 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition with Pre-trained Masked Language Model
Paper and Code
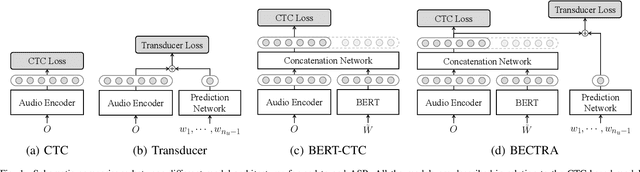
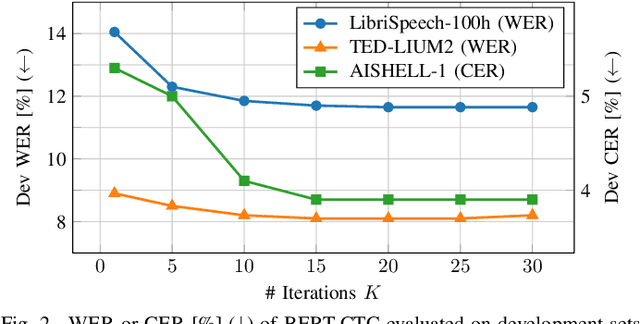
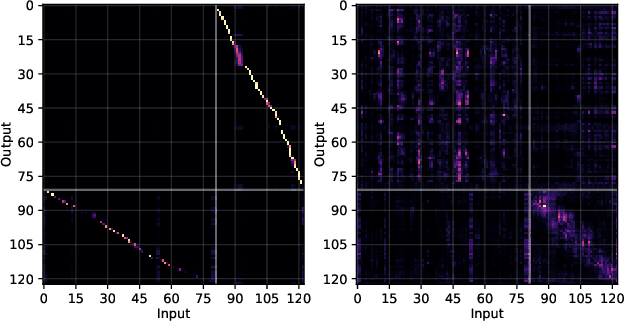

We present a novel approach to end-to-end automatic speech recognition (ASR) that utilizes pre-trained masked language models (LMs) to facilitate the extraction of linguistic information. The proposed models, BERT-CTC and BECTRA, are specifically designed to effectively integrate pre-trained LMs (e.g., BERT) into end-to-end ASR models. BERT-CTC adapts BERT for connectionist temporal classification (CTC) by addressing the constraint of the conditional independence assumption between output tokens. This enables explicit conditioning of BERT's contextualized embeddings in the ASR process, seamlessly merging audio and linguistic information through an iterative refinement algorithm. BECTRA extends BERT-CTC to the transducer framework and trains the decoder network using a vocabulary suitable for ASR training. This aims to bridge the gap between the text processed in end-to-end ASR and BERT, as these models have distinct vocabularies with varying text formats and styles, such as the presence of punctuation. Experimental results on various ASR tasks demonstrate that the proposed models improve over both the CTC and transducer-based baselines, owing to the incorporation of BERT knowledge. Moreover, our in-depth analysis and investigation verify the effectiveness of the proposed formulations and architectural designs.