 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontend Token Enhancement for Token-Based Speech Recognition
Feb 04, 2026Discretized representations of speech signals are efficient alternatives to continuous features for various speech applications, including automatic speech recognition (ASR) and speech language models. However, these representations, such as semantic or phonetic tokens derived from clustering outputs of self-supervised learning (SSL) speech models, are susceptible to environmental noise, which can degrade backend task performance. In this work, we introduce a frontend system that estimates clean speech tokens from noisy speech and evaluate it on an ASR backend using semantic tokens. We consider four types of enhancement models based on their input/output domains: wave-to-wave, token-to-token, continuous SSL features-to-token, and wave-to-token. These models are trained independently of ASR backends. Experiments on the CHiME-4 dataset demonstrate that wave-to-token enhancement achieves the best performance among the frontends. Moreover, it mostly outperforms the ASR system based on continuous SSL features.
Investigation of Speaker Representation for Target-Speaker Speech Processing
Oct 15, 2024
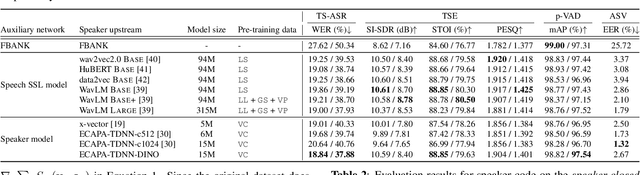


Target-speaker speech processing (TS) tasks, such as target-speaker automatic speech recognition (TS-ASR), target speech extraction (TSE), and personal voice activity detection (p-VAD), are important for extracting information about a desired speaker's speech even when it is corrupted by interfering speakers. While most studies have focused on training schemes or system architectures for each specific task, the auxiliary network for embedding target-speaker cues has not been investigated comprehensively in a unified cross-task evaluation. Therefore, this paper aims to address a fundamental question: what is the preferred speaker embedding for TS tasks? To this end, for the TS-ASR, TSE, and p-VAD tasks, we compare pre-trained speaker encoders (i.e., self-supervised or speaker recognition models) that compute speaker embeddings from pre-recorded enrollment speech of the target speaker with ideal speaker embeddings derived directly from the target speaker's identity in the form of a one-hot vector. To further understand the properties of ideal speaker embedding, we optimize it using a gradient-based approach to improve performance on the TS task. Our analysis reveals that speaker verification performance is somewhat unrelated to TS task performances, the one-hot vector outperforms enrollment-based ones, and the optimal embedding depends on the input mixture.
Alignment-Free Training for Transducer-based Multi-Talker ASR
Sep 30, 2024

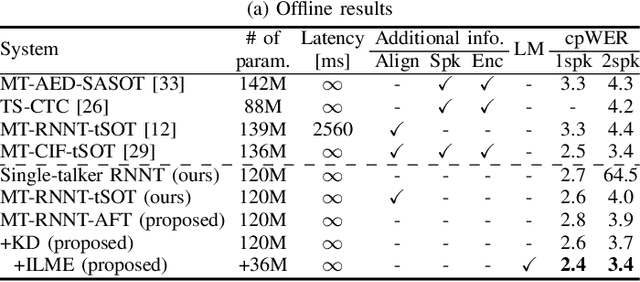
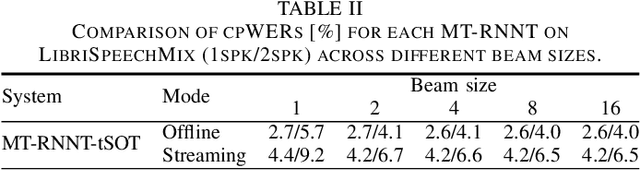
Extending the RNN Transducer (RNNT) to recognize multi-talker speech is essential for wider automatic speech recognition (ASR) applications. Multi-talker RNNT (MT-RNNT) aims to achieve recognition without relying on costly front-end source separation. MT-RNNT is conventionally implemented using architectures with multiple encoders or decoders, or by serializing all speakers' transcriptions into a single output stream. The first approach is computationally expensive, particularly due to the need for multiple encoder processing. In contrast, the second approach involves a complex label generation process, requiring accurate timestamps of all words spoken by all speakers in the mixture, obtained from an external ASR system. In this paper, we propose a novel alignment-free training scheme for the MT-RNNT (MT-RNNT-AFT) that adopts the standard RNNT architecture. The target labels are created by appending a prompt token corresponding to each speaker at the beginning of the transcription, reflecting the order of each speaker's appearance in the mixtures. Thus, MT-RNNT-AFT can be trained without relying on accurate alignments, and it can recognize all speakers' speech with just one round of encoder processing. Experiments show that MT-RNNT-AFT achieves performance comparable to that of the state-of-the-art alternatives, while greatly simplifying the training process.
Boosting Hybrid Autoregressive Transducer-based ASR with Internal Acoustic Model Training and Dual Blank Thresholding
Sep 30, 2024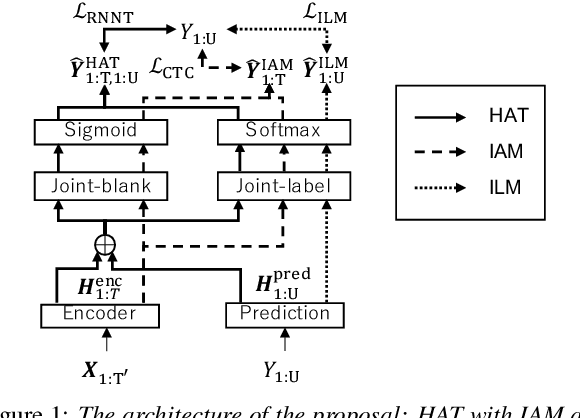
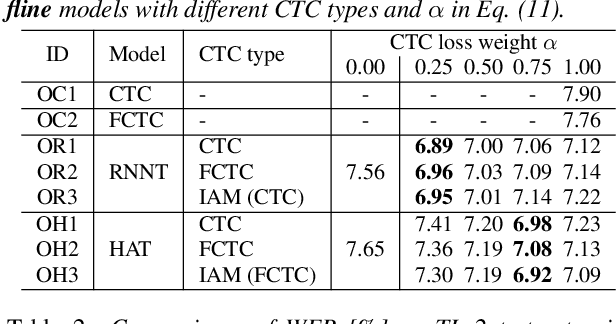
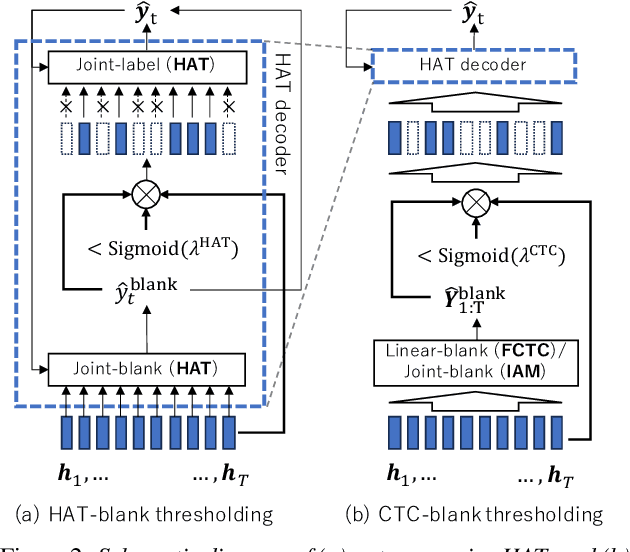
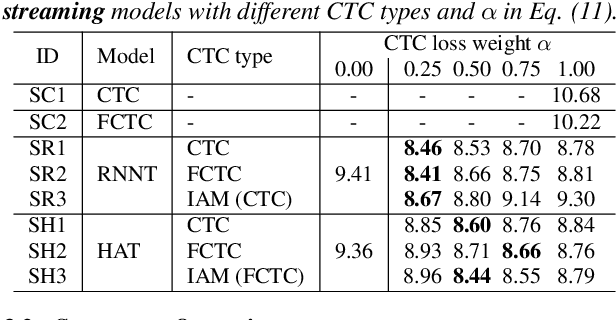
A hybrid autoregressive transducer (HAT) is a variant of neural transducer that models blank and non-blank posterior distributions separately. In this paper, we propose a novel internal acoustic model (IAM) training strategy to enhance HAT-based speech recognition. IAM consists of encoder and joint networks, which are fully shared and jointly trained with HAT. This joint training not only enhances the HAT training efficiency but also encourages IAM and HAT to emit blanks synchronously which skips the more expensive non-blank computation, resulting in more effective blank thresholding for faster decoding. Experiments demonstrate that the relative error reductions of the HAT with IAM compared to the vanilla HAT are statistically significant. Moreover, we introduce dual blank thresholding, which combines both HAT- and IAM-blank thresholding and a compatible decoding algorithm. This results in a 42-75% decoding speed-up with no major performance degradation.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024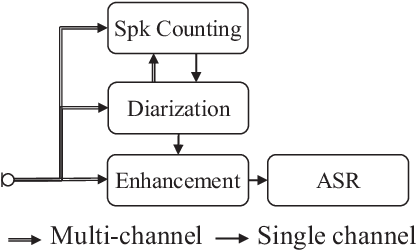
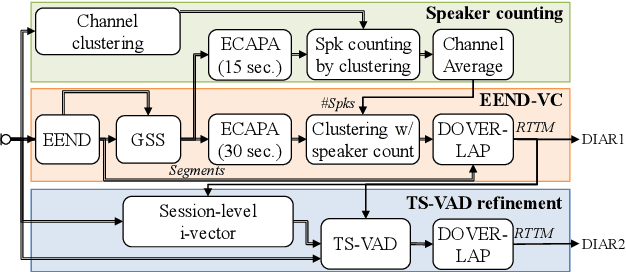

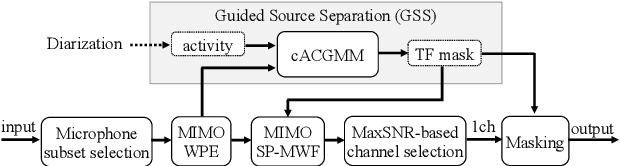
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Aug 01, 2024



This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.
Applying LLMs for Rescoring N-best ASR Hypotheses of Casual Conversations: Effects of Domain Adaptation and Context Carry-over
Jun 27, 2024Large language models (LLMs) have been successfully applied for rescoring automatic speech recognition (ASR) hypotheses. However, their ability to rescore ASR hypotheses of casual conversations has not been sufficiently explored. In this study, we reveal it by performing N-best ASR hypotheses rescoring using Llama2 on the CHiME-7 distant ASR (DASR) task. Llama2 is one of the most representative LLMs, and the CHiME-7 DASR task provides datasets of casual conversations between multiple participants. We investigate the effects of domain adaptation of the LLM and context carry-over when performing N-best rescoring. Experimental results show that, even without domain adaptation, Llama2 outperforms a standard-size domain-adapted Transformer-LM, especially when using a long context. Domain adaptation shortens the context length needed with Llama2 to achieve its best performance, i.e., it reduces the computational cost of Llama2.
What Do Self-Supervised Speech and Speaker Models Learn? New Findings From a Cross Model Layer-Wise Analysis
Jan 31, 2024



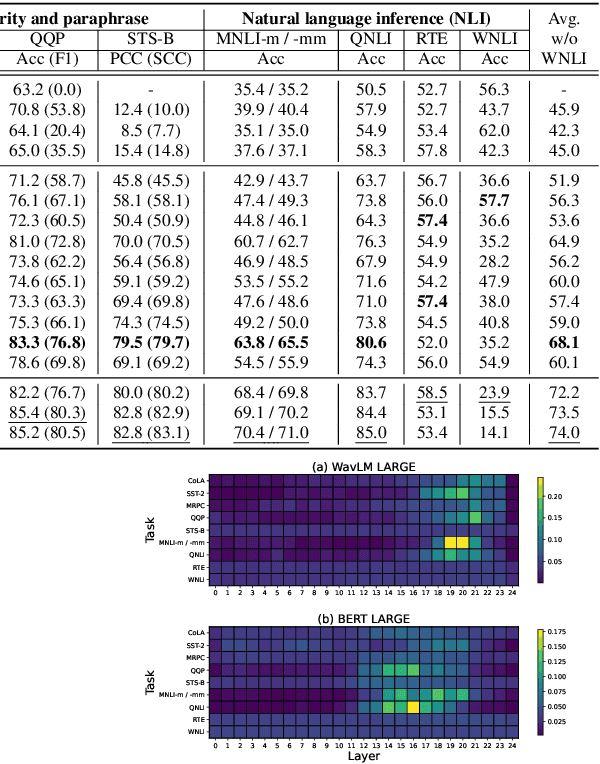
Self-supervised learning (SSL) has attracted increased attention for learning meaningful speech representations. Speech SSL models, such as WavLM, employ masked prediction training to encode general-purpose representations. In contrast, speaker SSL models, exemplified by DINO-based models, adopt utterance-level training objectives primarily for speaker representation. Understanding how these models represent information is essential for refining model efficiency and effectiveness. Unlike the various analyses of speech SSL, there has been limited investigation into what information speaker SSL captures and how its representation differs from speech SSL or other fully-supervised speaker models. This paper addresses these fundamental questions. We explore the capacity to capture various speech properties by applying SUPERB evaluation probing tasks to speech and speaker SSL models. We also examine which layers are predominantly utilized for each task to identify differences in how speech is represented. Furthermore, we conduct direct comparisons to measure the similarities between layers within and across models. Our analysis unveils that 1) the capacity to represent content information is somewhat unrelated to enhanced speaker representation, 2) specific layers of speech SSL models would be partly specialized in capturing linguistic information, and 3) speaker SSL models tend to disregard linguistic information but exhibit more sophisticated speaker representation.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023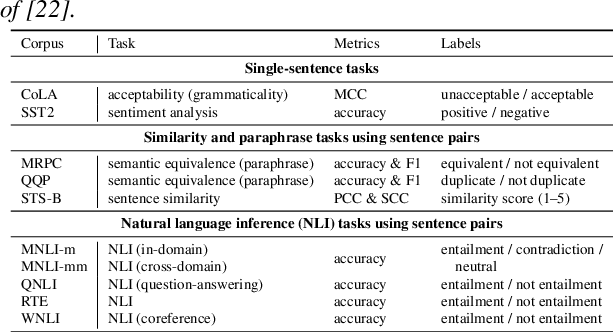
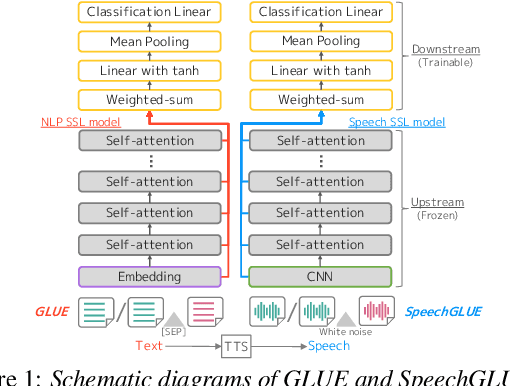
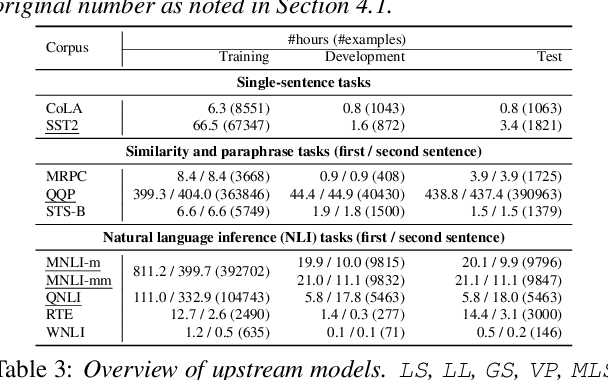
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.
Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization
Jun 07, 2023End-to-end speech summarization (E2E SSum) directly summarizes input speech into easy-to-read short sentences with a single model. This approach is promising because it, in contrast to the conventional cascade approach, can utilize full acoustical information and mitigate to the propagation of transcription errors. However, due to the high cost of collecting speech-summary pairs, an E2E SSum model tends to suffer from training data scarcity and output unnatural sentences. To overcome this drawback, we propose for the first time to integrate a pre-trained language model (LM), which is highly capable of generating natural sentences, into the E2E SSum decoder via transfer learning. In addition, to reduce the gap between the independently pre-trained encoder and decoder, we also propose to transfer the baseline E2E SSum encoder instead of the commonly used automatic speech recognition encoder. Experimental results show that the proposed model outperforms baseline and data augmented models.