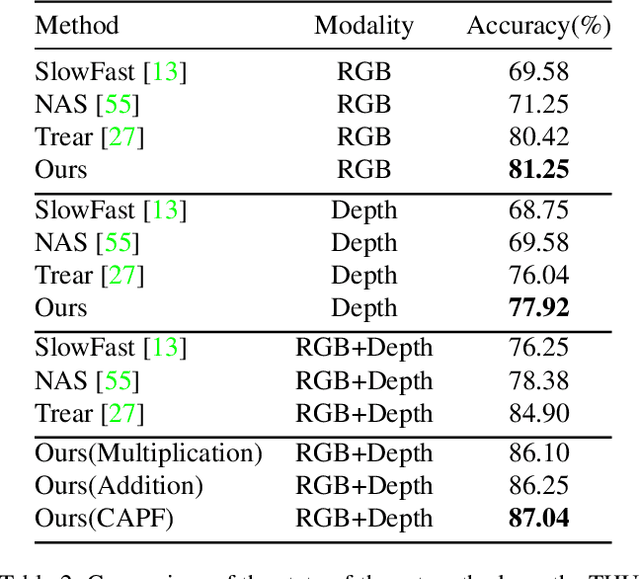
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
Apr 13, 2021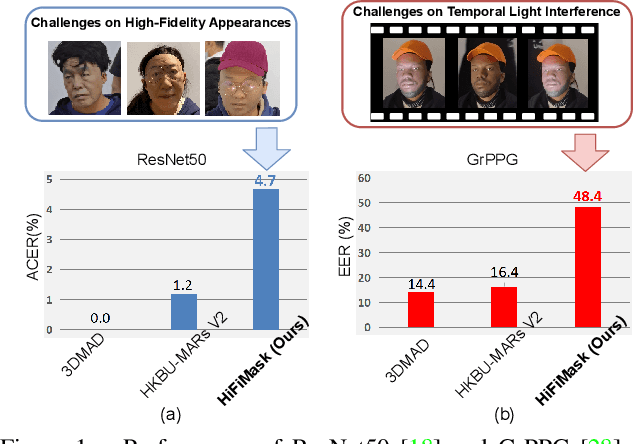
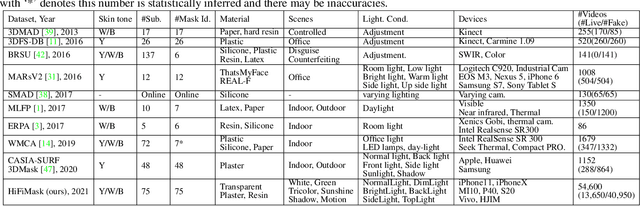

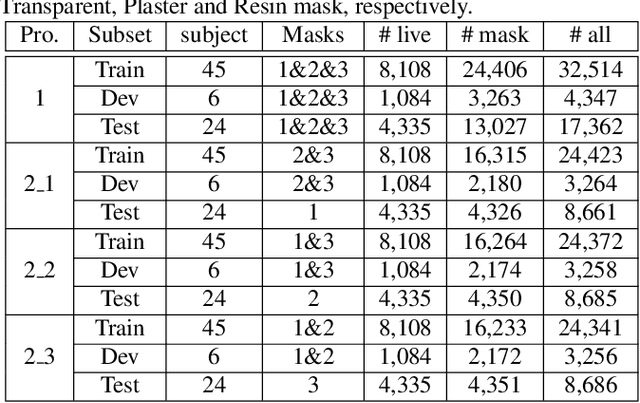
Face presentation attack detection (PAD) is essential to secure face recognition systems primarily from high-fidelity mask attacks. Most existing 3D mask PAD benchmarks suffer from several drawbacks: 1) a limited number of mask identities, types of sensors, and a total number of videos; 2) low-fidelity quality of facial masks. Basic deep models and remote photoplethysmography (rPPG) methods achieved acceptable performance on these benchmarks but still far from the needs of practical scenarios. To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask). Specifically, a total amount of 54,600 videos are recorded from 75 subjects with 225 realistic masks by 7 new kinds of sensors. Together with the dataset, we propose a novel Contrastive Context-aware Learning framework, namely CCL. CCL is a new training methodology for supervised PAD tasks, which is able to learn by leveraging rich contexts accurately (e.g., subjects, mask material and lighting) among pairs of live faces and high-fidelity mask attacks. Extensive experimental evaluations on HiFiMask and three additional 3D mask datasets demonstrate the effectiveness of our method.