 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Speaker Embedding
Paper and Code
Oct 16, 2024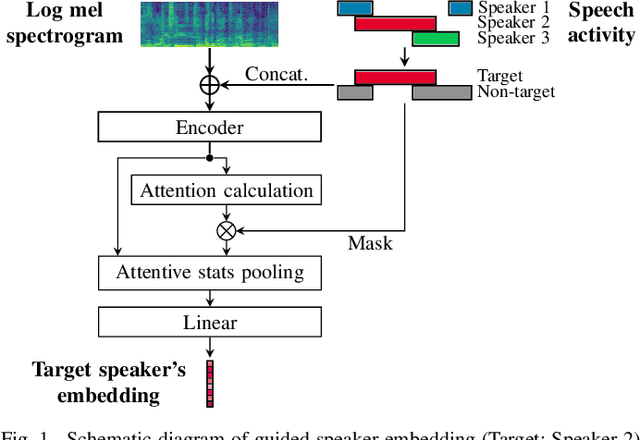

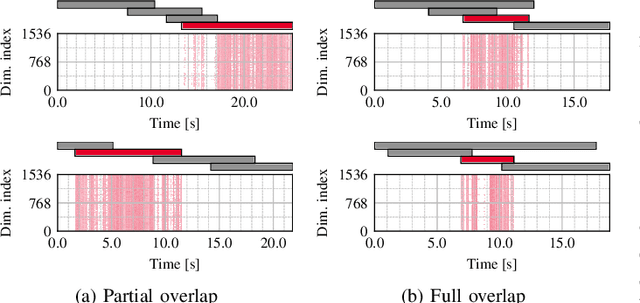

This paper proposes a guided speaker embedding extraction system, which extracts speaker embeddings of the target speaker using speech activities of target and interference speakers as clues. Several methods for long-form overlapped multi-speaker audio processing are typically two-staged: i) segment-level processing and ii) inter-segment speaker matching. Speaker embeddings are often used for the latter purpose. Typical speaker embedding extraction approaches only use single-speaker intervals to avoid corrupting the embeddings with speech from interference speakers. However, this often makes speaker embeddings impossible to extract because sufficiently long non-overlapping intervals are not always available. In this paper, we propose using speaker activities as clues to extract the embedding of the speaker-of-interest directly from overlapping speech. Specifically, we concatenate the activity of target and non-target speakers to acoustic features before being fed to the model. We also condition the attention weights used for pooling so that the attention weights of the intervals in which the target speaker is inactive are zero. The effectiveness of the proposed method is demonstrated in speaker verification and speaker diarization.