 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Alignment Objectives for Aligner-Encoder based ASR
Jun 23, 2026Aligner-Encoders are recently proposed seq2seq end-to-end ASR models that replace decoder attention by predicting the uth token directly from the u-th encoder position, so the encoder must learn the alignment internally without cross-attention or a transducer lattice. In practice, this alignment often forms abruptly in the upper layers, making training sensitive and brittle on long utterances. We propose InterAligner, which adds an intermediate Aligner objective so alignment can form progressively across depth, together with an intermediate CTC loss (InterCTC) to stabilize optimization. On LibriSpeech with a 17-layer Conformer, a final-only Aligner reaches 5.0/7.8 WER (test-clean/other). InterCTC improves to 3.4/6.0, and InterAligner further reduces WER to 3.1/5.6 with the largest gains on long utterances.
All-in-One ASR: Unifying Encoder-Decoder Models of CTC, Attention, and Transducer in Dual-Mode ASR
Dec 12, 2025This paper proposes a unified framework, All-in-One ASR, that allows a single model to support multiple automatic speech recognition (ASR) paradigms, including connectionist temporal classification (CTC), attention-based encoder-decoder (AED), and Transducer, in both offline and streaming modes. While each ASR architecture offers distinct advantages and trade-offs depending on the application, maintaining separate models for each scenario incurs substantial development and deployment costs. To address this issue, we introduce a multi-mode joiner that enables seamless integration of various ASR modes within a single unified model. Experiments show that All-in-One ASR significantly reduces the total model footprint while matching or even surpassing the recognition performance of individually optimized ASR models. Furthermore, joint decoding leverages the complementary strengths of different ASR modes, yielding additional improvements in recognition accuracy.
Generic Speech Enhancement with Self-Supervised Representation Space Loss
Jul 10, 2025


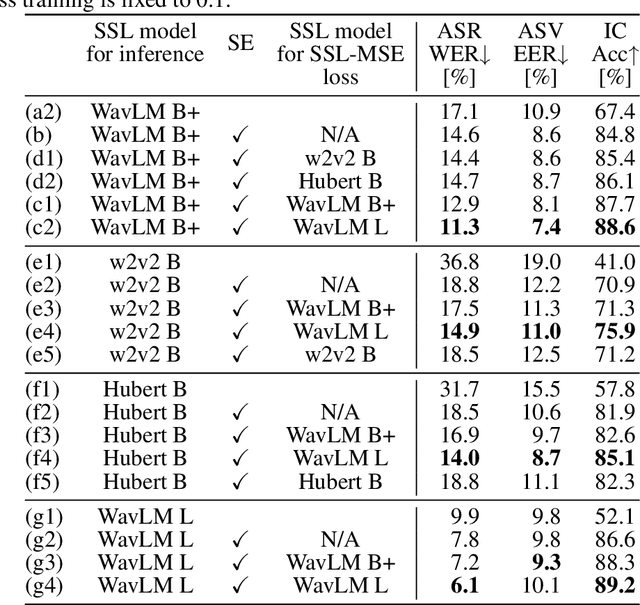
Single-channel speech enhancement is utilized in various tasks to mitigate the effect of interfering signals. Conventionally, to ensure the speech enhancement performs optimally, the speech enhancement has needed to be tuned for each task. Thus, generalizing speech enhancement models to unknown downstream tasks has been challenging. This study aims to construct a generic speech enhancement front-end that can improve the performance of back-ends to solve multiple downstream tasks. To this end, we propose a novel training criterion that minimizes the distance between the enhanced and the ground truth clean signal in the feature representation domain of self-supervised learning models. Since self-supervised learning feature representations effectively express high-level speech information useful for solving various downstream tasks, the proposal is expected to make speech enhancement models preserve such information. Experimental validation demonstrates that the proposal improves the performance of multiple speech tasks while maintaining the perceptual quality of the enhanced signal.
* 22 pages, 3 figures. Accepted for Frontiers in signal processing
Guided Speaker Embedding
Oct 16, 2024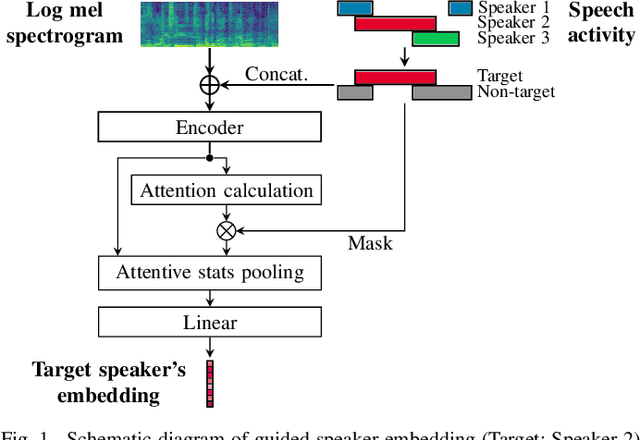

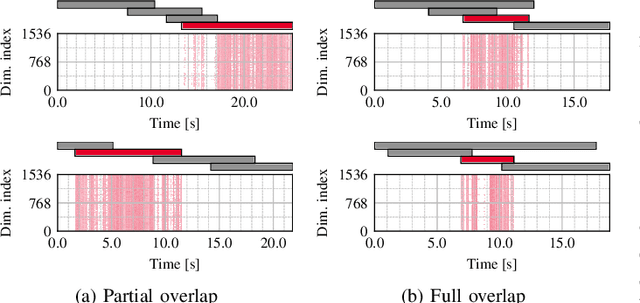

This paper proposes a guided speaker embedding extraction system, which extracts speaker embeddings of the target speaker using speech activities of target and interference speakers as clues. Several methods for long-form overlapped multi-speaker audio processing are typically two-staged: i) segment-level processing and ii) inter-segment speaker matching. Speaker embeddings are often used for the latter purpose. Typical speaker embedding extraction approaches only use single-speaker intervals to avoid corrupting the embeddings with speech from interference speakers. However, this often makes speaker embeddings impossible to extract because sufficiently long non-overlapping intervals are not always available. In this paper, we propose using speaker activities as clues to extract the embedding of the speaker-of-interest directly from overlapping speech. Specifically, we concatenate the activity of target and non-target speakers to acoustic features before being fed to the model. We also condition the attention weights used for pooling so that the attention weights of the intervals in which the target speaker is inactive are zero. The effectiveness of the proposed method is demonstrated in speaker verification and speaker diarization.
Investigation of Speaker Representation for Target-Speaker Speech Processing
Oct 15, 2024
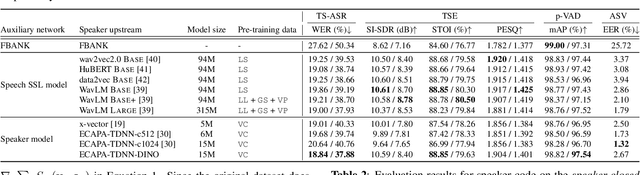


Target-speaker speech processing (TS) tasks, such as target-speaker automatic speech recognition (TS-ASR), target speech extraction (TSE), and personal voice activity detection (p-VAD), are important for extracting information about a desired speaker's speech even when it is corrupted by interfering speakers. While most studies have focused on training schemes or system architectures for each specific task, the auxiliary network for embedding target-speaker cues has not been investigated comprehensively in a unified cross-task evaluation. Therefore, this paper aims to address a fundamental question: what is the preferred speaker embedding for TS tasks? To this end, for the TS-ASR, TSE, and p-VAD tasks, we compare pre-trained speaker encoders (i.e., self-supervised or speaker recognition models) that compute speaker embeddings from pre-recorded enrollment speech of the target speaker with ideal speaker embeddings derived directly from the target speaker's identity in the form of a one-hot vector. To further understand the properties of ideal speaker embedding, we optimize it using a gradient-based approach to improve performance on the TS task. Our analysis reveals that speaker verification performance is somewhat unrelated to TS task performances, the one-hot vector outperforms enrollment-based ones, and the optimal embedding depends on the input mixture.
Alignment-Free Training for Transducer-based Multi-Talker ASR
Sep 30, 2024

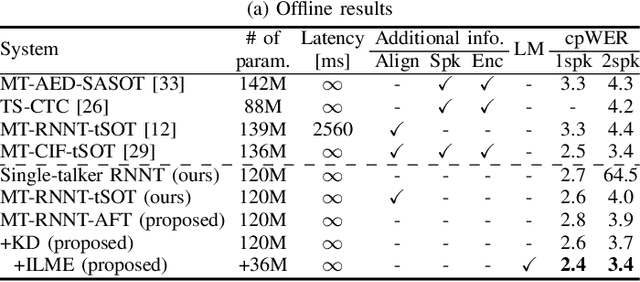
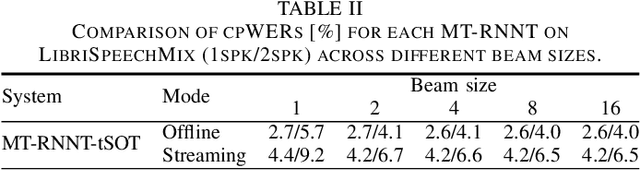
Extending the RNN Transducer (RNNT) to recognize multi-talker speech is essential for wider automatic speech recognition (ASR) applications. Multi-talker RNNT (MT-RNNT) aims to achieve recognition without relying on costly front-end source separation. MT-RNNT is conventionally implemented using architectures with multiple encoders or decoders, or by serializing all speakers' transcriptions into a single output stream. The first approach is computationally expensive, particularly due to the need for multiple encoder processing. In contrast, the second approach involves a complex label generation process, requiring accurate timestamps of all words spoken by all speakers in the mixture, obtained from an external ASR system. In this paper, we propose a novel alignment-free training scheme for the MT-RNNT (MT-RNNT-AFT) that adopts the standard RNNT architecture. The target labels are created by appending a prompt token corresponding to each speaker at the beginning of the transcription, reflecting the order of each speaker's appearance in the mixtures. Thus, MT-RNNT-AFT can be trained without relying on accurate alignments, and it can recognize all speakers' speech with just one round of encoder processing. Experiments show that MT-RNNT-AFT achieves performance comparable to that of the state-of-the-art alternatives, while greatly simplifying the training process.
Boosting Hybrid Autoregressive Transducer-based ASR with Internal Acoustic Model Training and Dual Blank Thresholding
Sep 30, 2024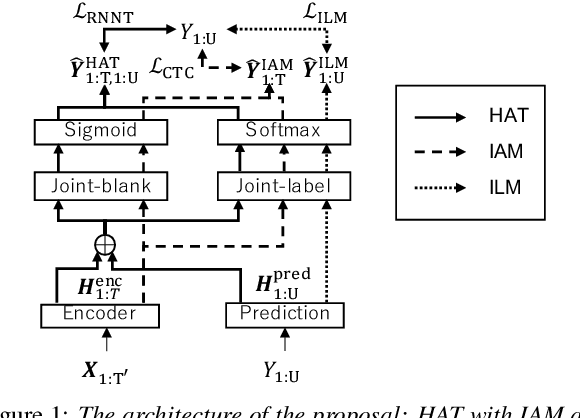
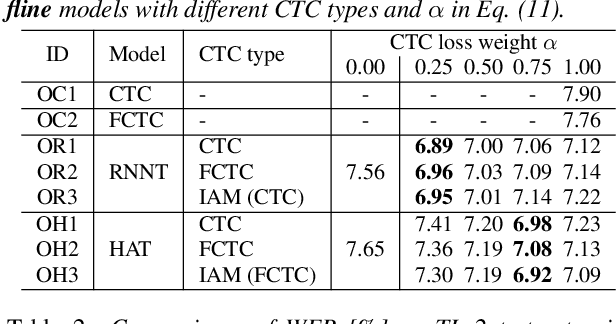
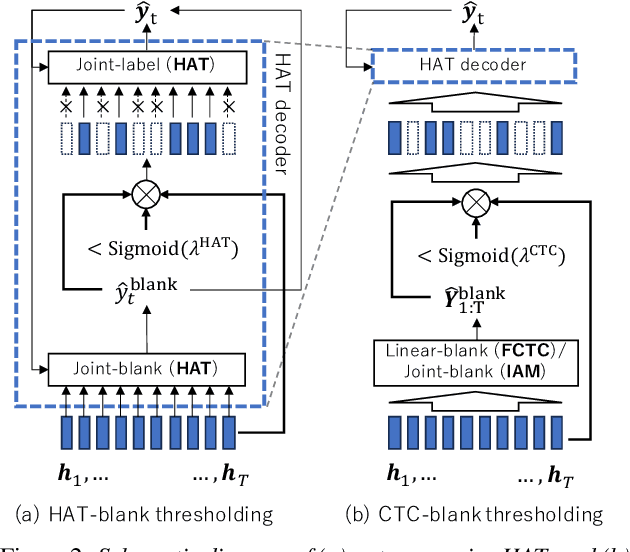
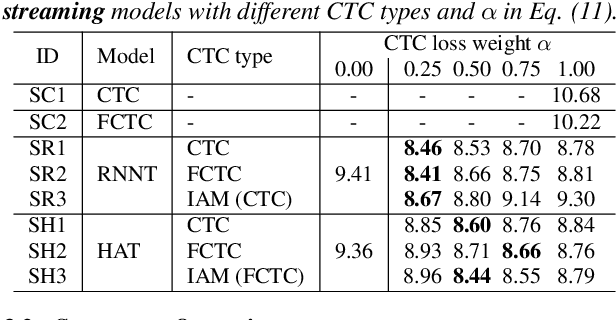
A hybrid autoregressive transducer (HAT) is a variant of neural transducer that models blank and non-blank posterior distributions separately. In this paper, we propose a novel internal acoustic model (IAM) training strategy to enhance HAT-based speech recognition. IAM consists of encoder and joint networks, which are fully shared and jointly trained with HAT. This joint training not only enhances the HAT training efficiency but also encourages IAM and HAT to emit blanks synchronously which skips the more expensive non-blank computation, resulting in more effective blank thresholding for faster decoding. Experiments demonstrate that the relative error reductions of the HAT with IAM compared to the vanilla HAT are statistically significant. Moreover, we introduce dual blank thresholding, which combines both HAT- and IAM-blank thresholding and a compatible decoding algorithm. This results in a 42-75% decoding speed-up with no major performance degradation.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024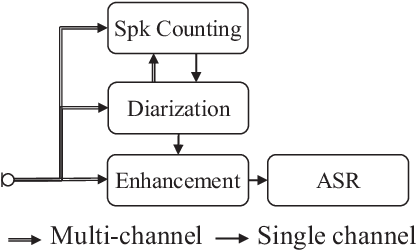
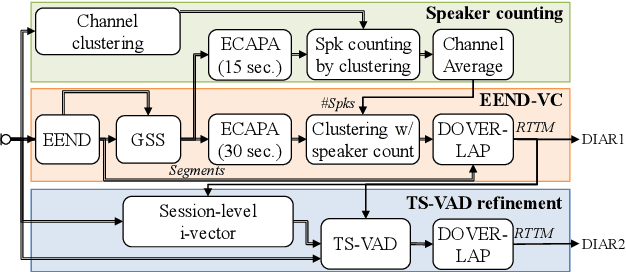

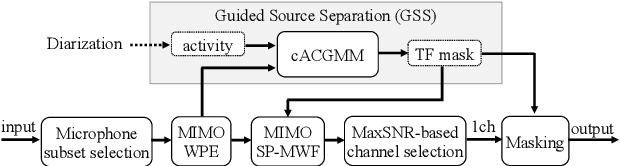
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Recursive Attentive Pooling for Extracting Speaker Embeddings from Multi-Speaker Recordings
Aug 30, 2024



This paper proposes a method for extracting speaker embedding for each speaker from a variable-length recording containing multiple speakers. Speaker embeddings are crucial not only for speaker recognition but also for various multi-speaker speech applications such as speaker diarization and target-speaker speech processing. Despite the challenges of obtaining a single speaker's speech without pre-registration in multi-speaker scenarios, most studies on speaker embedding extraction focus on extracting embeddings only from single-speaker recordings. Some methods have been proposed for extracting speaker embeddings directly from multi-speaker recordings, but they typically require preparing a model for each possible number of speakers or involve complicated training procedures. The proposed method computes the embeddings of multiple speakers by focusing on different parts of the frame-wise embeddings extracted from the input multi-speaker audio. This is achieved by recursively computing attention weights for pooling the frame-wise embeddings. Additionally, we propose using the calculated attention weights to estimate the number of speakers in the recording, which allows the same model to be applied to various numbers of speakers. Experimental evaluations demonstrate the effectiveness of the proposed method in speaker verification and diarization tasks.
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Aug 01, 2024



This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.