 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Hybrid Autoregressive Transducer-based ASR with Internal Acoustic Model Training and Dual Blank Thresholding
Sep 30, 2024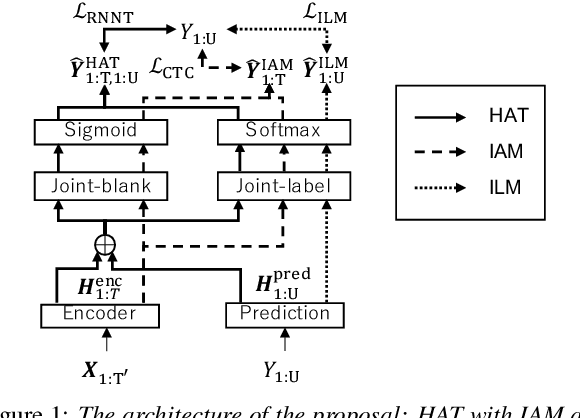
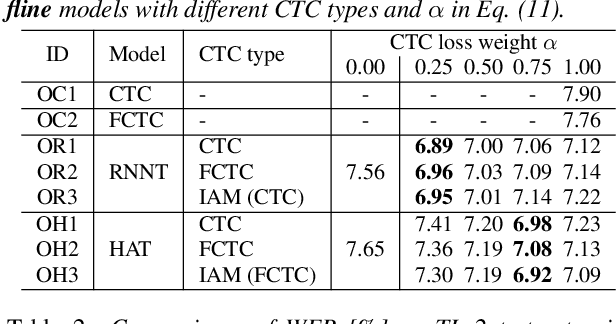
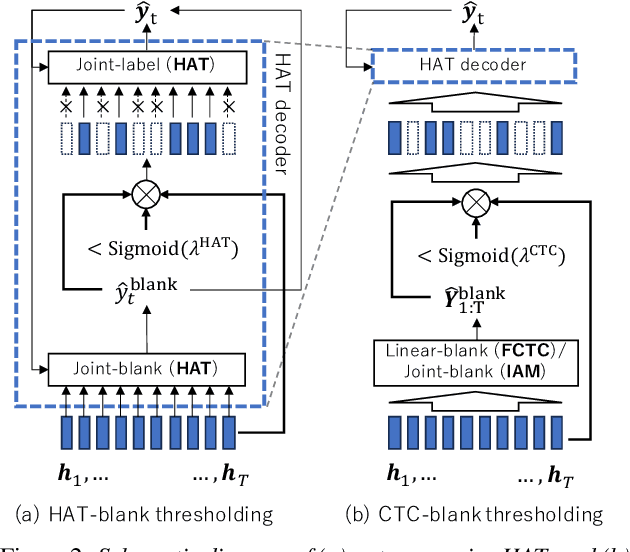
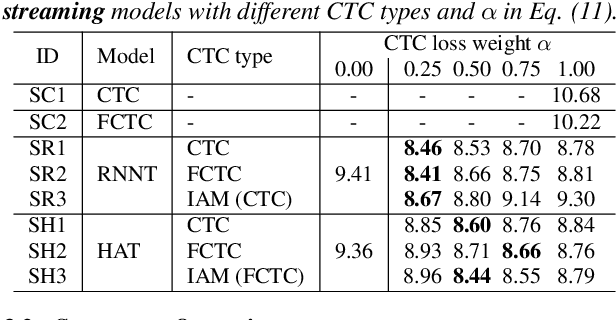
A hybrid autoregressive transducer (HAT) is a variant of neural transducer that models blank and non-blank posterior distributions separately. In this paper, we propose a novel internal acoustic model (IAM) training strategy to enhance HAT-based speech recognition. IAM consists of encoder and joint networks, which are fully shared and jointly trained with HAT. This joint training not only enhances the HAT training efficiency but also encourages IAM and HAT to emit blanks synchronously which skips the more expensive non-blank computation, resulting in more effective blank thresholding for faster decoding. Experiments demonstrate that the relative error reductions of the HAT with IAM compared to the vanilla HAT are statistically significant. Moreover, we introduce dual blank thresholding, which combines both HAT- and IAM-blank thresholding and a compatible decoding algorithm. This results in a 42-75% decoding speed-up with no major performance degradation.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024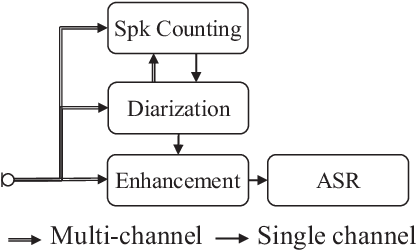
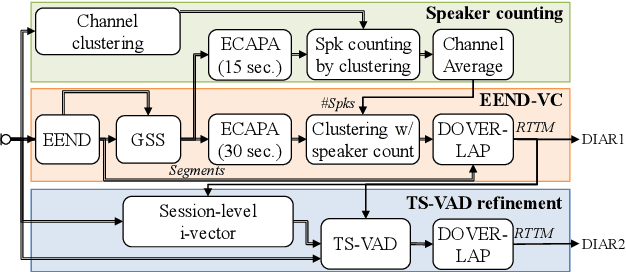

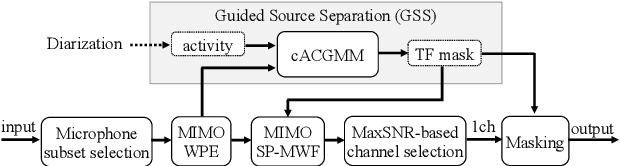
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
What Do Self-Supervised Speech and Speaker Models Learn? New Findings From a Cross Model Layer-Wise Analysis
Jan 31, 2024



Self-supervised learning (SSL) has attracted increased attention for learning meaningful speech representations. Speech SSL models, such as WavLM, employ masked prediction training to encode general-purpose representations. In contrast, speaker SSL models, exemplified by DINO-based models, adopt utterance-level training objectives primarily for speaker representation. Understanding how these models represent information is essential for refining model efficiency and effectiveness. Unlike the various analyses of speech SSL, there has been limited investigation into what information speaker SSL captures and how its representation differs from speech SSL or other fully-supervised speaker models. This paper addresses these fundamental questions. We explore the capacity to capture various speech properties by applying SUPERB evaluation probing tasks to speech and speaker SSL models. We also examine which layers are predominantly utilized for each task to identify differences in how speech is represented. Furthermore, we conduct direct comparisons to measure the similarities between layers within and across models. Our analysis unveils that 1) the capacity to represent content information is somewhat unrelated to enhanced speaker representation, 2) specific layers of speech SSL models would be partly specialized in capturing linguistic information, and 3) speaker SSL models tend to disregard linguistic information but exhibit more sophisticated speaker representation.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023
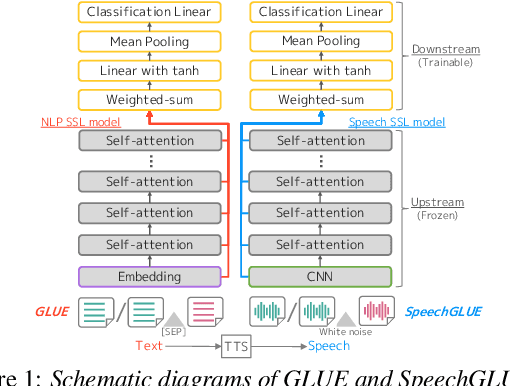
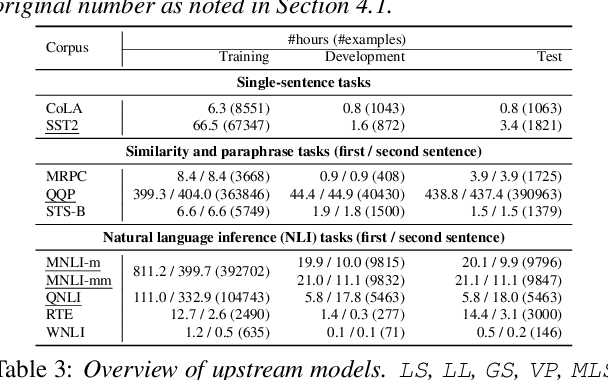
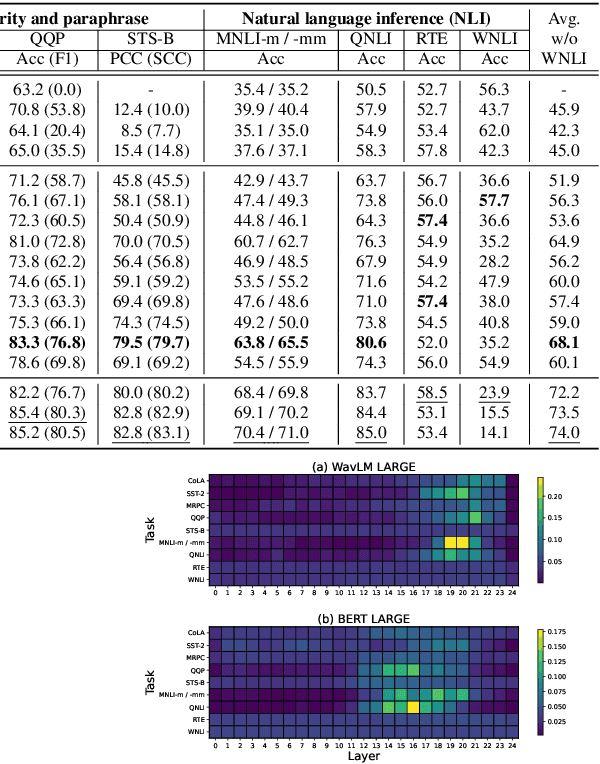
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.
Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data
May 25, 2023Neural transducer (RNNT)-based target-speaker speech recognition (TS-RNNT) directly transcribes a target speaker's voice from a multi-talker mixture. It is a promising approach for streaming applications because it does not incur the extra computation costs of a target speech extraction frontend, which is a critical barrier to quick response. TS-RNNT is trained end-to-end given the input speech (i.e., mixtures and enrollment speech) and reference transcriptions. The training mixtures are generally simulated by mixing single-talker signals, but conventional TS-RNNT training does not utilize single-speaker signals. This paper proposes using knowledge distillation (KD) to exploit the parallel mixture/single-talker speech data. Our proposed KD scheme uses an RNNT system pretrained with the target single-talker speech input to generate pseudo labels for the TS-RNNT training. Experimental results show that TS-RNNT systems trained with the proposed KD scheme outperform a baseline TS-RNNT.