 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
KAT-Coder-V2 Technical Report
Mar 29, 2026We present KAT-Coder-V2, an agentic coding model developed by the KwaiKAT team at Kuaishou. KAT-Coder-V2 adopts a "Specialize-then-Unify" paradigm that decomposes agentic coding into five expert domains - SWE, WebCoding, Terminal, WebSearch, and General - each undergoing independent supervised fine-tuning and reinforcement learning, before being consolidated into a single model via on-policy distillation. We develop KwaiEnv, a modular infrastructure sustaining tens of thousands of concurrent sandbox instances, and scale RL training along task complexity, intent alignment, and scaffold generalization. We further propose MCLA for stabilizing MoE RL training and Tree Training for eliminating redundant computation over tree-structured trajectories with up to 6.2x speedup. KAT-Coder-V2 achieves 79.6% on SWE-bench Verified (vs. Claude Opus 4.6 at 80.8%), 88.7 on PinchBench (surpassing GLM-5 and MiniMax M2.7), ranks first across all three frontend aesthetics scenarios, and maintains strong generalist scores on Terminal-Bench Hard (46.8) and tau^2-Bench (93.9). Our model is publicly available at https://streamlake.com/product/kat-coder.
WeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
BUT Systems for WildSpoof Challenge: SASV in the Wild
Dec 14, 2025
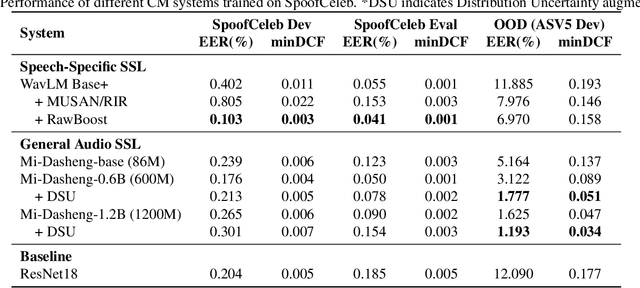

This paper presents the BUT submission to the WildSpoof Challenge, focusing on the Spoofing-robust Automatic Speaker Verification (SASV) track. We propose a SASV framework designed to bridge the gap between general audio understanding and specialized speech analysis. Our subsystem integrates diverse Self-Supervised Learning front-ends ranging from general audio models (e.g., Dasheng) to speech-specific encoders (e.g., WavLM). These representations are aggregated via a lightweight Multi-Head Factorized Attention back-end for corresponding subtasks. Furthermore, we introduce a feature domain augmentation strategy based on Distribution Uncertainty to explicitly model and mitigate the domain shift caused by unseen neural vocoders and recording environments. By fusing these robust CM scores with state-of-the-art ASV systems, our approach achieves superior minimization of the a-DCFs and EERs.
BUT Systems for Environmental Sound Deepfake Detection in the ESDD 2026 Challenge
Dec 09, 2025This paper describes the BUT submission to the ESDD 2026 Challenge, specifically focusing on Track 1: Environmental Sound Deepfake Detection with Unseen Generators. To address the critical challenge of generalizing to audio generated by unseen synthesis algorithms, we propose a robust ensemble framework leveraging diverse Self-Supervised Learning (SSL) models. We conduct a comprehensive analysis of general audio SSL models (including BEATs, EAT, and Dasheng) and speech-specific SSLs. These front-ends are coupled with a lightweight Multi-Head Factorized Attention (MHFA) back-end to capture discriminative representations. Furthermore, we introduce a feature domain augmentation strategy based on distribution uncertainty modeling to enhance model robustness against unseen spectral distortions. All models are trained exclusively on the official EnvSDD data, without using any external resources. Experimental results demonstrate the effectiveness of our approach: our best single system achieved Equal Error Rates (EER) of 0.00\%, 4.60\%, and 4.80\% on the Development, Progress (Track 1), and Final Evaluation sets, respectively. The fusion system further improved generalization, yielding EERs of 0.00\%, 3.52\%, and 4.38\% across the same partitions.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
TS-SUPERB: A Target Speech Processing Benchmark for Speech Self-Supervised Learning Models
May 10, 2025



Self-supervised learning (SSL) models have significantly advanced speech processing tasks, and several benchmarks have been proposed to validate their effectiveness. However, previous benchmarks have primarily focused on single-speaker scenarios, with less exploration of target-speaker tasks in noisy, multi-talker conditions -- a more challenging yet practical case. In this paper, we introduce the Target-Speaker Speech Processing Universal Performance Benchmark (TS-SUPERB), which includes four widely recognized target-speaker processing tasks that require identifying the target speaker and extracting information from the speech mixture. In our benchmark, the speaker embedding extracted from enrollment speech is used as a clue to condition downstream models. The benchmark result reveals the importance of evaluating SSL models in target speaker scenarios, demonstrating that performance cannot be easily inferred from related single-speaker tasks. Moreover, by using a unified SSL-based target speech encoder, consisting of a speaker encoder and an extractor module, we also investigate joint optimization across TS tasks to leverage mutual information and demonstrate its effectiveness.
SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Apr 22, 2025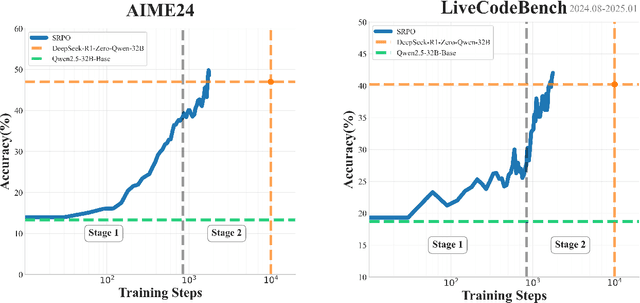



Recent advances of reasoning models, exemplified by OpenAI's o1 and DeepSeek's R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B), using only about 1/10 of the training steps required by DeepSeek-R1-Zero-32B, demonstrating superior efficiency. Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, offering valuable insights into scaling LLM reasoning capabilities across diverse tasks.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.