 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025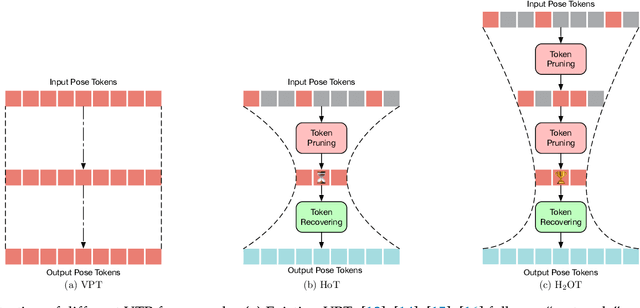

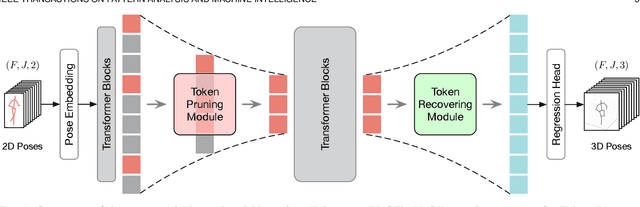

Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
Training-Free Text-Guided Image Editing with Visual Autoregressive Model
Mar 31, 2025Text-guided image editing is an essential task that enables users to modify images through natural language descriptions. Recent advances in diffusion models and rectified flows have significantly improved editing quality, primarily relying on inversion techniques to extract structured noise from input images. However, inaccuracies in inversion can propagate errors, leading to unintended modifications and compromising fidelity. Moreover, even with perfect inversion, the entanglement between textual prompts and image features often results in global changes when only local edits are intended. To address these challenges, we propose a novel text-guided image editing framework based on VAR (Visual AutoRegressive modeling), which eliminates the need for explicit inversion while ensuring precise and controlled modifications. Our method introduces a caching mechanism that stores token indices and probability distributions from the original image, capturing the relationship between the source prompt and the image. Using this cache, we design an adaptive fine-grained masking strategy that dynamically identifies and constrains modifications to relevant regions, preventing unintended changes. A token reassembling approach further refines the editing process, enhancing diversity, fidelity, and control. Our framework operates in a training-free manner and achieves high-fidelity editing with faster inference speeds, processing a 1K resolution image in as fast as 1.2 seconds. Extensive experiments demonstrate that our method achieves performance comparable to, or even surpassing, existing diffusion- and rectified flow-based approaches in both quantitative metrics and visual quality. The code will be released.
CRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
FlexDiT: Dynamic Token Density Control for Diffusion Transformer
Dec 08, 2024



Diffusion Transformers (DiT) deliver impressive generative performance but face prohibitive computational demands due to both the quadratic complexity of token-based self-attention and the need for extensive sampling steps. While recent research has focused on accelerating sampling, the structural inefficiencies of DiT remain underexplored. We propose FlexDiT, a framework that dynamically adapts token density across both spatial and temporal dimensions to achieve computational efficiency without compromising generation quality. Spatially, FlexDiT employs a three-segment architecture that allocates token density based on feature requirements at each layer: Poolingformer in the bottom layers for efficient global feature extraction, Sparse-Dense Token Modules (SDTM) in the middle layers to balance global context with local detail, and dense tokens in the top layers to refine high-frequency details. Temporally, FlexDiT dynamically modulates token density across denoising stages, progressively increasing token count as finer details emerge in later timesteps. This synergy between FlexDiT's spatially adaptive architecture and its temporal pruning strategy enables a unified framework that balances efficiency and fidelity throughout the generation process. Our experiments demonstrate FlexDiT's effectiveness, achieving a 55% reduction in FLOPs and a 175% improvement in inference speed on DiT-XL with only a 0.09 increase in FID score on 512$\times$512 ImageNet images, a 56% reduction in FLOPs across video generation datasets including FaceForensics, SkyTimelapse, UCF101, and Taichi-HD, and a 69% improvement in inference speed on PixArt-$\alpha$ on text-to-image generation task with a 0.24 FID score decrease. FlexDiT provides a scalable solution for high-quality diffusion-based generation compatible with further sampling optimization techniques.
Factorized Visual Tokenization and Generation
Nov 25, 2024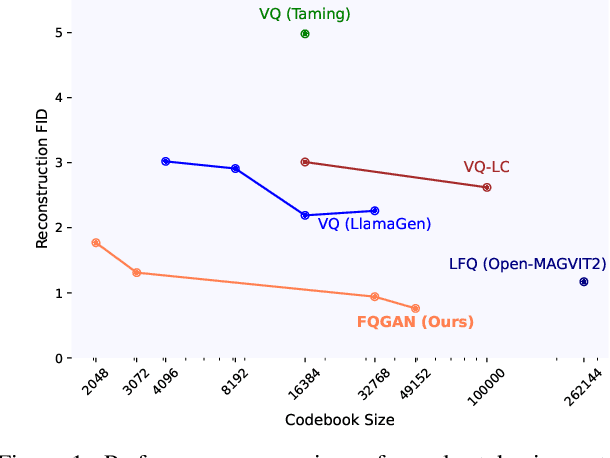
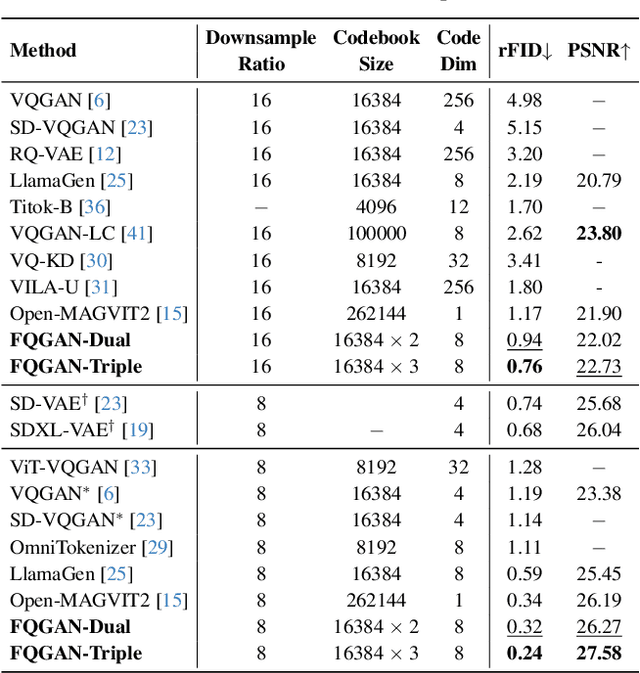
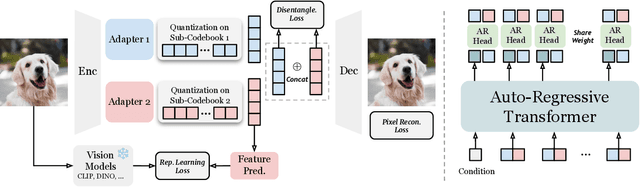
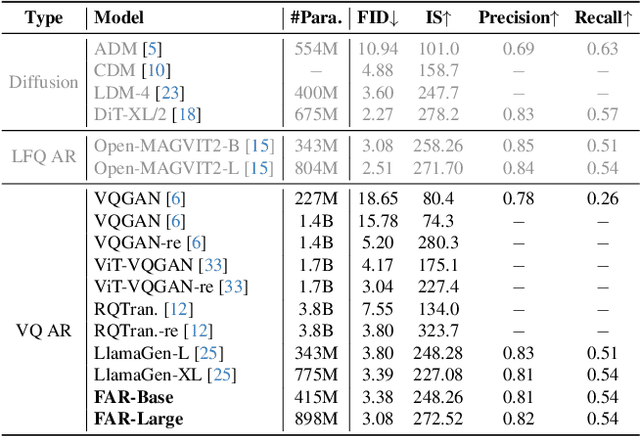
Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN
Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning
Oct 31, 2024



Despite advancements in Text-to-Video (T2V) generation, producing videos with realistic motion remains challenging. Current models often yield static or minimally dynamic outputs, failing to capture complex motions described by text. This issue stems from the internal biases in text encoding, which overlooks motions, and inadequate conditioning mechanisms in T2V generation models. To address this, we propose a novel framework called DEcomposed MOtion (DEMO), which enhances motion synthesis in T2V generation by decomposing both text encoding and conditioning into content and motion components. Our method includes a content encoder for static elements and a motion encoder for temporal dynamics, alongside separate content and motion conditioning mechanisms. Crucially, we introduce text-motion and video-motion supervision to improve the model's understanding and generation of motion. Evaluations on benchmarks such as MSR-VTT, UCF-101, WebVid-10M, EvalCrafter, and VBench demonstrate DEMO's superior ability to produce videos with enhanced motion dynamics while maintaining high visual quality. Our approach significantly advances T2V generation by integrating comprehensive motion understanding directly from textual descriptions. Project page: https://PR-Ryan.github.io/DEMO-project/
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos
Sep 29, 2024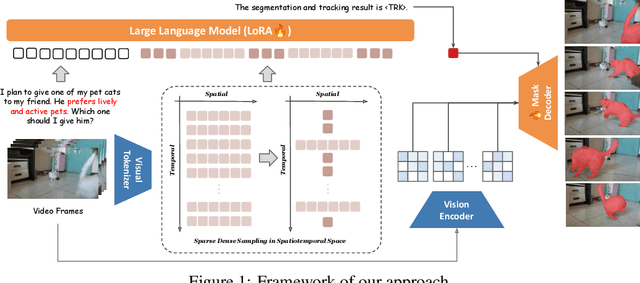
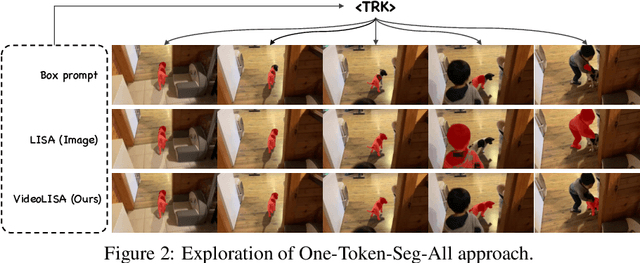


We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions. Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints. Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames. Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA's superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking. While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation. Code and model will be available at: https://github.com/showlab/VideoLISA.
GQE: Generalized Query Expansion for Enhanced Text-Video Retrieval
Aug 14, 2024In the rapidly expanding domain of web video content, the task of text-video retrieval has become increasingly critical, bridging the semantic gap between textual queries and video data. This paper introduces a novel data-centric approach, Generalized Query Expansion (GQE), to address the inherent information imbalance between text and video, enhancing the effectiveness of text-video retrieval systems. Unlike traditional model-centric methods that focus on designing intricate cross-modal interaction mechanisms, GQE aims to expand the text queries associated with videos both during training and testing phases. By adaptively segmenting videos into short clips and employing zero-shot captioning, GQE enriches the training dataset with comprehensive scene descriptions, effectively bridging the data imbalance gap. Furthermore, during retrieval, GQE utilizes Large Language Models (LLM) to generate a diverse set of queries and a query selection module to filter these queries based on relevance and diversity, thus optimizing retrieval performance while reducing computational overhead. Our contributions include a detailed examination of the information imbalance challenge, a novel approach to query expansion in video-text datasets, and the introduction of a query selection strategy that enhances retrieval accuracy without increasing computational costs. GQE achieves state-of-the-art performance on several benchmarks, including MSR-VTT, MSVD, LSMDC, and VATEX, demonstrating the effectiveness of addressing text-video retrieval from a data-centric perspective.
Hallucination of Multimodal Large Language Models: A Survey
Apr 29, 2024



This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.