 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What to Solve Before How: Preplan Empowered LLM Mathematical Reasoning
May 28, 2026Current plan-based reasoning methods improve large language models (LLMs) by inserting a planning stage before execution, giving rise to the question $\rightarrow$ plan $\rightarrow$ cot paradigm. While effective, a closer examination reveals an inherent paradigm-level gap: both the planning and its execution stages decide how to solve a problem, while the prior question of what to solve; recognizing the problem type, the applicable tools, and the foreseeable pitfalls; remains entirely implicit. To bridge this gap, we propose PPC (Preplan-Plan-CoT), a framework that introduces an explicit problem-understanding stage, the preplan, yielding a new question $\rightarrow$ preplan $\rightarrow$ plan $\rightarrow$ cot paradigm. Realizing this paradigm requires safeguarding the conceptual integrity of preplan at both ends. Specifically, we design a three-stage synthesis pipeline with a spoiler-score detector that filters out leakage and spoiler failures to build clean preplan supervision, and a composite GRPO reward enforces that the generated plan genuinely follows from the preplan. Experiments across four backbones and five mathematical reasoning benchmarks show that PPC achieves the best results on 39 of 40 metrics, improving maj@16 and pass@16 by +2.23 and +3.06 over the strongest baseline without introducing additional inference token overhead.
From Meta-Thought to Execution: Cognitively Aligned Post-Training for Generalizable and Reliable LLM Reasoning
Jan 29, 2026Current LLM post-training methods optimize complete reasoning trajectories through Supervised Fine-Tuning (SFT) followed by outcome-based Reinforcement Learning (RL). While effective, a closer examination reveals a fundamental gap: this approach does not align with how humans actually solve problems. Human cognition naturally decomposes problem-solving into two distinct stages: first acquiring abstract strategies (i.e., meta-knowledge) that generalize across problems, then adapting them to specific instances. In contrast, by treating complete trajectories as basic units, current methods are inherently problem-centric, entangling abstract strategies with problem-specific execution. To address this misalignment, we propose a cognitively-inspired framework that explicitly mirrors the two-stage human cognitive process. Specifically, Chain-of-Meta-Thought (CoMT) focuses supervised learning on abstract reasoning patterns without specific executions, enabling acquisition of generalizable strategies. Confidence-Calibrated Reinforcement Learning (CCRL) then optimizes task adaptation via confidence-aware rewards on intermediate steps, preventing overconfident errors from cascading and improving execution reliability. Experiments across four models and eight benchmarks show 2.19\% and 4.63\% improvements in-distribution and out-of-distribution respectively over standard methods, while reducing training time by 65-70% and token consumption by 50%, demonstrating that aligning post-training with human cognitive principles yields not only superior generalization but also enhanced training efficiency.
From Implicit to Explicit: Token-Efficient Logical Supervision for Mathematical Reasoning in LLMs
Jan 07, 2026Recent studies reveal that large language models (LLMs) exhibit limited logical reasoning abilities in mathematical problem-solving, instead often relying on pattern-matching and memorization. We systematically analyze this limitation, focusing on logical relationship understanding, which is a core capability underlying genuine logical reasoning, and reveal that errors related to this capability account for over 90\% of incorrect predictions, with Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) failing to substantially reduce these errors. To address this bottleneck, we propose First-Step Logical Reasoning (FSLR), a lightweight training framework targeting logical relationship understanding. Our key insight is that the first planning step-identifying which variables to use and which operation to apply-encourages the model to derive logical relationships directly from the problem statement. By training models on this isolated step, FSLR provides explicit supervision for logical relationship understanding, unlike CoT-SFT which implicitly embeds such relationships within complete solution trajectories. Extensive experiments across multiple models and datasets demonstrate that FSLR consistently outperforms CoT-SFT under both in-distribution and out-of-distribution settings, with average improvements of 3.2\% and 4.6\%, respectively. Moreover, FSLR achieves 4-6x faster training and reduces training token consumption by over 80\%.
Rethinking the Understanding Ability across LLMs through Mutual Information
May 25, 2025Recent advances in large language models (LLMs) have revolutionized natural language processing, yet evaluating their intrinsic linguistic understanding remains challenging. Moving beyond specialized evaluation tasks, we propose an information-theoretic framework grounded in mutual information (MI) to achieve this. We formalize the understanding as MI between an input sentence and its latent representation (sentence-level MI), measuring how effectively input information is preserved in latent representation. Given that LLMs learn embeddings for individual tokens, we decompose sentence-level MI into token-level MI between tokens and sentence embeddings, establishing theoretical bounds connecting these measures. Based on this foundation, we theoretically derive a computable lower bound for token-level MI using Fano's inequality, which directly relates to token-level recoverability-the ability to predict original tokens from sentence embedding. We implement this recoverability task to comparatively measure MI across different LLMs, revealing that encoder-only models consistently maintain higher information fidelity than their decoder-only counterparts, with the latter exhibiting a distinctive late-layer "forgetting" pattern where mutual information is first enhanced and then discarded. Moreover, fine-tuning to maximize token-level recoverability consistently improves understanding ability of LLMs on tasks without task-specific supervision, demonstrating that mutual information can serve as a foundation for understanding and improving language model capabilities.
SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Apr 22, 2025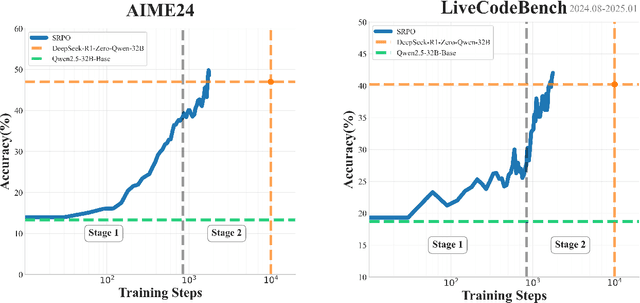



Recent advances of reasoning models, exemplified by OpenAI's o1 and DeepSeek's R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B), using only about 1/10 of the training steps required by DeepSeek-R1-Zero-32B, demonstrating superior efficiency. Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, offering valuable insights into scaling LLM reasoning capabilities across diverse tasks.
Graph Structure Prompt Learning: A Novel Methodology to Improve Performance of Graph Neural Networks
Jul 16, 2024



Graph neural networks (GNNs) are widely applied in graph data modeling. However, existing GNNs are often trained in a task-driven manner that fails to fully capture the intrinsic nature of the graph structure, resulting in sub-optimal node and graph representations. To address this limitation, we propose a novel Graph structure Prompt Learning method (GPL) to enhance the training of GNNs, which is inspired by prompt mechanisms in natural language processing. GPL employs task-independent graph structure losses to encourage GNNs to learn intrinsic graph characteristics while simultaneously solving downstream tasks, producing higher-quality node and graph representations. In extensive experiments on eleven real-world datasets, after being trained by GPL, GNNs significantly outperform their original performance on node classification, graph classification, and edge prediction tasks (up to 10.28%, 16.5%, and 24.15%, respectively). By allowing GNNs to capture the inherent structural prompts of graphs in GPL, they can alleviate the issue of over-smooth and achieve new state-of-the-art performances, which introduces a novel and effective direction for GNN research with potential applications in various domains.
SES: Bridging the Gap Between Explainability and Prediction of Graph Neural Networks
Jul 16, 2024



Despite the Graph Neural Networks' (GNNs) proficiency in analyzing graph data, achieving high-accuracy and interpretable predictions remains challenging. Existing GNN interpreters typically provide post-hoc explanations disjointed from GNNs' predictions, resulting in misrepresentations. Self-explainable GNNs offer built-in explanations during the training process. However, they cannot exploit the explanatory outcomes to augment prediction performance, and they fail to provide high-quality explanations of node features and require additional processes to generate explainable subgraphs, which is costly. To address the aforementioned limitations, we propose a self-explained and self-supervised graph neural network (SES) to bridge the gap between explainability and prediction. SES comprises two processes: explainable training and enhanced predictive learning. During explainable training, SES employs a global mask generator co-trained with a graph encoder and directly produces crucial structure and feature masks, reducing time consumption and providing node feature and subgraph explanations. In the enhanced predictive learning phase, mask-based positive-negative pairs are constructed utilizing the explanations to compute a triplet loss and enhance the node representations by contrastive learning.
A bioinspired three-stage model for camouflaged object detection
May 22, 2023Camouflaged objects are typically assimilated into their backgrounds and exhibit fuzzy boundaries. The complex environmental conditions and the high intrinsic similarity between camouflaged targets and their surroundings pose significant challenges in accurately locating and segmenting these objects in their entirety. While existing methods have demonstrated remarkable performance in various real-world scenarios, they still face limitations when confronted with difficult cases, such as small targets, thin structures, and indistinct boundaries. Drawing inspiration from human visual perception when observing images containing camouflaged objects, we propose a three-stage model that enables coarse-to-fine segmentation in a single iteration. Specifically, our model employs three decoders to sequentially process subsampled features, cropped features, and high-resolution original features. This proposed approach not only reduces computational overhead but also mitigates interference caused by background noise. Furthermore, considering the significance of multi-scale information, we have designed a multi-scale feature enhancement module that enlarges the receptive field while preserving detailed structural cues. Additionally, a boundary enhancement module has been developed to enhance performance by leveraging boundary information. Subsequently, a mask-guided fusion module is proposed to generate fine-grained results by integrating coarse prediction maps with high-resolution feature maps. Our network surpasses state-of-the-art CNN-based counterparts without unnecessary complexities. Upon acceptance of the paper, the source code will be made publicly available at https://github.com/clelouch/BTSNet.
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
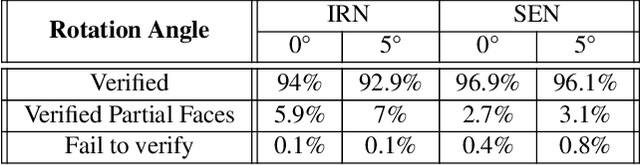
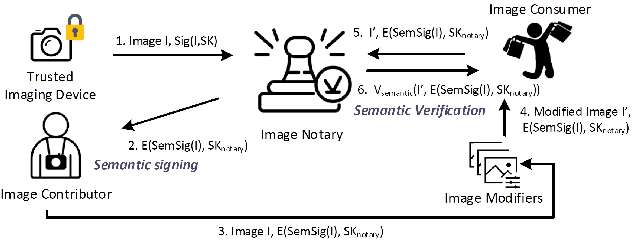
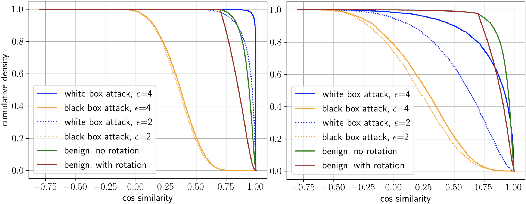
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.
Towards Robust Sensor Fusion in Visual Perception
Jun 23, 2020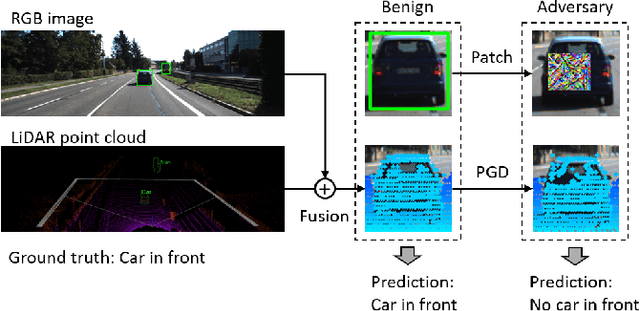
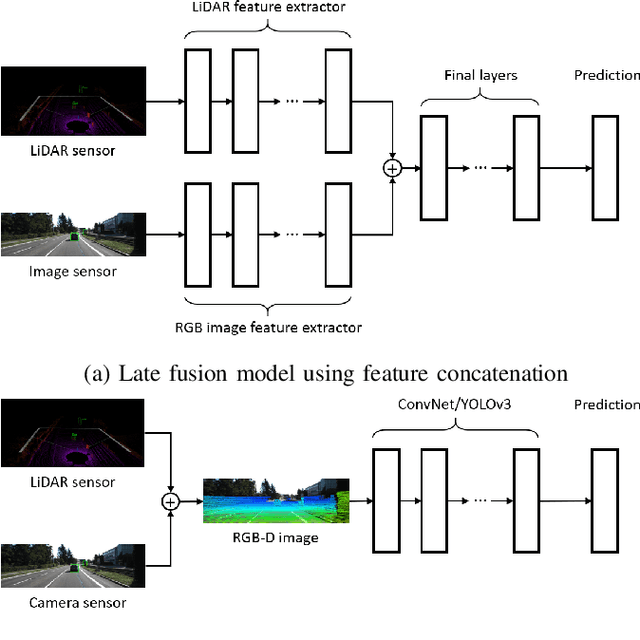
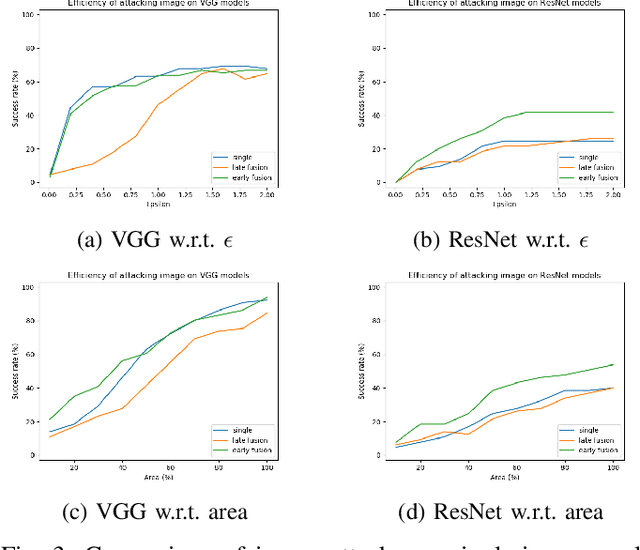
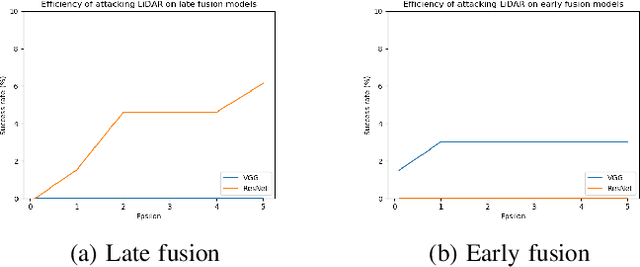
We study the problem of robust sensor fusion in visual perception, especially under the autonomous driving settings. We evaluate the robustness of RGB camera and LiDAR sensor fusion for binary classification and object detection. In this work, we are interested in the behavior of different fusion methods under adversarial attacks on different sensors. We first train both classification and detection models with early fusion and late fusion, then apply different combinations of adversarial attacks on both sensor inputs for evaluation. We also study the effectiveness of adversarial attacks with varying budgets. Experiment results show that while sensor fusion models are generally vulnerable to adversarial attacks, late fusion method is more robust than early fusion. The results also provide insights on further obtaining robust sensor fusion models.