 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeled TrustSet Guided: Batch Active Learning with Reinforcement Learning
Apr 14, 2026Batch active learning (BAL) is a crucial technique for reducing labeling costs and improving data efficiency in training large-scale deep learning models. Traditional BAL methods often rely on metrics like Mahalanobis Distance to balance uncertainty and diversity when selecting data for annotation. However, these methods predominantly focus on the distribution of unlabeled data and fail to leverage feedback from labeled data or the model's performance. To address these limitations, we introduce TrustSet, a novel approach that selects the most informative data from the labeled dataset, ensuring a balanced class distribution to mitigate the long-tail problem. Unlike CoreSet, which focuses on maintaining the overall data distribution, TrustSet optimizes the model's performance by pruning redundant data and using label information to refine the selection process. To extend the benefits of TrustSet to the unlabeled pool, we propose a reinforcement learning (RL)-based sampling policy that approximates the selection of high-quality TrustSet candidates from the unlabeled data. Combining TrustSet and RL, we introduce the Batch Reinforcement Active Learning with TrustSet (BRAL-T) framework. BRAL-T achieves state-of-the-art results across 10 image classification benchmarks and 2 active fine-tuning tasks, demonstrating its effectiveness and efficiency in various domains.
DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
Apr 13, 2025Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.
CRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Exploring the Edges of Latent State Clusters for Goal-Conditioned Reinforcement Learning
Nov 03, 2024Exploring unknown environments efficiently is a fundamental challenge in unsupervised goal-conditioned reinforcement learning. While selecting exploratory goals at the frontier of previously explored states is an effective strategy, the policy during training may still have limited capability of reaching rare goals on the frontier, resulting in reduced exploratory behavior. We propose "Cluster Edge Exploration" ($CE^2$), a new goal-directed exploration algorithm that when choosing goals in sparsely explored areas of the state space gives priority to goal states that remain accessible to the agent. The key idea is clustering to group states that are easily reachable from one another by the current policy under training in a latent space and traversing to states holding significant exploration potential on the boundary of these clusters before doing exploratory behavior. In challenging robotics environments including navigating a maze with a multi-legged ant robot, manipulating objects with a robot arm on a cluttered tabletop, and rotating objects in the palm of an anthropomorphic robotic hand, $CE^2$ demonstrates superior efficiency in exploration compared to baseline methods and ablations.
Talking-head Generation with Rhythmic Head Motion
Jul 16, 2020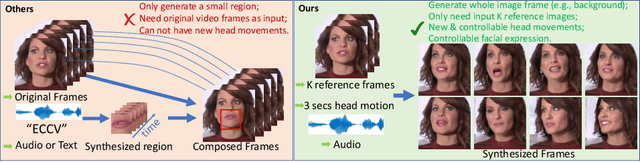
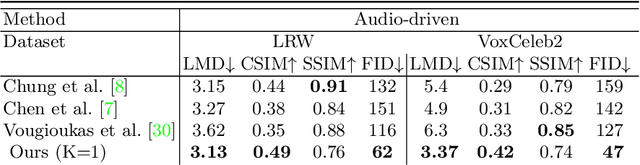
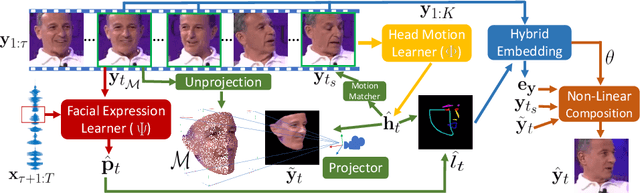
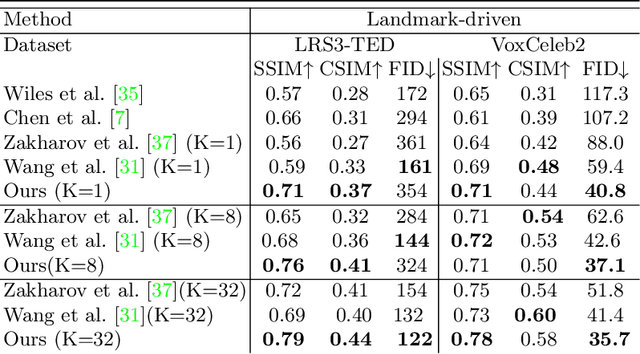
When people deliver a speech, they naturally move heads, and this rhythmic head motion conveys prosodic information. However, generating a lip-synced video while moving head naturally is challenging. While remarkably successful, existing works either generate still talkingface videos or rely on landmark/video frames as sparse/dense mapping guidance to generate head movements, which leads to unrealistic or uncontrollable video synthesis. To overcome the limitations, we propose a 3D-aware generative network along with a hybrid embedding module and a non-linear composition module. Through modeling the head motion and facial expressions1 explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. Thoughtful experiments on several standard benchmarks demonstrate that our method achieves significantly better results than the state-of-the-art methods in both quantitative and qualitative comparisons. The code is available on https://github.com/ lelechen63/Talking-head-Generation-with-Rhythmic-Head-Motion.
What comprises a good talking-head video generation?: A Survey and Benchmark
May 07, 2020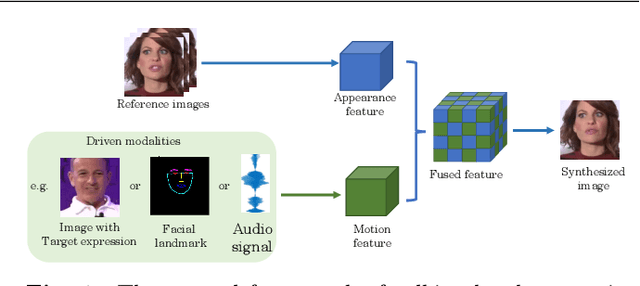
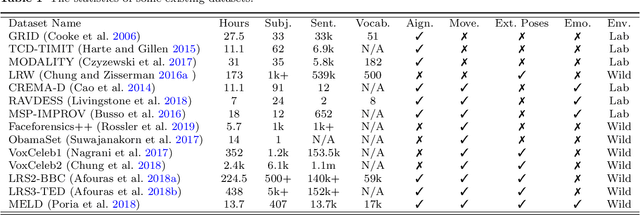
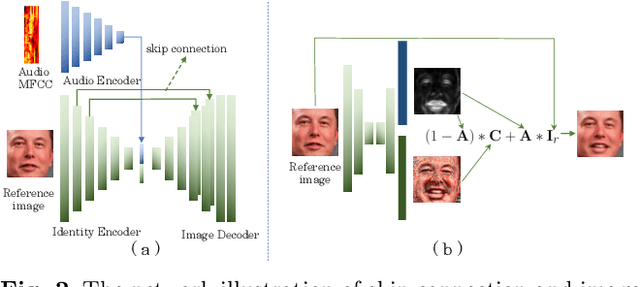

Over the years, performance evaluation has become essential in computer vision, enabling tangible progress in many sub-fields. While talking-head video generation has become an emerging research topic, existing evaluations on this topic present many limitations. For example, most approaches use human subjects (e.g., via Amazon MTurk) to evaluate their research claims directly. This subjective evaluation is cumbersome, unreproducible, and may impend the evolution of new research. In this work, we present a carefully-designed benchmark for evaluating talking-head video generation with standardized dataset pre-processing strategies. As for evaluation, we either propose new metrics or select the most appropriate ones to evaluate results in what we consider as desired properties for a good talking-head video, namely, identity preserving, lip synchronization, high video quality, and natural-spontaneous motion. By conducting a thoughtful analysis across several state-of-the-art talking-head generation approaches, we aim to uncover the merits and drawbacks of current methods and point out promising directions for future work. All the evaluation code is available at: https://github.com/lelechen63/talking-head-generation-survey.
Weakly Supervised Object Localization with Inter-Intra Regulated CAMs
Nov 19, 2019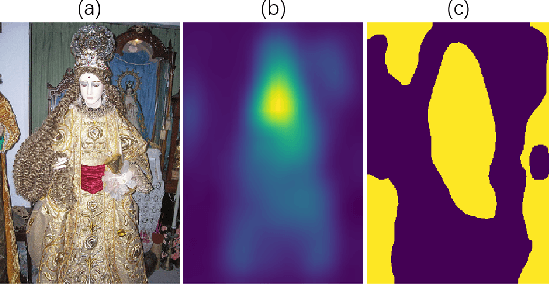
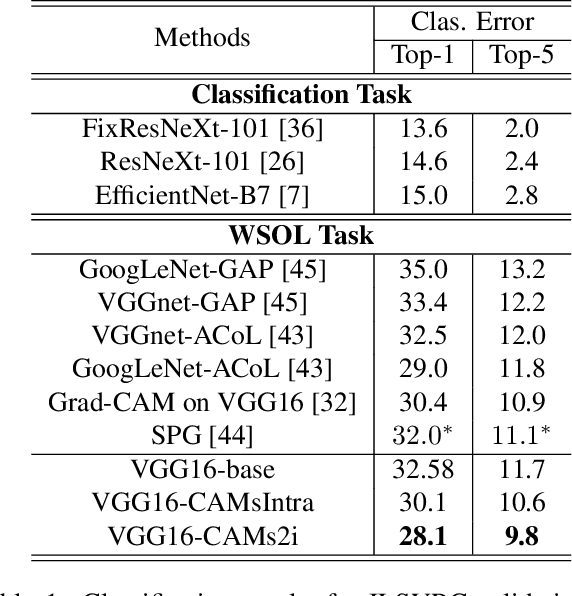
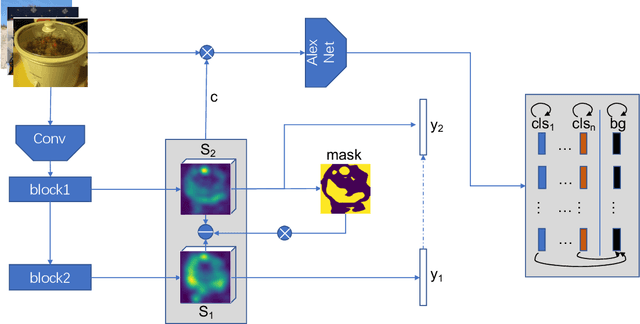
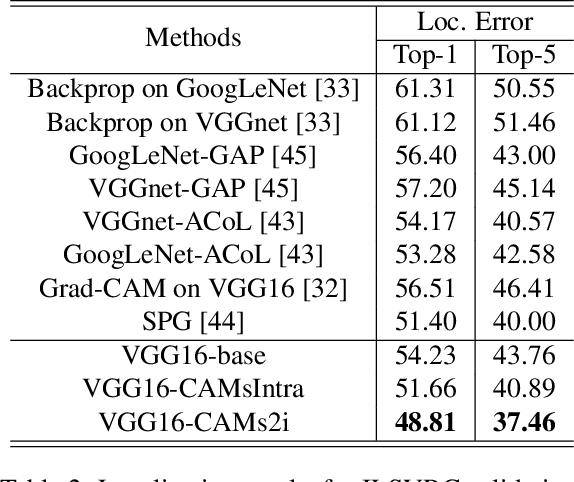
Weakly supervised object localization (WSOL) aims to locate objects in images by learning only from image-level labels. Current methods are trying to obtain localization results relying on Class Activation Maps (CAMs). Usually, they propose additional CAMs or feature maps generated from internal layers of deep networks to encourage different CAMs to be either \textbf{adversarial} or \textbf{cooperated} with each other. In this work, instead of following one of the two main approaches before, we analyze their internal relationship and propose a novel intra-sample strategy which regulates two CAMs of the same sample, generated from different classifiers, to dynamically adapt each of their pixels involved in adversarial or cooperative process based on their own values. We mathematically demonstrate that our approach is a more general version of the current state-of-the-art method with less hyper-parameters. Besides, we further develop an inter-sample criterion module for our WSOL task, which is originally proposed in co-segmentation problems, to refine generated CAMs of each sample. The module considers a subgroup of samples under the same category and regulates their object regions. With experiment on two widely-used datasets, we show that our proposed method significantly outperforms existing state-of-the-art, setting a new record for weakly-supervised object localization.
Weakly Supervised Localization Using Background Images
Sep 11, 2019
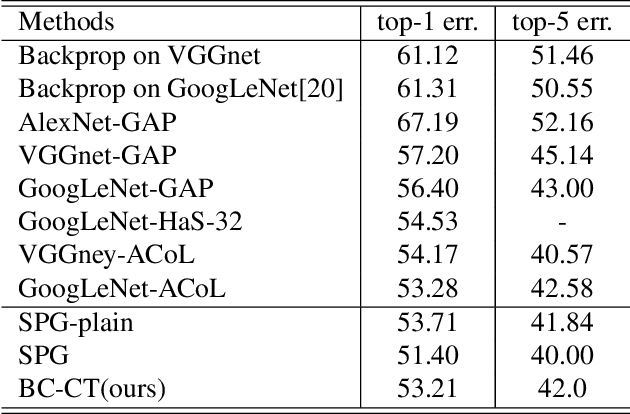
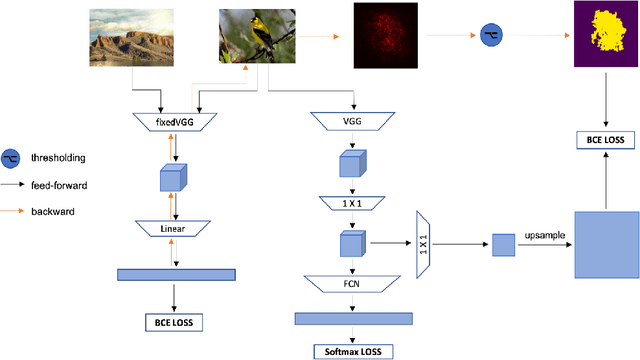
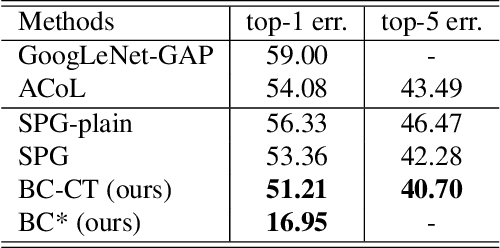
Weakly Supervised Object Localization (WSOL) methodsusually rely on fully convolutional networks in order to ob-tain class activation maps(CAMs) of targeted labels. How-ever, these networks always highlight the most discriminativeparts to perform the task, the located areas are much smallerthan entire targeted objects. In this work, we propose a novelend-to-end model to enlarge CAMs generated from classifi-cation models, which can localize targeted objects more pre-cisely. In detail, we add an additional module in traditionalclassification networks to extract foreground object propos-als from images without classifying them into specific cate-gories. Then we set these normalized regions as unrestrictedpixel-level mask supervision for the following classificationtask. We collect a set of images defined as Background ImageSet from the Internet. The number of them is much smallerthan the targeted dataset but surprisingly well supports themethod to extract foreground regions from different pictures.The region extracted is independent from classification task,where the extracted region in each image covers almost en-tire object rather than just a significant part. Therefore, theseregions can serve as masks to supervise the response mapgenerated from classification models to become larger andmore precise. The method achieves state-of-the-art results onCUB-200-2011 in terms of Top-1 and Top-5 localization er-ror while has a competitive result on ILSVRC2016 comparedwith other approaches.