 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023



Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
Neural Diarization with Non-autoregressive Intermediate Attractors
Mar 13, 2023End-to-end neural diarization (EEND) with encoder-decoder-based attractors (EDA) is a promising method to handle the whole speaker diarization problem simultaneously with a single neural network. While the EEND model can produce all frame-level speaker labels simultaneously, it disregards output label dependency. In this work, we propose a novel EEND model that introduces the label dependency between frames. The proposed method generates non-autoregressive intermediate attractors to produce speaker labels at the lower layers and conditions the subsequent layers with these labels. While the proposed model works in a non-autoregressive manner, the speaker labels are refined by referring to the whole sequence of intermediate labels. The experiments with the two-speaker CALLHOME dataset show that the intermediate labels with the proposed non-autoregressive intermediate attractors boost the diarization performance. The proposed method with the deeper network benefits more from the intermediate labels, resulting in better performance and training throughput than EEND-EDA.
Conversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022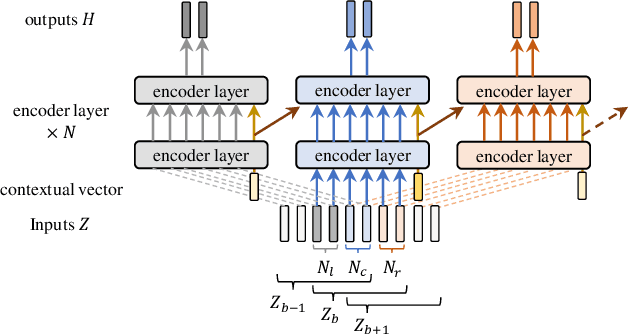
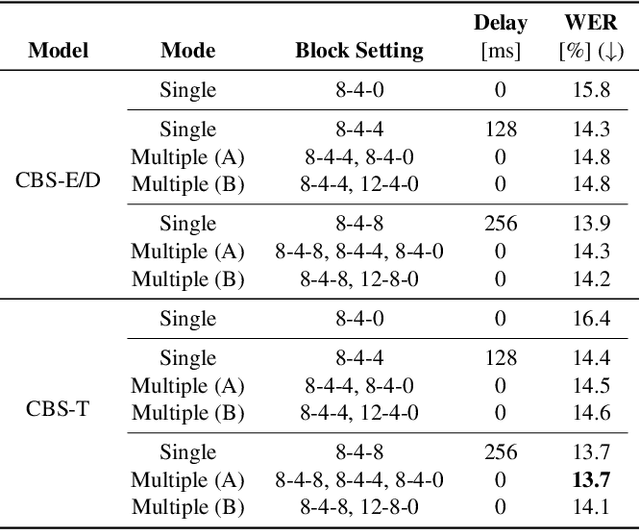
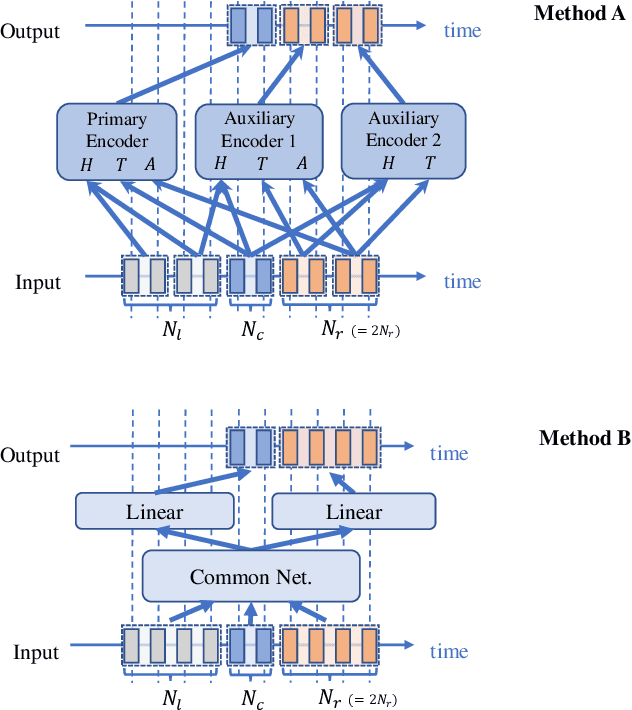
During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.
Tourist Guidance Robot Based on HyperCLOVA
Oct 19, 2022



This paper describes our system submitted to Dialogue Robot Competition 2022. Our proposed system is a combined model of rule-based and generation-based dialog systems. The system utilizes HyperCLOVA, a Japanese foundation model, not only to generate responses but also summarization, search information, etc. We also used our original speech recognition system, which was fine-tuned for this dialog task. As a result, our system ranked second in the preliminary round and moved on to the finals.
Better Intermediates Improve CTC Inference
Apr 01, 2022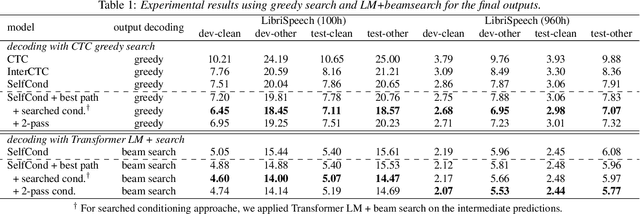

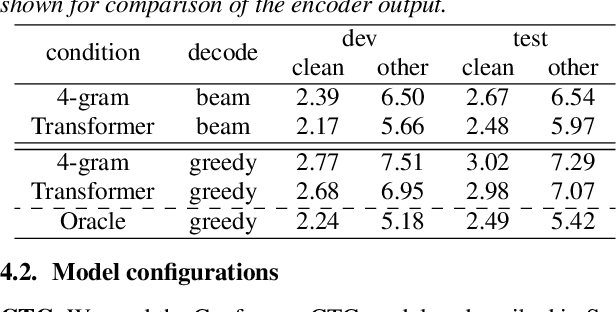
This paper proposes a method for improved CTC inference with searched intermediates and multi-pass conditioning. The paper first formulates self-conditioned CTC as a probabilistic model with an intermediate prediction as a latent representation and provides a tractable conditioning framework. We then propose two new conditioning methods based on the new formulation: (1) Searched intermediate conditioning that refines intermediate predictions with beam-search, (2) Multi-pass conditioning that uses predictions of previous inference for conditioning the next inference. These new approaches enable better conditioning than the original self-conditioned CTC during inference and improve the final performance. Experiments with the LibriSpeech dataset show relative 3%/12% performance improvement at the maximum in test clean/other sets compared to the original self-conditioned CTC.
Multi-sequence Intermediate Conditioning for CTC-based ASR
Apr 01, 2022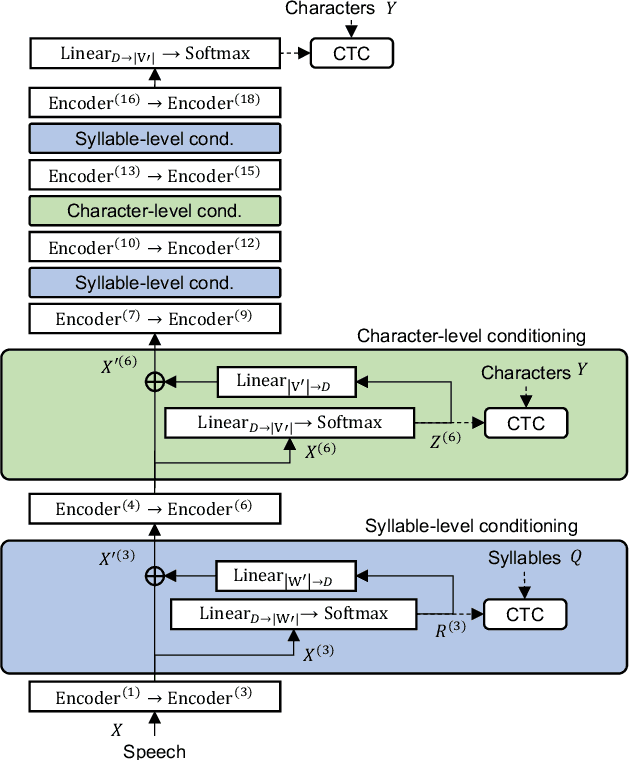
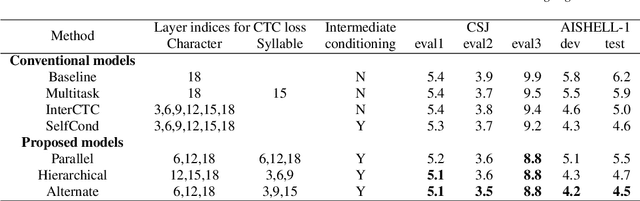


End-to-end automatic speech recognition (ASR) directly maps input speech to a character sequence without using pronunciation lexica. However, in languages with thousands of characters, such as Japanese and Mandarin, modeling all these characters is problematic due to data scarcity. To alleviate the problem, we propose a multi-task learning model with explicit interaction between characters and syllables by utilizing Self-conditioned connectionist temporal classification (CTC) technique. While the original Self-conditioned CTC estimates character-level intermediate predictions by applying auxiliary CTC losses to a set of intermediate layers, the proposed method additionally estimates syllable-level intermediate predictions in another set of intermediate layers. The character-level and syllable-level predictions are alternately used as conditioning features to deal with mutual dependency between characters and syllables. Experimental results on Japanese and Mandarin datasets show that the proposed multi-sequence intermediate conditioning outperformed the conventional multi-task-based and Self-conditioned CTC-based methods.
InterAug: Augmenting Noisy Intermediate Predictions for CTC-based ASR
Apr 01, 2022
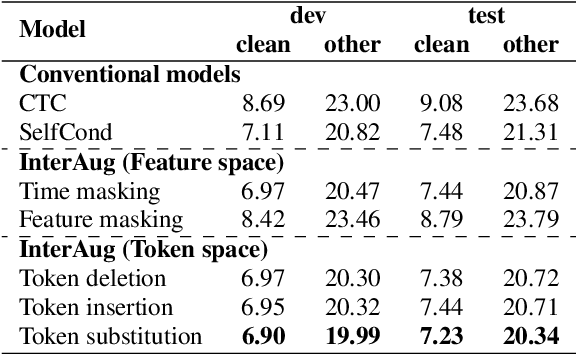
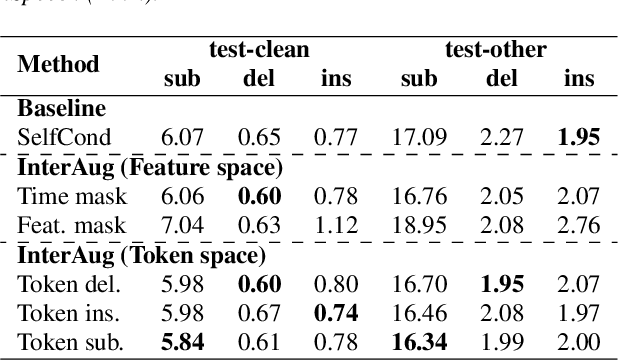
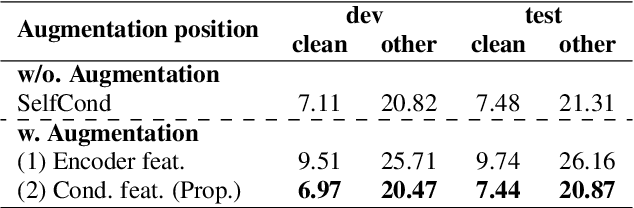
This paper proposes InterAug: a novel training method for CTC-based ASR using augmented intermediate representations for conditioning. The proposed method exploits the conditioning framework of self-conditioned CTC to train robust models by conditioning with "noisy" intermediate predictions. During the training, intermediate predictions are changed to incorrect intermediate predictions, and fed into the next layer for conditioning. The subsequent layers are trained to correct the incorrect intermediate predictions with the intermediate losses. By repeating the augmentation and the correction, iterative refinements, which generally require a special decoder, can be realized only with the audio encoder. To produce noisy intermediate predictions, we also introduce new augmentation: intermediate feature space augmentation and intermediate token space augmentation that are designed to simulate typical errors. The combination of the proposed InterAug framework with new augmentation allows explicit training of the robust audio encoders. In experiments using augmentations simulating deletion, insertion, and substitution error, we confirmed that the trained model acquires robustness to each error, boosting the speech recognition performance of the strong self-conditioned CTC baseline.
Label-Synchronous Speech-to-Text Alignment for ASR Using Forward and Backward Transformers
Apr 21, 2021
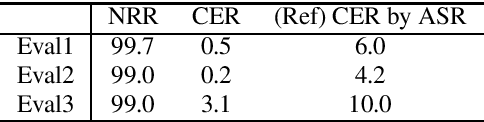
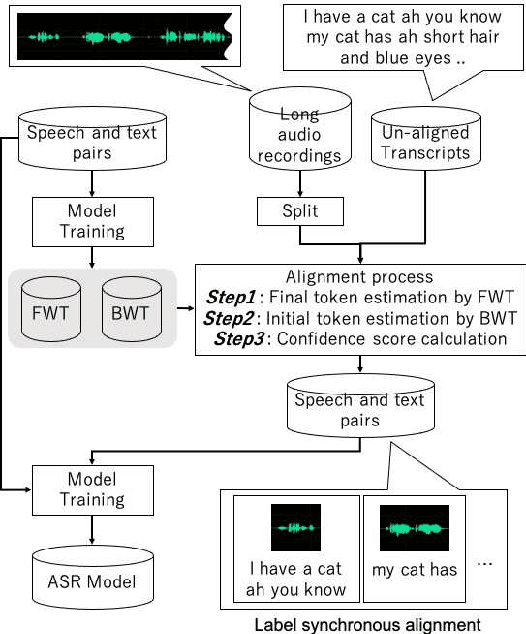
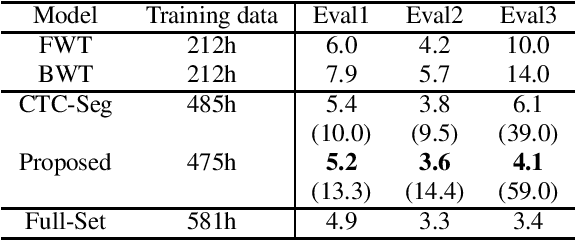
This paper proposes a novel label-synchronous speech-to-text alignment technique for automatic speech recognition (ASR). The speech-to-text alignment is a problem of splitting long audio recordings with un-aligned transcripts into utterance-wise pairs of speech and text. Unlike conventional methods based on frame-synchronous prediction, the proposed method re-defines the speech-to-text alignment as a label-synchronous text mapping problem. This enables an accurate alignment benefiting from the strong inference ability of the state-of-the-art attention-based encoder-decoder models, which cannot be applied to the conventional methods. Two different Transformer models named forward Transformer and backward Transformer are respectively used for estimating an initial and final tokens of a given speech segment based on end-of-sentence prediction with teacher-forcing. Experiments using the corpus of spontaneous Japanese (CSJ) demonstrate that the proposed method provides an accurate utterance-wise alignment, that matches the manually annotated alignment with as few as 0.2% errors. It is also confirmed that a Transformer-based hybrid CTC/Attention ASR model using the aligned speech and text pairs as an additional training data reduces character error rates relatively up to 59.0%, which is significantly better than 39.0% reduction by a conventional alignment method based on connectionist temporal classification model.
Speaker Selective Beamformer with Keyword Mask Estimation
Oct 25, 2018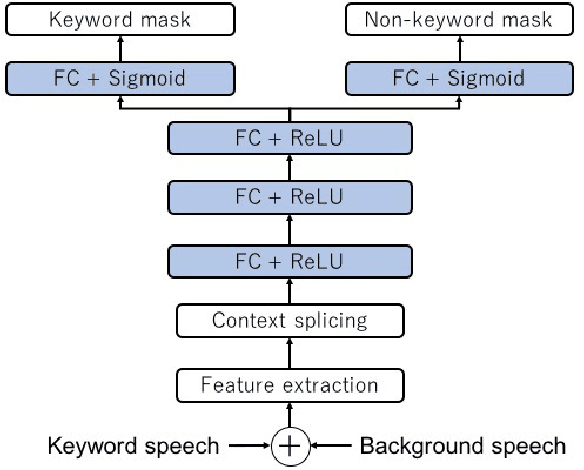

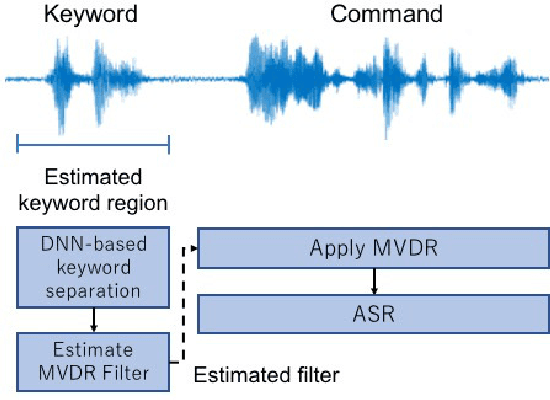
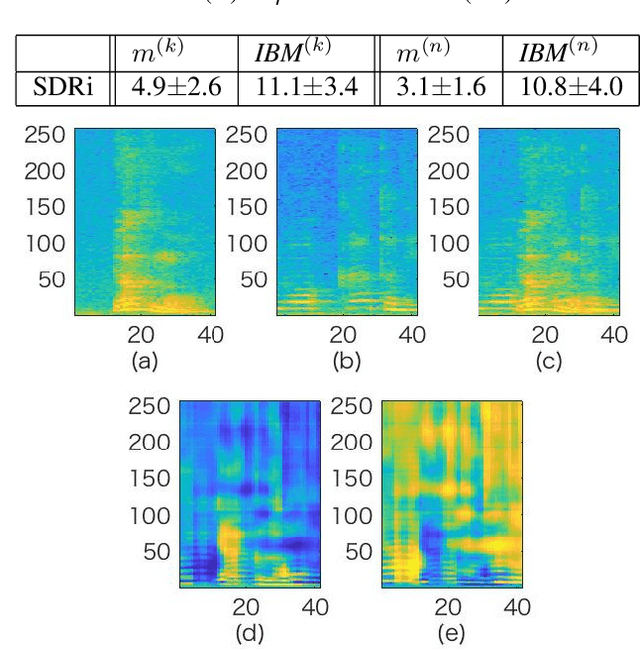
This paper addresses the problem of automatic speech recognition (ASR) of a target speaker in background speech. The novelty of our approach is that we focus on a wakeup keyword, which is usually used for activating ASR systems like smart speakers. The proposed method firstly utilizes a DNN-based mask estimator to separate the mixture signal into the keyword signal uttered by the target speaker and the remaining background speech. Then the separated signals are used for calculating a beamforming filter to enhance the subsequent utterances from the target speaker. Experimental evaluations show that the trained DNN-based mask can selectively separate the keyword and background speech from the mixture signal. The effectiveness of the proposed method is also verified with Japanese ASR experiments, and we confirm that the character error rates are significantly improved by the proposed method for both simulated and real recorded test sets.