 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models Abilities for Addressee, Turn-change, and Next Speaker Prediction in Meetings
Jun 16, 2026We investigate turn-taking in multimodal multi-party conversations using large language models (LLMs). We construct an evaluation framework for three tasks: addressee detection, turn-change prediction, and next speaker prediction. We compare supervised models trained for these tasks, text-based LLMs, multimodal LLMs (MM-LLMs), and human subjects. Experiments on the AMI corpus showed that LLMs outperformed supervised models and humans in next speaker prediction, despite not being trained on the target domain and without access to audio or visual information. An MM-LLM performed better than text-based LLMs on addressee detection and turn-change prediction but remained below human performance, indicating difficulty leveraging raw audio-visual signals. Ablation analyses revealed that conversational context was critical, particularly for next speaker prediction. We observed that human and LLM prediction patterns were similar, and intervals with frequent turn changes were difficult for both.
Tight Boundary Prediction in Speaker Diarization Using Causal-Anticausal Consistency
Jun 10, 2026Multi-talker conversational automatic speech recognition data are often used to train speaker diarization models. Because such data prioritize semantic continuity, pauses and boundary margins are included within speech segments, resulting in loose annotations. Models trained on such data tend to internalize mechanisms that reproduce this looseness, although tight speech intervals are sometimes preferable for downstream applications. In this paper, we address the novel task of enabling models to produce tight predictions using loose labels. Our method generates tighter pseudo labels using causal and anticausal models, which are inherently incapable of learning loosening behavior. We further propose a co-training scheme that iteratively tightens labels and updates both models for more progressive refinement. Experimental results show that the proposed method recovers about 70 % of the tightening effect achieved by ideal tight-label training and improves downstream performance.
Mitigating Non-Target Speaker Bias in Guided Speaker Embedding
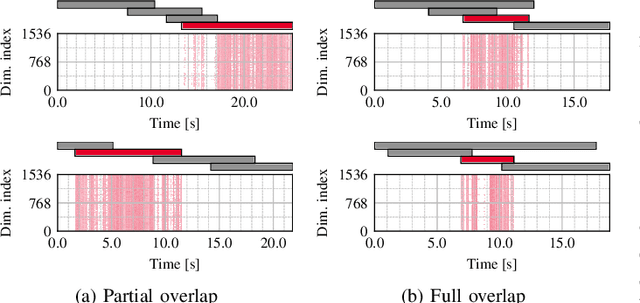
Jun 14, 2025Obtaining high-quality speaker embeddings in multi-speaker conditions is crucial for many applications. A recently proposed guided speaker embedding framework, which utilizes speech activities of target and non-target speakers as clues, drastically improved embeddings under severe overlap with small degradation in low-overlap cases. However, since extreme overlaps are rare in natural conversations, this degradation cannot be overlooked. This paper first reveals that the degradation is caused by the global-statistics-based modules, widely used in speaker embedding extractors, being overly sensitive to intervals containing only non-target speakers. As a countermeasure, we propose an extension of such modules that exploit the target speaker activity clues, to compute statistics from intervals where the target is active. The proposed method improves speaker verification performance in both low and high overlap ratios, and diarization performance on multiple datasets.
Dissecting the Segmentation Model of End-to-End Diarization with Vector Clustering
Jun 13, 2025



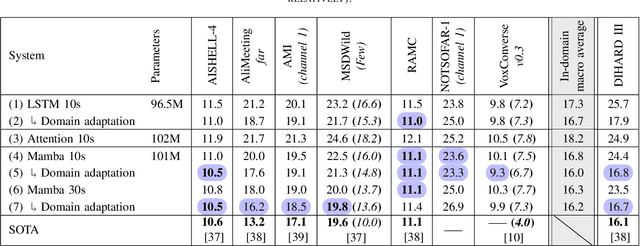
End-to-End Neural Diarization with Vector Clustering is a powerful and practical approach to perform Speaker Diarization. Multiple enhancements have been proposed for the segmentation model of these pipelines, but their synergy had not been thoroughly evaluated. In this work, we provide an in-depth analysis on the impact of major architecture choices on the performance of the pipeline. We investigate different encoders (SincNet, pretrained and finetuned WavLM), different decoders (LSTM, Mamba, and Conformer), different losses (multilabel and multiclass powerset), and different chunk sizes. Through in-depth experiments covering nine datasets, we found that the finetuned WavLM-based encoder always results in the best systems by a wide margin. The LSTM decoder is outclassed by Mamba- and Conformer-based decoders, and while we found Mamba more robust to other architecture choices, it is slightly inferior to our best architecture, which uses a Conformer encoder. We found that multilabel and multiclass powerset losses do not have the same distribution of errors. We confirmed that the multiclass loss helps almost all models attain superior performance, except when finetuning WavLM, in which case, multilabel is the superior choice. We also evaluated the impact of the chunk size on all aforementioned architecture choices and found that newer architectures tend to better handle long chunk sizes, which can greatly improve pipeline performance. Our best system achieved state-of-the-art results on five widely used speaker diarization datasets.
Pretraining Multi-Speaker Identification for Neural Speaker Diarization
May 30, 2025End-to-end speaker diarization enables accurate overlap-aware diarization by jointly estimating multiple speakers' speech activities in parallel. This approach is data-hungry, requiring a large amount of labeled conversational data, which cannot be fully obtained from real datasets alone. To address this issue, large-scale simulated data is often used for pretraining, but it requires enormous storage and I/O capacity, and simulating data that closely resembles real conversations remains challenging. In this paper, we propose pretraining a model to identify multiple speakers from an input fully overlapped mixture as an alternative to pretraining a diarization model. This method eliminates the need to prepare a large-scale simulated dataset while leveraging large-scale speaker recognition datasets for training. Through comprehensive experiments, we demonstrate that the proposed method enables a highly accurate yet lightweight local diarization model without simulated conversational data.
Guided Speaker Embedding
Oct 16, 2024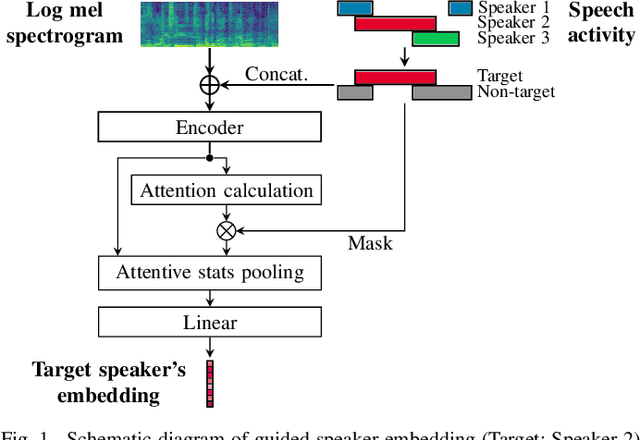


This paper proposes a guided speaker embedding extraction system, which extracts speaker embeddings of the target speaker using speech activities of target and interference speakers as clues. Several methods for long-form overlapped multi-speaker audio processing are typically two-staged: i) segment-level processing and ii) inter-segment speaker matching. Speaker embeddings are often used for the latter purpose. Typical speaker embedding extraction approaches only use single-speaker intervals to avoid corrupting the embeddings with speech from interference speakers. However, this often makes speaker embeddings impossible to extract because sufficiently long non-overlapping intervals are not always available. In this paper, we propose using speaker activities as clues to extract the embedding of the speaker-of-interest directly from overlapping speech. Specifically, we concatenate the activity of target and non-target speakers to acoustic features before being fed to the model. We also condition the attention weights used for pooling so that the attention weights of the intervals in which the target speaker is inactive are zero. The effectiveness of the proposed method is demonstrated in speaker verification and speaker diarization.
Mamba-based Segmentation Model for Speaker Diarization
Oct 10, 2024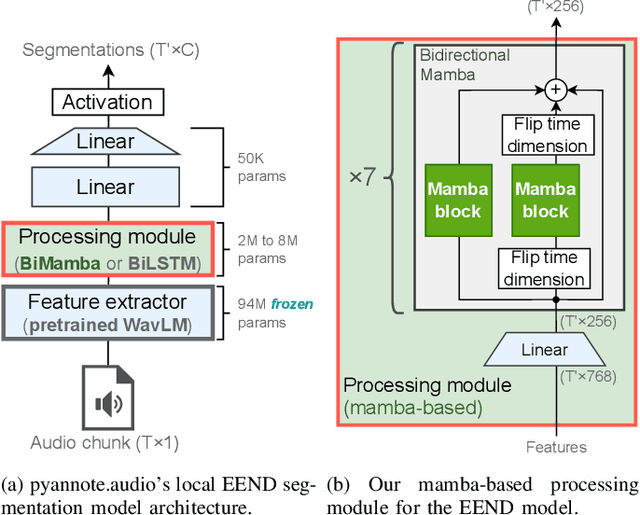
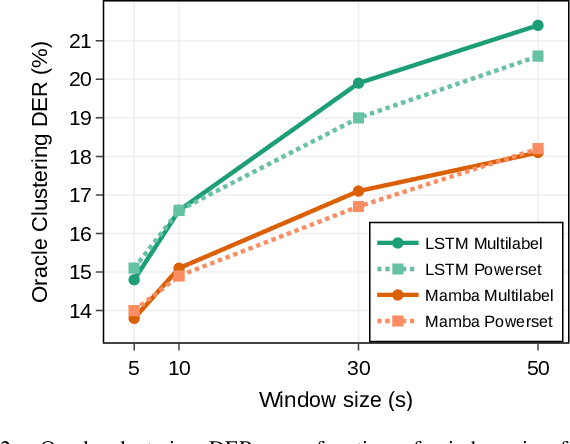
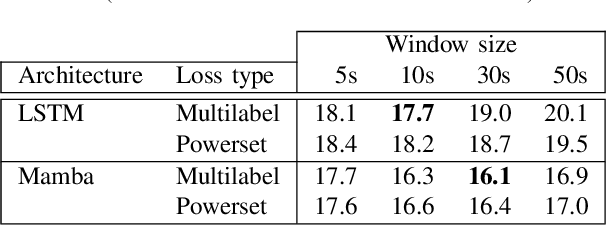
Mamba is a newly proposed architecture which behaves like a recurrent neural network (RNN) with attention-like capabilities. These properties are promising for speaker diarization, as attention-based models have unsuitable memory requirements for long-form audio, and traditional RNN capabilities are too limited. In this paper, we propose to assess the potential of Mamba for diarization by comparing the state-of-the-art neural segmentation of the pyannote pipeline with our proposed Mamba-based variant. Mamba's stronger processing capabilities allow usage of longer local windows, which significantly improve diarization quality by making the speaker embedding extraction more reliable. We find Mamba to be a superior alternative to both traditional RNN and the tested attention-based model. Our proposed Mamba-based system achieves state-of-the-art performance on three widely used diarization datasets.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024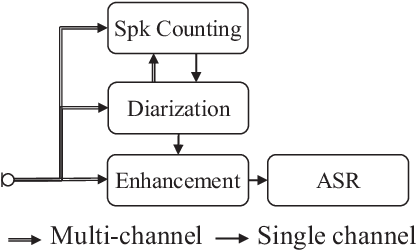
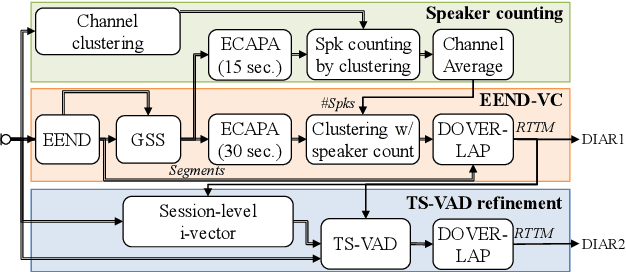

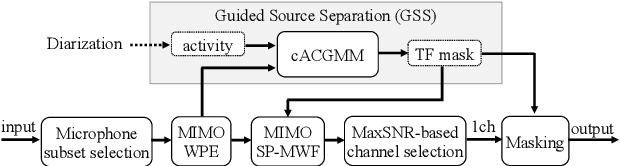
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Recursive Attentive Pooling for Extracting Speaker Embeddings from Multi-Speaker Recordings
Aug 30, 2024



This paper proposes a method for extracting speaker embedding for each speaker from a variable-length recording containing multiple speakers. Speaker embeddings are crucial not only for speaker recognition but also for various multi-speaker speech applications such as speaker diarization and target-speaker speech processing. Despite the challenges of obtaining a single speaker's speech without pre-registration in multi-speaker scenarios, most studies on speaker embedding extraction focus on extracting embeddings only from single-speaker recordings. Some methods have been proposed for extracting speaker embeddings directly from multi-speaker recordings, but they typically require preparing a model for each possible number of speakers or involve complicated training procedures. The proposed method computes the embeddings of multiple speakers by focusing on different parts of the frame-wise embeddings extracted from the input multi-speaker audio. This is achieved by recursively computing attention weights for pooling the frame-wise embeddings. Additionally, we propose using the calculated attention weights to estimate the number of speakers in the recording, which allows the same model to be applied to various numbers of speakers. Experimental evaluations demonstrate the effectiveness of the proposed method in speaker verification and diarization tasks.
SpeakerBeam-SS: Real-time Target Speaker Extraction with Lightweight Conv-TasNet and State Space Modeling
Jul 01, 2024


Real-time target speaker extraction (TSE) is intended to extract the desired speaker's voice from the observed mixture of multiple speakers in a streaming manner. Implementing real-time TSE is challenging as the computational complexity must be reduced to provide real-time operation. This work introduces to Conv-TasNet-based TSE a new architecture based on state space modeling (SSM) that has been shown to model long-term dependency effectively. Owing to SSM, fewer dilated convolutional layers are required to capture temporal dependency in Conv-TasNet, resulting in the reduction of model complexity. We also enlarge the window length and shift of the convolutional (TasNet) frontend encoder to reduce the computational cost further; the performance decline is compensated by over-parameterization of the frontend encoder. The proposed method reduces the real-time factor by 78% from the conventional causal Conv-TasNet-based TSE while matching its performance.