 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025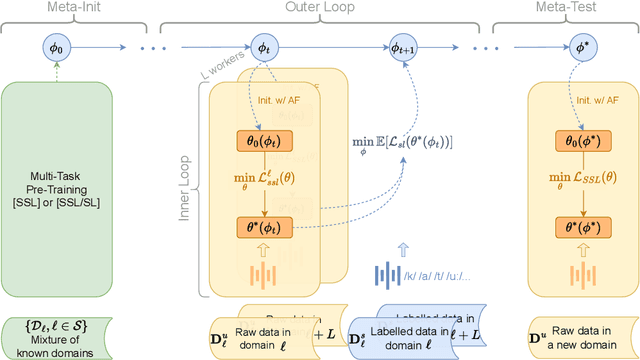

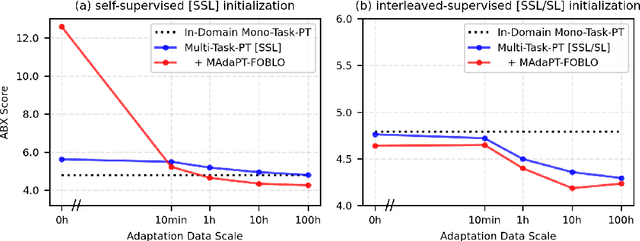
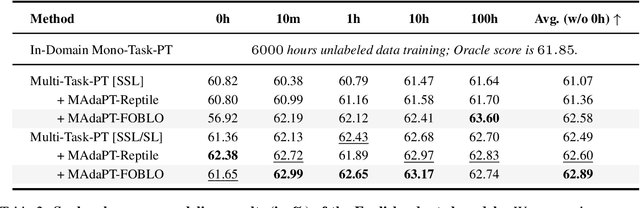
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
End-to-End Speech Recognition with Pre-trained Masked Language Model
Oct 01, 2024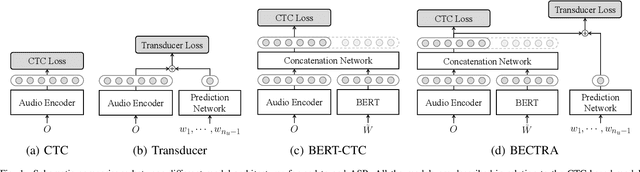
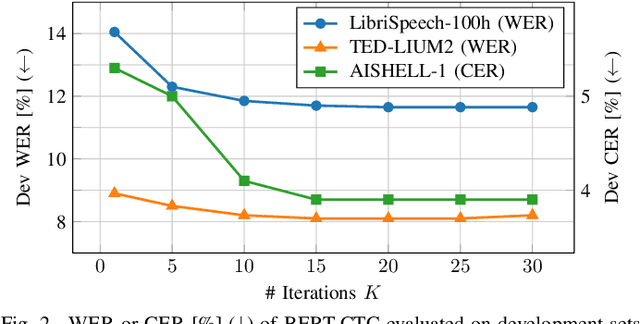
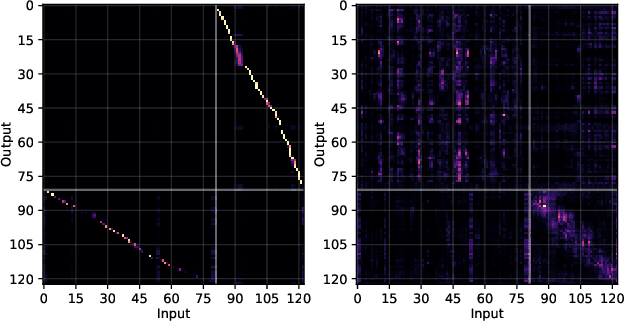

We present a novel approach to end-to-end automatic speech recognition (ASR) that utilizes pre-trained masked language models (LMs) to facilitate the extraction of linguistic information. The proposed models, BERT-CTC and BECTRA, are specifically designed to effectively integrate pre-trained LMs (e.g., BERT) into end-to-end ASR models. BERT-CTC adapts BERT for connectionist temporal classification (CTC) by addressing the constraint of the conditional independence assumption between output tokens. This enables explicit conditioning of BERT's contextualized embeddings in the ASR process, seamlessly merging audio and linguistic information through an iterative refinement algorithm. BECTRA extends BERT-CTC to the transducer framework and trains the decoder network using a vocabulary suitable for ASR training. This aims to bridge the gap between the text processed in end-to-end ASR and BERT, as these models have distinct vocabularies with varying text formats and styles, such as the presence of punctuation. Experimental results on various ASR tasks demonstrate that the proposed models improve over both the CTC and transducer-based baselines, owing to the incorporation of BERT knowledge. Moreover, our in-depth analysis and investigation verify the effectiveness of the proposed formulations and architectural designs.
Predictive Speech Recognition and End-of-Utterance Detection Towards Spoken Dialog Systems
Sep 30, 2024
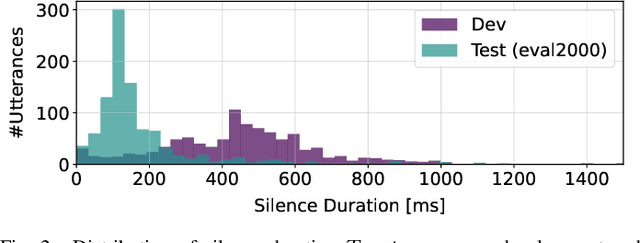
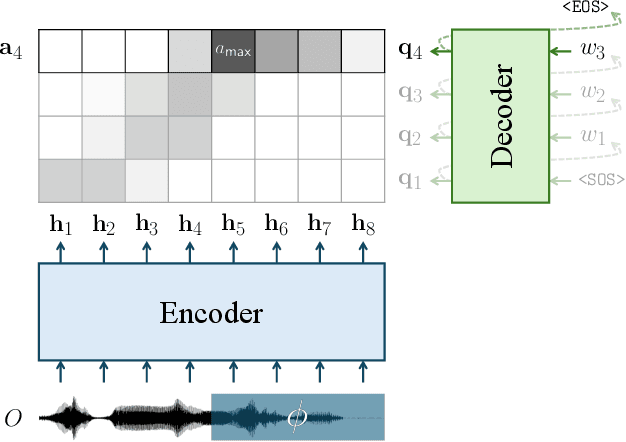
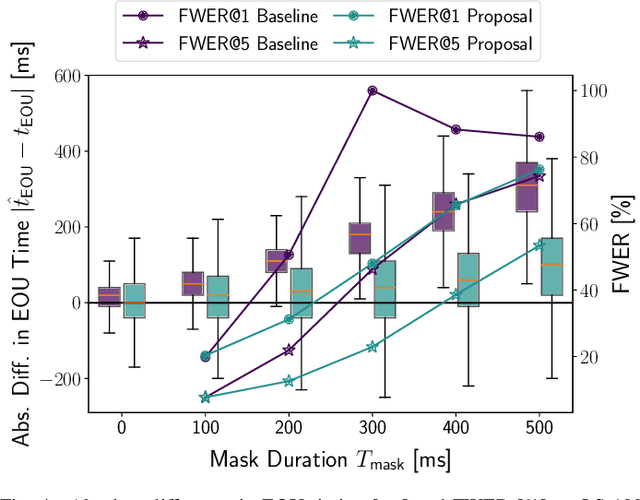
Effective spoken dialog systems should facilitate natural interactions with quick and rhythmic timing, mirroring human communication patterns. To reduce response times, previous efforts have focused on minimizing the latency in automatic speech recognition (ASR) to optimize system efficiency. However, this approach requires waiting for ASR to complete processing until a speaker has finished speaking, which limits the time available for natural language processing (NLP) to formulate accurate responses. As humans, we continuously anticipate and prepare responses even while the other party is still speaking. This allows us to respond appropriately without missing the optimal time to speak. In this work, as a pioneering study toward a conversational system that simulates such human anticipatory behavior, we aim to realize a function that can predict the forthcoming words and estimate the time remaining until the end of an utterance (EOU), using the middle portion of an utterance. To achieve this, we propose a training strategy for an encoder-decoder-based ASR system, which involves masking future segments of an utterance and prompting the decoder to predict the words in the masked audio. Additionally, we develop a cross-attention-based algorithm that incorporates both acoustic and linguistic information to accurately detect the EOU. The experimental results demonstrate the proposed model's ability to predict upcoming words and estimate future EOU events up to 300ms prior to the actual EOU. Moreover, the proposed training strategy exhibits general improvements in ASR performance.
Segment-Level Vectorized Beam Search Based on Partially Autoregressive Inference
Oct 01, 2023



Attention-based encoder-decoder models with autoregressive (AR) decoding have proven to be the dominant approach for automatic speech recognition (ASR) due to their superior accuracy. However, they often suffer from slow inference. This is primarily attributed to the incremental calculation of the decoder. This work proposes a partially AR framework, which employs segment-level vectorized beam search for improving the inference speed of an ASR model based on the hybrid connectionist temporal classification (CTC) attention-based architecture. It first generates an initial hypothesis using greedy CTC decoding, identifying low-confidence tokens based on their output probabilities. We then utilize the decoder to perform segment-level vectorized beam search on these tokens, re-predicting in parallel with minimal decoder calculations. Experimental results show that our method is 12 to 13 times faster in inference on the LibriSpeech corpus over AR decoding whilst preserving high accuracy.
Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Sep 19, 2023



We present a novel integration of an instruction-tuned large language model (LLM) and end-to-end automatic speech recognition (ASR). Modern LLMs can perform a wide range of linguistic tasks within zero-shot learning when provided with a precise instruction or a prompt to guide the text generation process towards the desired task. We explore using this zero-shot capability of LLMs to extract linguistic information that can contribute to improving ASR performance. Specifically, we direct an LLM to correct grammatical errors in an ASR hypothesis and harness the embedded linguistic knowledge to conduct end-to-end ASR. The proposed model is built on the hybrid connectionist temporal classification (CTC) and attention architecture, where an instruction-tuned LLM (i.e., Llama2) is employed as a front-end of the decoder. An ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding, which is then fed into the LLM along with an instruction. The decoder subsequently takes as input the LLM embeddings to perform sequence generation, incorporating acoustic information from the encoder output. Experimental results and analyses demonstrate that the proposed integration yields promising performance improvements, and our approach largely benefits from LLM-based rescoring.
Mask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023



Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
A Study on the Integration of Pre-trained SSL, ASR, LM and SLU Models for Spoken Language Understanding
Nov 10, 2022



Collecting sufficient labeled data for spoken language understanding (SLU) is expensive and time-consuming. Recent studies achieved promising results by using pre-trained models in low-resource scenarios. Inspired by this, we aim to ask: which (if any) pre-training strategies can improve performance across SLU benchmarks? To answer this question, we employ four types of pre-trained models and their combinations for SLU. We leverage self-supervised speech and language models (LM) pre-trained on large quantities of unpaired data to extract strong speech and text representations. We also explore using supervised models pre-trained on larger external automatic speech recognition (ASR) or SLU corpora. We conduct extensive experiments on the SLU Evaluation (SLUE) benchmark and observe self-supervised pre-trained models to be more powerful, with pre-trained LM and speech models being most beneficial for the Sentiment Analysis and Named Entity Recognition task, respectively.
InterMPL: Momentum Pseudo-Labeling with Intermediate CTC Loss
Nov 02, 2022



This paper presents InterMPL, a semi-supervised learning method of end-to-end automatic speech recognition (ASR) that performs pseudo-labeling (PL) with intermediate supervision. Momentum PL (MPL) trains a connectionist temporal classification (CTC)-based model on unlabeled data by continuously generating pseudo-labels on the fly and improving their quality. In contrast to autoregressive formulations, such as the attention-based encoder-decoder and transducer, CTC is well suited for MPL, or PL-based semi-supervised ASR in general, owing to its simple/fast inference algorithm and robustness against generating collapsed labels. However, CTC generally yields inferior performance than the autoregressive models due to the conditional independence assumption, thereby limiting the performance of MPL. We propose to enhance MPL by introducing intermediate loss, inspired by the recent advances in CTC-based modeling. Specifically, we focus on self-conditional and hierarchical conditional CTC, that apply auxiliary CTC losses to intermediate layers such that the conditional independence assumption is explicitly relaxed. We also explore how pseudo-labels should be generated and used as supervision for intermediate losses. Experimental results in different semi-supervised settings demonstrate that the proposed approach outperforms MPL and improves an ASR model by up to a 12.1% absolute performance gain. In addition, our detailed analysis validates the importance of the intermediate loss.
BECTRA: Transducer-based End-to-End ASR with BERT-Enhanced Encoder
Nov 02, 2022


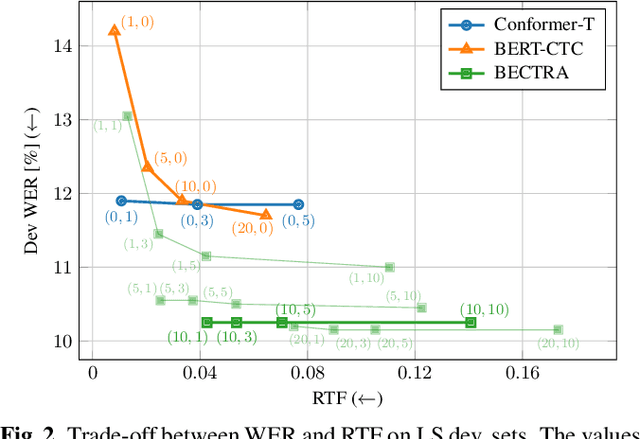
We present BERT-CTC-Transducer (BECTRA), a novel end-to-end automatic speech recognition (E2E-ASR) model formulated by the transducer with a BERT-enhanced encoder. Integrating a large-scale pre-trained language model (LM) into E2E-ASR has been actively studied, aiming to utilize versatile linguistic knowledge for generating accurate text. One crucial factor that makes this integration challenging lies in the vocabulary mismatch; the vocabulary constructed for a pre-trained LM is generally too large for E2E-ASR training and is likely to have a mismatch against a target ASR domain. To overcome such an issue, we propose BECTRA, an extended version of our previous BERT-CTC, that realizes BERT-based E2E-ASR using a vocabulary of interest. BECTRA is a transducer-based model, which adopts BERT-CTC for its encoder and trains an ASR-specific decoder using a vocabulary suitable for a target task. With the combination of the transducer and BERT-CTC, we also propose a novel inference algorithm for taking advantage of both autoregressive and non-autoregressive decoding. Experimental results on several ASR tasks, varying in amounts of data, speaking styles, and languages, demonstrate that BECTRA outperforms BERT-CTC by effectively dealing with the vocabulary mismatch while exploiting BERT knowledge.