 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVER: Combining Multiple Meeting Recognition Systems
Aug 07, 2025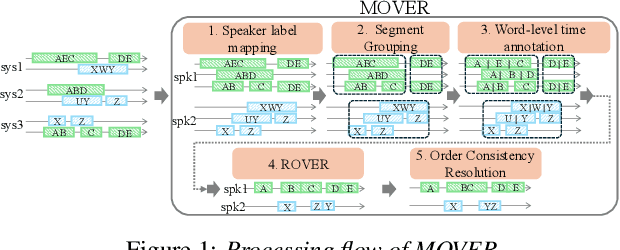


In this paper, we propose Meeting recognizer Output Voting Error Reduction (MOVER), a novel system combination method for meeting recognition tasks. Although there are methods to combine the output of diarization (e.g., DOVER) or automatic speech recognition (ASR) systems (e.g., ROVER), MOVER is the first approach that can combine the outputs of meeting recognition systems that differ in terms of both diarization and ASR. MOVER combines hypotheses with different time intervals and speaker labels through a five-stage process that includes speaker alignment, segment grouping, word and timing combination, etc. Experimental results on the CHiME-8 DASR task and the multi-channel track of the NOTSOFAR-1 task demonstrate that MOVER can successfully combine multiple meeting recognition systems with diverse diarization and recognition outputs, achieving relative tcpWER improvements of 9.55 % and 8.51 % over the state-of-the-art systems for both tasks.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024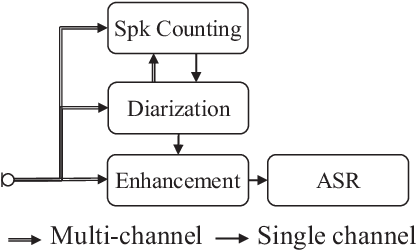
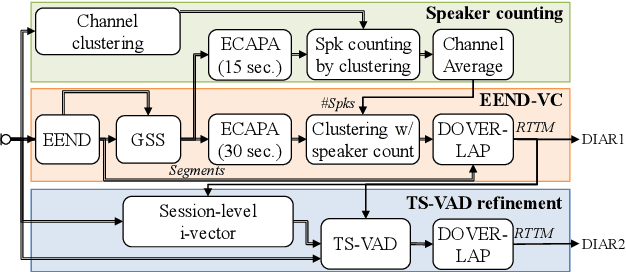

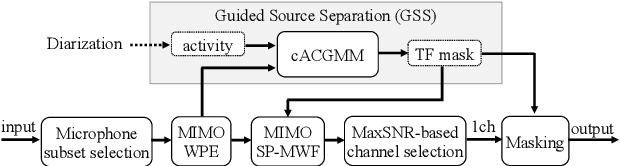
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Applying LLMs for Rescoring N-best ASR Hypotheses of Casual Conversations: Effects of Domain Adaptation and Context Carry-over
Jun 27, 2024Large language models (LLMs) have been successfully applied for rescoring automatic speech recognition (ASR) hypotheses. However, their ability to rescore ASR hypotheses of casual conversations has not been sufficiently explored. In this study, we reveal it by performing N-best ASR hypotheses rescoring using Llama2 on the CHiME-7 distant ASR (DASR) task. Llama2 is one of the most representative LLMs, and the CHiME-7 DASR task provides datasets of casual conversations between multiple participants. We investigate the effects of domain adaptation of the LLM and context carry-over when performing N-best rescoring. Experimental results show that, even without domain adaptation, Llama2 outperforms a standard-size domain-adapted Transformer-LM, especially when using a long context. Domain adaptation shortens the context length needed with Llama2 to achieve its best performance, i.e., it reduces the computational cost of Llama2.
Iterative Shallow Fusion of Backward Language Model for End-to-End Speech Recognition
Oct 17, 2023We propose a new shallow fusion (SF) method to exploit an external backward language model (BLM) for end-to-end automatic speech recognition (ASR). The BLM has complementary characteristics with a forward language model (FLM), and the effectiveness of their combination has been confirmed by rescoring ASR hypotheses as post-processing. In the proposed SF, we iteratively apply the BLM to partial ASR hypotheses in the backward direction (i.e., from the possible next token to the start symbol) during decoding, substituting the newly calculated BLM scores for the scores calculated at the last iteration. To enhance the effectiveness of this iterative SF (ISF), we train a partial sentence-aware BLM (PBLM) using reversed text data including partial sentences, considering the framework of ISF. In experiments using an attention-based encoder-decoder ASR system, we confirmed that ISF using the PBLM shows comparable performance with SF using the FLM. By performing ISF, early pruning of prospective hypotheses can be prevented during decoding, and we can obtain a performance improvement compared to applying the PBLM as post-processing. Finally, we confirmed that, by combining SF and ISF, further performance improvement can be obtained thanks to the complementarity of the FLM and PBLM.
Target Speech Extraction with Conditional Diffusion Model
Aug 17, 2023



Diffusion model-based speech enhancement has received increased attention since it can generate very natural enhanced signals and generalizes well to unseen conditions. Diffusion models have been explored for several sub-tasks of speech enhancement, such as speech denoising, dereverberation, and source separation. In this paper, we investigate their use for target speech extraction (TSE), which consists of estimating the clean speech signal of a target speaker in a mixture of multi-talkers. TSE is realized by conditioning the extraction process on a clue identifying the target speaker. We show we can realize TSE using a conditional diffusion model conditioned on the clue. Besides, we introduce ensemble inference to reduce potential extraction errors caused by the diffusion process. In experiments on Libri2mix corpus, we show that the proposed diffusion model-based TSE combined with ensemble inference outperforms a comparable TSE system trained discriminatively.
Learning to Enhance or Not: Neural Network-Based Switching of Enhanced and Observed Signals for Overlapping Speech Recognition
Jan 11, 2022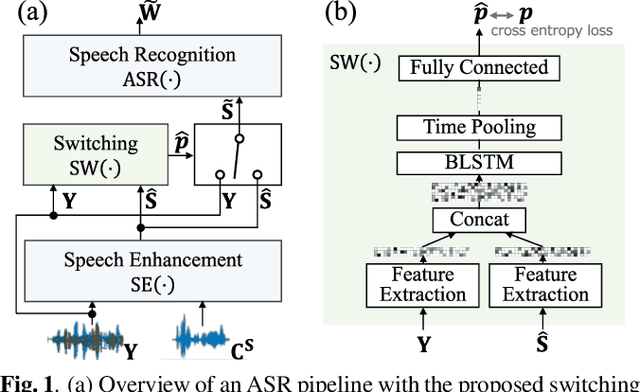
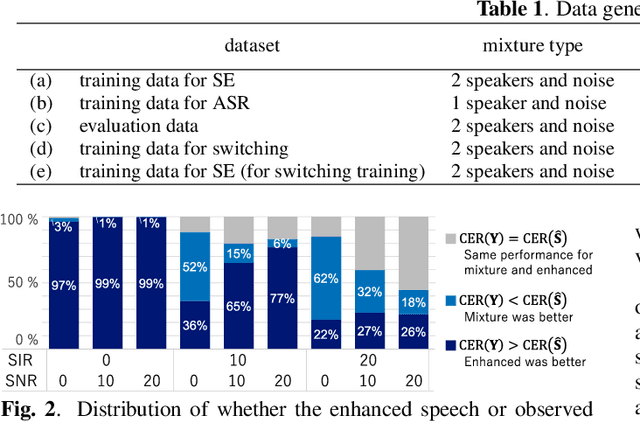
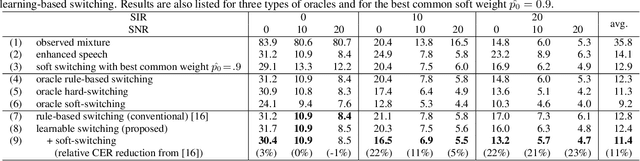
The combination of a deep neural network (DNN) -based speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end is a widely used approach to implement overlapping speech recognition. However, the SE front-end generates processing artifacts that can degrade the ASR performance. We previously found that such performance degradation can occur even under fully overlapping conditions, depending on the signal-to-interference ratio (SIR) and signal-to-noise ratio (SNR). To mitigate the degradation, we introduced a rule-based method to switch the ASR input between the enhanced and observed signals, which showed promising results. However, the rule's optimality was unclear because it was heuristically designed and based only on SIR and SNR values. In this work, we propose a DNN-based switching method that directly estimates whether ASR will perform better on the enhanced or observed signals. We also introduce soft-switching that computes a weighted sum of the enhanced and observed signals for ASR input, with weights given by the switching model's output posteriors. The proposed learning-based switching showed performance comparable to that of rule-based oracle switching. The soft-switching further improved the ASR performance and achieved a relative character error rate reduction of up to 23 % as compared with the conventional method.
Switching Independent Vector Analysis and Its Extension to Blind and Spatially Guided Convolutional Beamforming Algorithm
Nov 20, 2021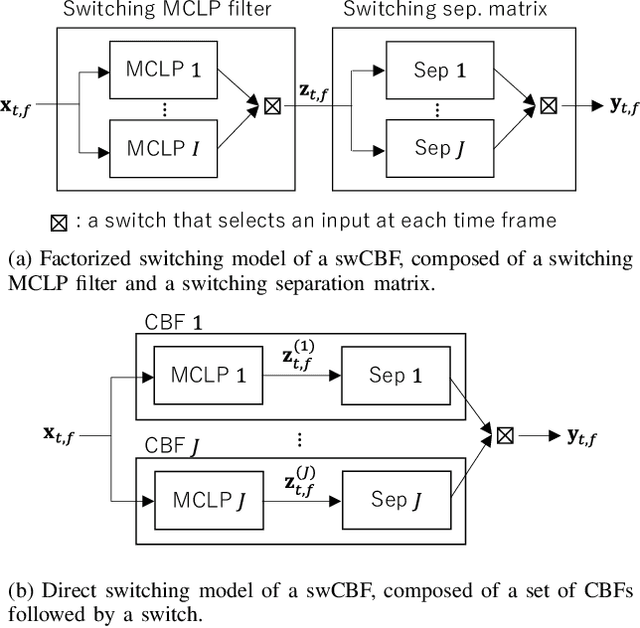
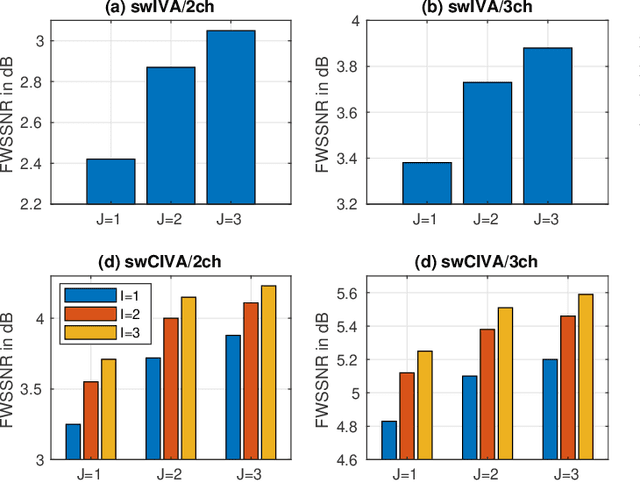
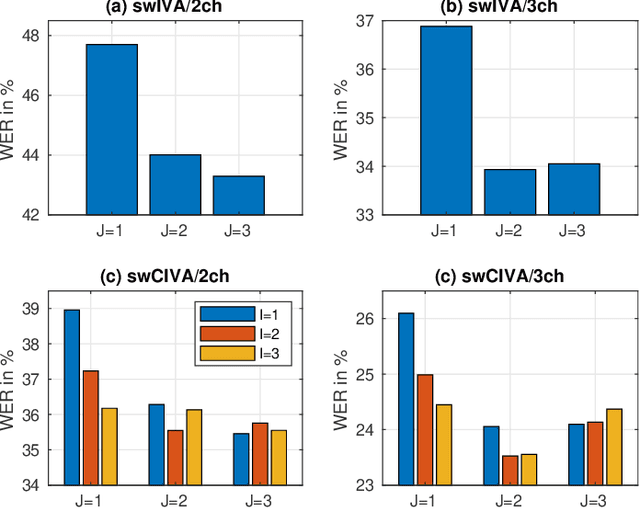
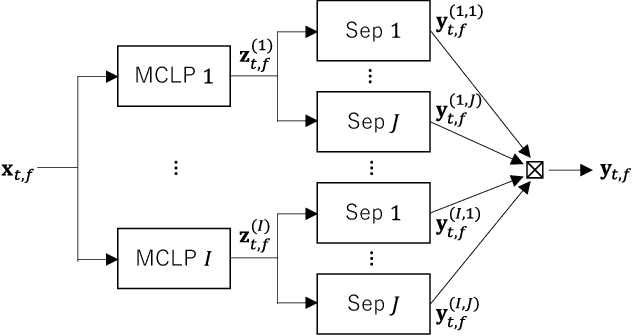
This paper develops a framework that can perform denoising, dereverberation, and source separation accurately by using a relatively small number of microphones. It has been empirically confirmed that Independent Vector Analysis (IVA) can blindly separate $N$ sources from their sound mixture even with diffuse noise when a sufficiently large number ($=M$) of microphones are available (i.e., $M\gg N)$. However, the estimation accuracy seriously degrades as the number of microphones, or more specifically $M-N$ $(\ge 0)$, decreases. To overcome this limitation of IVA, we propose switching IVA (swIVA) in this paper. With swIVA, time frames of an observed signal with time-varying characteristics are clustered into several groups, each of which can be well handled by IVA using a small number of microphones, and thus accurate estimation can be achieved by applying {\IVA} individually to each of the groups. Conventionally, a switching mechanism was introduced into a beamformer; however, no blind source separation algorithms with a switching mechanism have been successfully developed until this paper. In order to incorporate dereverberation capability, this paper further extends swIVA to blind Convolutional beamforming algorithm (swCIVA). It integrates swIVA and switching Weighted Prediction Error-based dereverberation (swWPE) in a jointly optimal way. We show that both swIVA and swIVAconv can be optimized effectively based on blind signal processing, and that their performance can be further improved using a spatial guide for the initialization. Experiments show that the both proposed methods largely outperform conventional IVA and its Convolutional beamforming extension (CIVA) in terms of objective signal quality and automatic speech recognition scores when using a relatively small number of microphones.
Should We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition
Jun 02, 2021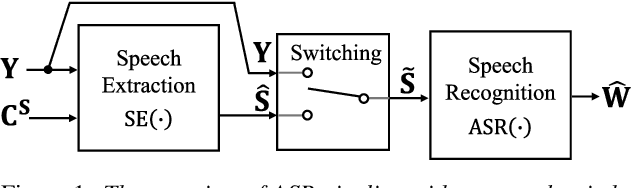
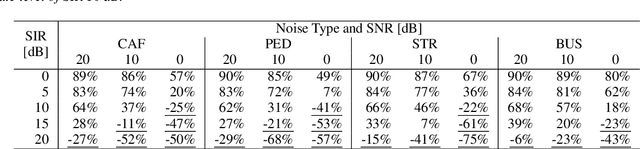
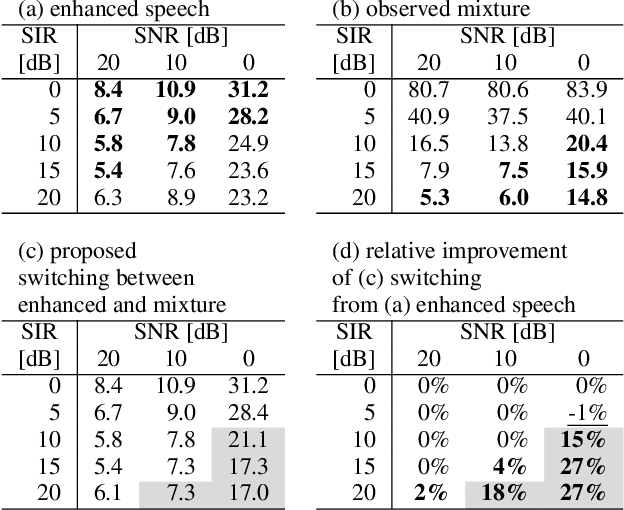
Although recent advances in deep learning technology improved automatic speech recognition (ASR), it remains difficult to recognize speech when it overlaps other people's voices. Speech separation or extraction is often used as a front-end to ASR to handle such overlapping speech. However, deep neural network-based speech enhancement can generate `processing artifacts' as a side effect of the enhancement, which degrades ASR performance. For example, it is well known that single-channel noise reduction for non-speech noise (non-overlapping speech) often does not improve ASR. Likewise, the processing artifacts may also be detrimental to ASR in some conditions when processing overlapping speech with a separation/extraction method, although it is usually believed that separation/extraction improves ASR. In order to answer the question `Do we always have to separate/extract speech from mixtures?', we analyze ASR performance on observed and enhanced speech at various noise and interference conditions, and show that speech enhancement degrades ASR under some conditions even for overlapping speech. Based on these findings, we propose a simple switching algorithm between observed and enhanced speech based on the estimated signal-to-interference ratio and signal-to-noise ratio. We demonstrated experimentally that such a simple switching mechanism can improve recognition performance when processing artifacts are detrimental to ASR.
End-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Feb 23, 2021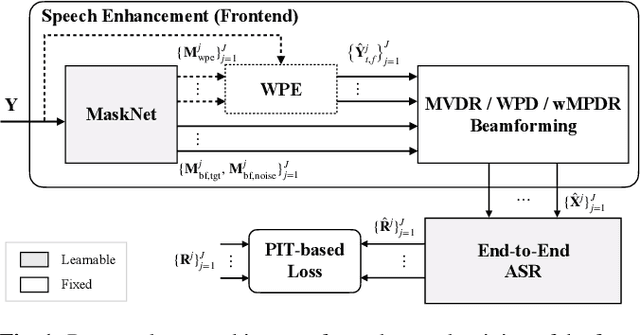
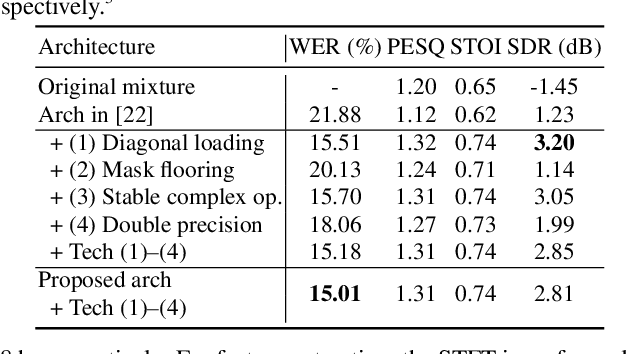
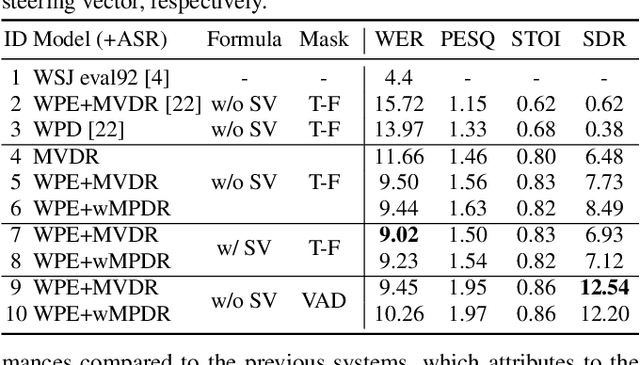
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.
The 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Dec 23, 2020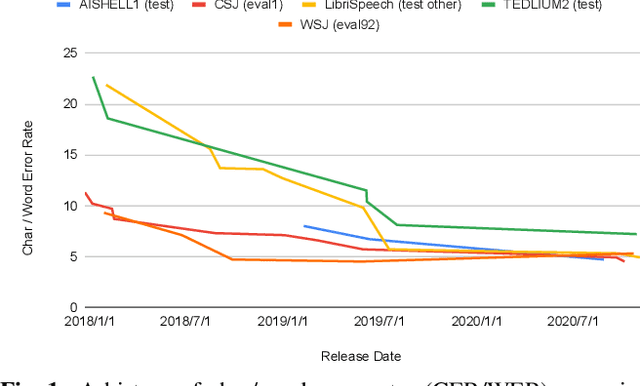

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.