 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation for Relative Voice Impression Estimation
Feb 15, 2026Paralinguistic and non-linguistic aspects of speech strongly influence listener impressions. While most research focuses on absolute impression scoring, this study investigates relative voice impression estimation (RIE), a framework for predicting the perceptual difference between two utterances from the same speaker. The estimation target is a low-dimensional vector derived from subjective evaluations, quantifying the perceptual shift of the second utterance relative to the first along an antonymic axis (e.g., ``Dark--Bright''). To isolate expressive and prosodic variation, we used recordings of a professional speaker reading a text in various styles. We compare three modeling approaches: classical acoustic features commonly used for speech emotion recognition, self-supervised speech representations, and multimodal large language models (MLLMs). Our results demonstrate that models using self-supervised representations outperform methods with classical acoustic features, particularly in capturing complex and dynamic impressions (e.g., ``Cold--Warm'') where classical features fail. In contrast, current MLLMs prove unreliable for this fine-grained pairwise task. This study provides the first systematic investigation of RIE and demonstrates the strength of self-supervised speech models in capturing subtle perceptual variations.
Voice Impression Control in Zero-Shot TTS
Jun 06, 2025Para-/non-linguistic information in speech is pivotal in shaping the listeners' impression. Although zero-shot text-to-speech (TTS) has achieved high speaker fidelity, modulating subtle para-/non-linguistic information to control perceived voice characteristics, i.e., impressions, remains challenging. We have therefore developed a voice impression control method in zero-shot TTS that utilizes a low-dimensional vector to represent the intensities of various voice impression pairs (e.g., dark-bright). The results of both objective and subjective evaluations have demonstrated our method's effectiveness in impression control. Furthermore, generating this vector via a large language model enables target-impression generation from a natural language description of the desired impression, thus eliminating the need for manual optimization.
Lightweight Zero-shot Text-to-Speech with Mixture of Adapters
Jul 01, 2024



The advancements in zero-shot text-to-speech (TTS) methods, based on large-scale models, have demonstrated high fidelity in reproducing speaker characteristics. However, these models are too large for practical daily use. We propose a lightweight zero-shot TTS method using a mixture of adapters (MoA). Our proposed method incorporates MoA modules into the decoder and the variance adapter of a non-autoregressive TTS model. These modules enhance the ability to adapt a wide variety of speakers in a zero-shot manner by selecting appropriate adapters associated with speaker characteristics on the basis of speaker embeddings. Our method achieves high-quality speech synthesis with minimal additional parameters. Through objective and subjective evaluations, we confirmed that our method achieves better performance than the baseline with less than 40\% of parameters at 1.9 times faster inference speed. Audio samples are available on our demo page (https://ntt-hilab-gensp.github.io/is2024lightweightTTS/).
Speech Rhythm-Based Speaker Embeddings Extraction from Phonemes and Phoneme Duration for Multi-Speaker Speech Synthesis
Feb 11, 2024



This paper proposes a speech rhythm-based method for speaker embeddings to model phoneme duration using a few utterances by the target speaker. Speech rhythm is one of the essential factors among speaker characteristics, along with acoustic features such as F0, for reproducing individual utterances in speech synthesis. A novel feature of the proposed method is the rhythm-based embeddings extracted from phonemes and their durations, which are known to be related to speaking rhythm. They are extracted with a speaker identification model similar to the conventional spectral feature-based one. We conducted three experiments, speaker embeddings generation, speech synthesis with generated embeddings, and embedding space analysis, to evaluate the performance. The proposed method demonstrated a moderate speaker identification performance (15.2% EER), even with only phonemes and their duration information. The objective and subjective evaluation results demonstrated that the proposed method can synthesize speech with speech rhythm closer to the target speaker than the conventional method. We also visualized the embeddings to evaluate the relationship between the distance of the embeddings and the perceptual similarity. The visualization of the embedding space and the relation analysis between the closeness indicated that the distribution of embeddings reflects the subjective and objective similarity.
* 11 pages,9 figures, Accepted to IEICE TRANSACTIONS on Information and Systems
What Do Self-Supervised Speech and Speaker Models Learn? New Findings From a Cross Model Layer-Wise Analysis
Jan 31, 2024



Self-supervised learning (SSL) has attracted increased attention for learning meaningful speech representations. Speech SSL models, such as WavLM, employ masked prediction training to encode general-purpose representations. In contrast, speaker SSL models, exemplified by DINO-based models, adopt utterance-level training objectives primarily for speaker representation. Understanding how these models represent information is essential for refining model efficiency and effectiveness. Unlike the various analyses of speech SSL, there has been limited investigation into what information speaker SSL captures and how its representation differs from speech SSL or other fully-supervised speaker models. This paper addresses these fundamental questions. We explore the capacity to capture various speech properties by applying SUPERB evaluation probing tasks to speech and speaker SSL models. We also examine which layers are predominantly utilized for each task to identify differences in how speech is represented. Furthermore, we conduct direct comparisons to measure the similarities between layers within and across models. Our analysis unveils that 1) the capacity to represent content information is somewhat unrelated to enhanced speaker representation, 2) specific layers of speech SSL models would be partly specialized in capturing linguistic information, and 3) speaker SSL models tend to disregard linguistic information but exhibit more sophisticated speaker representation.
Noise-robust zero-shot text-to-speech synthesis conditioned on self-supervised speech-representation model with adapters
Jan 10, 2024



The zero-shot text-to-speech (TTS) method, based on speaker embeddings extracted from reference speech using self-supervised learning (SSL) speech representations, can reproduce speaker characteristics very accurately. However, this approach suffers from degradation in speech synthesis quality when the reference speech contains noise. In this paper, we propose a noise-robust zero-shot TTS method. We incorporated adapters into the SSL model, which we fine-tuned with the TTS model using noisy reference speech. In addition, to further improve performance, we adopted a speech enhancement (SE) front-end. With these improvements, our proposed SSL-based zero-shot TTS achieved high-quality speech synthesis with noisy reference speech. Through the objective and subjective evaluations, we confirmed that the proposed method is highly robust to noise in reference speech, and effectively works in combination with SE.
StyleCap: Automatic Speaking-Style Captioning from Speech Based on Speech and Language Self-supervised Learning Models
Nov 28, 2023We propose StyleCap, a method to generate natural language descriptions of speaking styles appearing in speech. Although most of conventional techniques for para-/non-linguistic information recognition focus on the category classification or the intensity estimation of pre-defined labels, they cannot provide the reasoning of the recognition result in an interpretable manner. As a first step towards an end-to-end method for generating speaking-style prompts from speech, i.e., automatic speaking-style captioning, StyleCap uses paired data of speech and natural language descriptions to train neural networks that predict prefix vectors fed into a large language model (LLM)-based text decoder from a speech representation vector. We explore an appropriate text decoder and speech feature representation suitable for this new task. The experimental results demonstrate that our StyleCap leveraging richer LLMs for the text decoder, speech self-supervised learning (SSL) features, and sentence rephrasing augmentation improves the accuracy and diversity of generated speaking-style captions. Samples of speaking-style captions generated by our StyleCap are publicly available.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023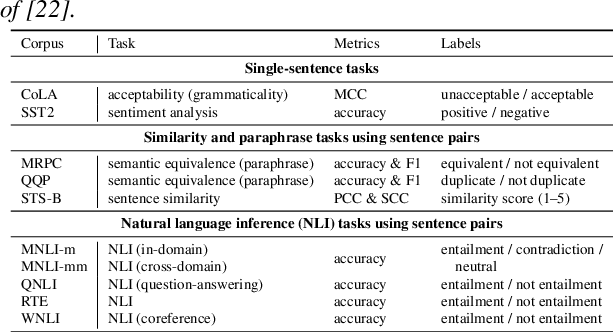
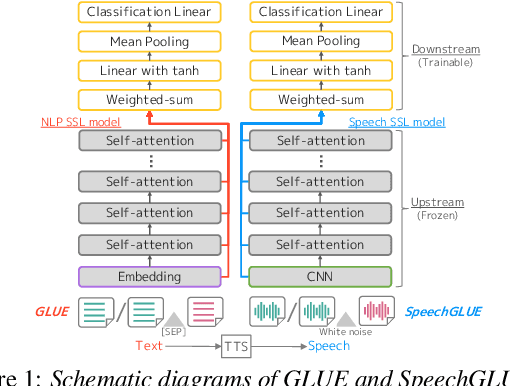
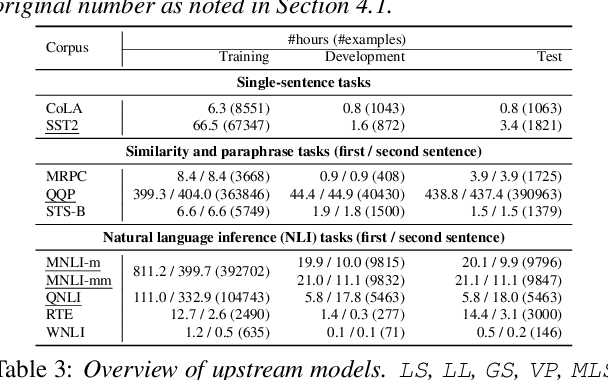
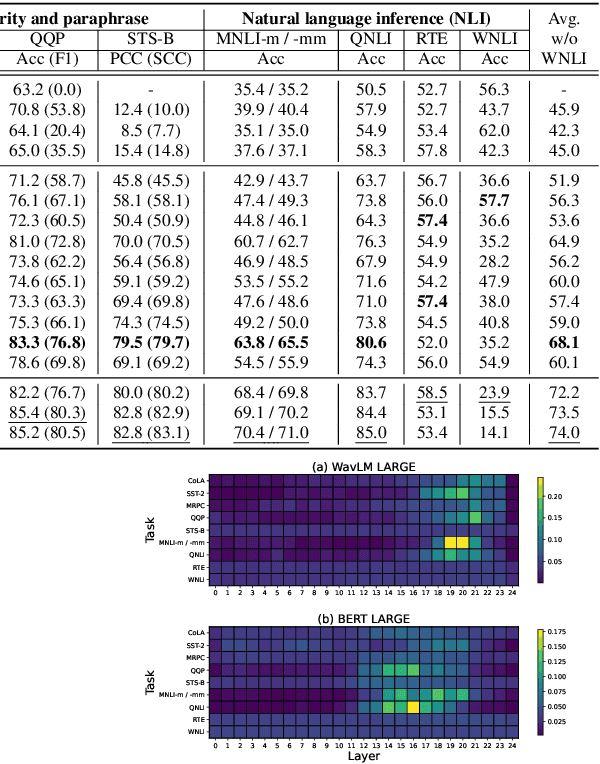
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.
Zero-shot text-to-speech synthesis conditioned using self-supervised speech representation model
Apr 24, 2023This paper proposes a zero-shot text-to-speech (TTS) conditioned by a self-supervised speech-representation model acquired through self-supervised learning (SSL). Conventional methods with embedding vectors from x-vector or global style tokens still have a gap in reproducing the speaker characteristics of unseen speakers. A novel point of the proposed method is the direct use of the SSL model to obtain embedding vectors from speech representations trained with a large amount of data. We also introduce the separate conditioning of acoustic features and a phoneme duration predictor to obtain the disentangled embeddings between rhythm-based speaker characteristics and acoustic-feature-based ones. The disentangled embeddings will enable us to achieve better reproduction performance for unseen speakers and rhythm transfer conditioned by different speeches. Objective and subjective evaluations showed that the proposed method can synthesize speech with improved similarity and achieve speech-rhythm transfer.
SIMD-size aware weight regularization for fast neural vocoding on CPU
Nov 02, 2022This paper proposes weight regularization for a faster neural vocoder. Pruning time-consuming DNN modules is a promising way to realize a real-time vocoder on a CPU (e.g. WaveRNN, LPCNet). Regularization that encourages sparsity is also effective in avoiding the quality degradation created by pruning. However, the orders of weight matrices must be contiguous in SIMD size for fast vocoding. To ensure this order, we propose explicit SIMD size aware regularization. Our proposed method reshapes a weight matrix into a tensor so that the weights are aligned by group size in advance, and then computes the group Lasso-like regularization loss. Experiments on 70% sparse subband WaveRNN show that pruning in conventional Lasso and column-wise group Lasso degrades the synthetic speech's naturalness. The vocoder with proposed regularization 1) achieves comparable naturalness to that without pruning and 2) performs meaningfully faster than other conventional vocoders using regularization.