 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-Distinguishable CTC: Learning Speaker Distinction Using CTC for Multi-Talker Speech Recognition
Jun 09, 2025This paper presents a novel framework for multi-talker automatic speech recognition without the need for auxiliary information. Serialized Output Training (SOT), a widely used approach, suffers from recognition errors due to speaker assignment failures. Although incorporating auxiliary information, such as token-level timestamps, can improve recognition accuracy, extracting such information from natural conversational speech remains challenging. To address this limitation, we propose Speaker-Distinguishable CTC (SD-CTC), an extension of CTC that jointly assigns a token and its corresponding speaker label to each frame. We further integrate SD-CTC into the SOT framework, enabling the SOT model to learn speaker distinction using only overlapping speech and transcriptions. Experimental comparisons show that multi-task learning with SD-CTC and SOT reduces the error rate of the SOT model by 26% and achieves performance comparable to state-of-the-art methods relying on auxiliary information.
A Comparative Study on Positional Encoding for Time-frequency Domain Dual-path Transformer-based Source Separation Models
Apr 28, 2025In this study, we investigate the impact of positional encoding (PE) on source separation performance and the generalization ability to long sequences (length extrapolation) in Transformer-based time-frequency (TF) domain dual-path models. The length extrapolation capability in TF-domain dual-path models is a crucial factor, as it affects not only their performance on long-duration inputs but also their generalizability to signals with unseen sampling rates. While PE is known to significantly impact length extrapolation, there has been limited research that explores the choice of PEs for TF-domain dual-path models from this perspective. To address this gap, we compare various PE methods using a recent state-of-the-art model, TF-Locoformer, as the base architecture. Our analysis yields the following key findings: (i) When handling sequences that are the same length as or shorter than those seen during training, models with PEs achieve better performance. (ii) However, models without PE exhibit superior length extrapolation. This trend is particularly pronounced when the model contains convolutional layers.
End-to-End Speech Recognition with Pre-trained Masked Language Model
Oct 01, 2024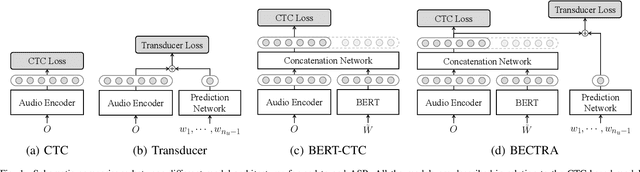
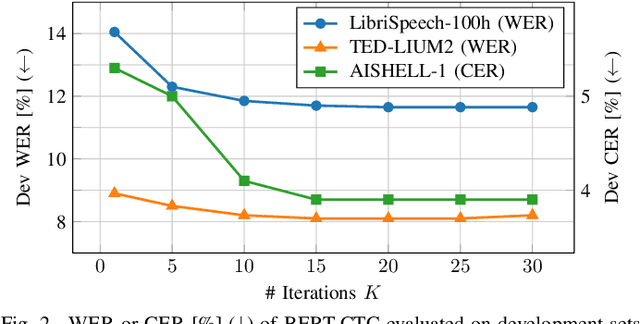
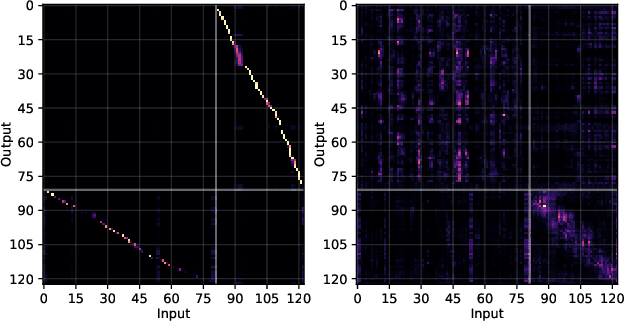

We present a novel approach to end-to-end automatic speech recognition (ASR) that utilizes pre-trained masked language models (LMs) to facilitate the extraction of linguistic information. The proposed models, BERT-CTC and BECTRA, are specifically designed to effectively integrate pre-trained LMs (e.g., BERT) into end-to-end ASR models. BERT-CTC adapts BERT for connectionist temporal classification (CTC) by addressing the constraint of the conditional independence assumption between output tokens. This enables explicit conditioning of BERT's contextualized embeddings in the ASR process, seamlessly merging audio and linguistic information through an iterative refinement algorithm. BECTRA extends BERT-CTC to the transducer framework and trains the decoder network using a vocabulary suitable for ASR training. This aims to bridge the gap between the text processed in end-to-end ASR and BERT, as these models have distinct vocabularies with varying text formats and styles, such as the presence of punctuation. Experimental results on various ASR tasks demonstrate that the proposed models improve over both the CTC and transducer-based baselines, owing to the incorporation of BERT knowledge. Moreover, our in-depth analysis and investigation verify the effectiveness of the proposed formulations and architectural designs.
A Single Speech Enhancement Model Unifying Dereverberation, Denoising, Speaker Counting, Separation, and Extraction
Oct 12, 2023We propose a multi-task universal speech enhancement (MUSE) model that can perform five speech enhancement (SE) tasks: dereverberation, denoising, speech separation (SS), target speaker extraction (TSE), and speaker counting. This is achieved by integrating two modules into an SE model: 1) an internal separation module that does both speaker counting and separation; and 2) a TSE module that extracts the target speech from the internal separation outputs using target speaker cues. The model is trained to perform TSE if the target speaker cue is given and SS otherwise. By training the model to remove noise and reverberation, we allow the model to tackle the five tasks mentioned above with a single model, which has not been accomplished yet. Evaluation results demonstrate that the proposed MUSE model can successfully handle multiple tasks with a single model.
Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Sep 19, 2023



We present a novel integration of an instruction-tuned large language model (LLM) and end-to-end automatic speech recognition (ASR). Modern LLMs can perform a wide range of linguistic tasks within zero-shot learning when provided with a precise instruction or a prompt to guide the text generation process towards the desired task. We explore using this zero-shot capability of LLMs to extract linguistic information that can contribute to improving ASR performance. Specifically, we direct an LLM to correct grammatical errors in an ASR hypothesis and harness the embedded linguistic knowledge to conduct end-to-end ASR. The proposed model is built on the hybrid connectionist temporal classification (CTC) and attention architecture, where an instruction-tuned LLM (i.e., Llama2) is employed as a front-end of the decoder. An ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding, which is then fed into the LLM along with an instruction. The decoder subsequently takes as input the LLM embeddings to perform sequence generation, incorporating acoustic information from the encoder output. Experimental results and analyses demonstrate that the proposed integration yields promising performance improvements, and our approach largely benefits from LLM-based rescoring.
Mask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023



Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
Remixing-based Unsupervised Source Separation from Scratch
Sep 01, 2023


We propose an unsupervised approach for training separation models from scratch using RemixIT and Self-Remixing, which are recently proposed self-supervised learning methods for refining pre-trained models. They first separate mixtures with a teacher model and create pseudo-mixtures by shuffling and remixing the separated signals. A student model is then trained to separate the pseudo-mixtures using either the teacher's outputs or the initial mixtures as supervision. To refine the teacher's outputs, the teacher's weights are updated with the student's weights. While these methods originally assumed that the teacher is pre-trained, we show that they are capable of training models from scratch. We also introduce a simple remixing method to stabilize training. Experimental results demonstrate that the proposed approach outperforms mixture invariant training, which is currently the only available approach for training a monaural separation model from scratch.
Neural Diarization with Non-autoregressive Intermediate Attractors
Mar 13, 2023End-to-end neural diarization (EEND) with encoder-decoder-based attractors (EDA) is a promising method to handle the whole speaker diarization problem simultaneously with a single neural network. While the EEND model can produce all frame-level speaker labels simultaneously, it disregards output label dependency. In this work, we propose a novel EEND model that introduces the label dependency between frames. The proposed method generates non-autoregressive intermediate attractors to produce speaker labels at the lower layers and conditions the subsequent layers with these labels. While the proposed model works in a non-autoregressive manner, the speaker labels are refined by referring to the whole sequence of intermediate labels. The experiments with the two-speaker CALLHOME dataset show that the intermediate labels with the proposed non-autoregressive intermediate attractors boost the diarization performance. The proposed method with the deeper network benefits more from the intermediate labels, resulting in better performance and training throughput than EEND-EDA.
Video Surveillance System Incorporating Expert Decision-making Process: A Case Study on Detecting Calving Signs in Cattle
Jan 10, 2023Through a user study in the field of livestock farming, we verify the effectiveness of an XAI framework for video surveillance systems. The systems can be made interpretable by incorporating experts' decision-making processes. AI systems are becoming increasingly common in real-world applications, especially in fields related to human decision-making, and its interpretability is necessary. However, there are still relatively few standard methods for assessing and addressing the interpretability of machine learning-based systems in real-world applications. In this study, we examine the framework of a video surveillance AI system that presents the reasoning behind predictions by incorporating experts' decision-making processes with rich domain knowledge of the notification target. While general black-box AI systems can only present final probability values, the proposed framework can present information relevant to experts' decisions, which is expected to be more helpful for their decision-making. In our case study, we designed a system for detecting signs of calving in cattle based on the proposed framework and evaluated the system through a user study (N=6) with people involved in livestock farming. A comparison with the black-box AI system revealed that many participants referred to the presented reasons for the prediction results, and five out of six participants selected the proposed system as the system they would like to use in the future. It became clear that we need to design a user interface that considers the reasons for the prediction results.
Self-Remixing: Unsupervised Speech Separation via Separation and Remixing
Nov 18, 2022We present Self-Remixing, a novel self-supervised speech separation method, which refines a pre-trained separation model in an unsupervised manner. The proposed method consists of a shuffler module and a solver module, and they grow together through separation and remixing processes. Specifically, the shuffler first separates observed mixtures and makes pseudo-mixtures by shuffling and remixing the separated signals. The solver then separates the pseudo-mixtures and remixes the separated signals back to the observed mixtures. The solver is trained using the observed mixtures as supervision, while the shuffler's weights are updated by taking the moving average with the solver's, generating the pseudo-mixtures with fewer distortions. Our experiments demonstrate that Self-Remixing gives better performance over existing remixing-based self-supervised methods with the same or less training costs under unsupervised setup. Self-Remixing also outperforms baselines in semi-supervised domain adaptation, showing effectiveness in multiple setups.