 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Interpretable mixture of experts for time series prediction under recurrent and non-recurrent conditions
Sep 05, 2024



Non-recurrent conditions caused by incidents are different from recurrent conditions that follow periodic patterns. Existing traffic speed prediction studies are incident-agnostic and use one single model to learn all possible patterns from these drastically diverse conditions. This study proposes a novel Mixture of Experts (MoE) model to improve traffic speed prediction under two separate conditions, recurrent and non-recurrent (i.e., with and without incidents). The MoE leverages separate recurrent and non-recurrent expert models (Temporal Fusion Transformers) to capture the distinct patterns of each traffic condition. Additionally, we propose a training pipeline for non-recurrent models to remedy the limited data issues. To train our model, multi-source datasets, including traffic speed, incident reports, and weather data, are integrated and processed to be informative features. Evaluations on a real road network demonstrate that the MoE achieves lower errors compared to other benchmark algorithms. The model predictions are interpreted in terms of temporal dependencies and variable importance in each condition separately to shed light on the differences between recurrent and non-recurrent conditions.
Real-time system optimal traffic routing under uncertainties -- Can physics models boost reinforcement learning?
Jul 10, 2024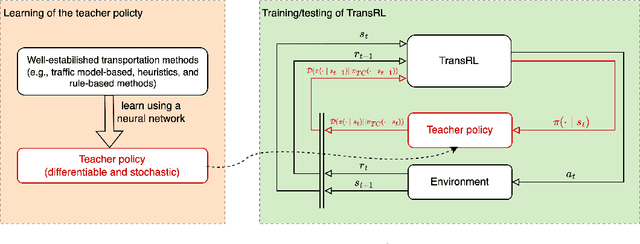
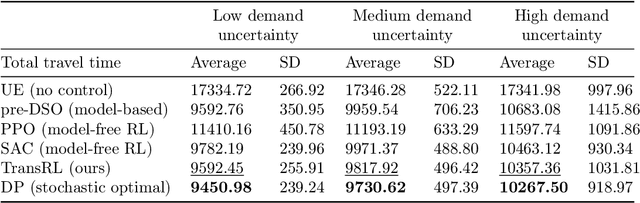
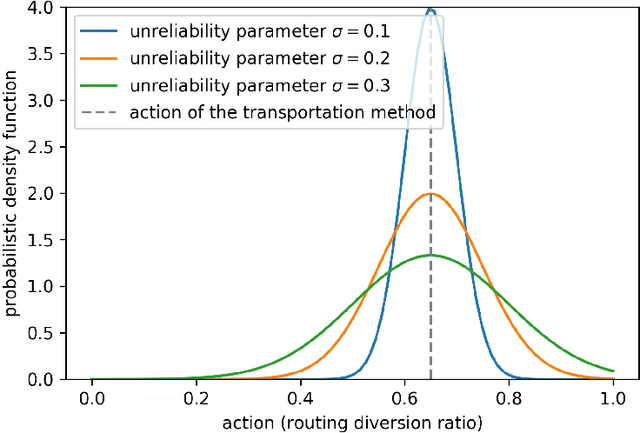
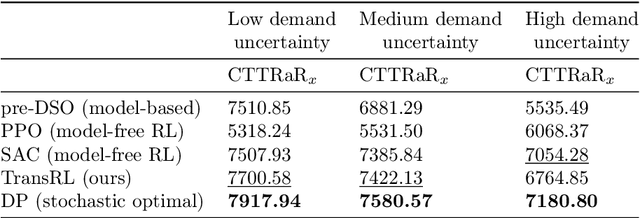
System optimal traffic routing can mitigate congestion by assigning routes for a portion of vehicles so that the total travel time of all vehicles in the transportation system can be reduced. However, achieving real-time optimal routing poses challenges due to uncertain demands and unknown system dynamics, particularly in expansive transportation networks. While physics model-based methods are sensitive to uncertainties and model mismatches, model-free reinforcement learning struggles with learning inefficiencies and interpretability issues. Our paper presents TransRL, a novel algorithm that integrates reinforcement learning with physics models for enhanced performance, reliability, and interpretability. TransRL begins by establishing a deterministic policy grounded in physics models, from which it learns from and is guided by a differentiable and stochastic teacher policy. During training, TransRL aims to maximize cumulative rewards while minimizing the Kullback Leibler (KL) divergence between the current policy and the teacher policy. This approach enables TransRL to simultaneously leverage interactions with the environment and insights from physics models. We conduct experiments on three transportation networks with up to hundreds of links. The results demonstrate TransRL's superiority over traffic model-based methods for being adaptive and learning from the actual network data. By leveraging the information from physics models, TransRL consistently outperforms state-of-the-art reinforcement learning algorithms such as proximal policy optimization (PPO) and soft actor critic (SAC). Moreover, TransRL's actions exhibit higher reliability and interpretability compared to baseline reinforcement learning approaches like PPO and SAC.