 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Paper and Code
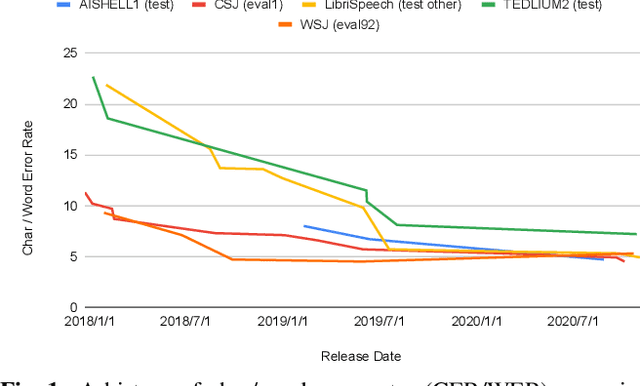

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.