 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Conversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022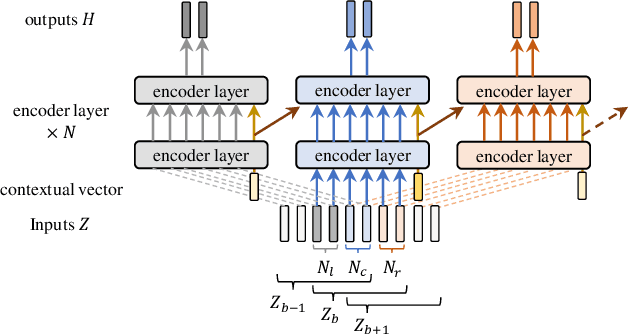
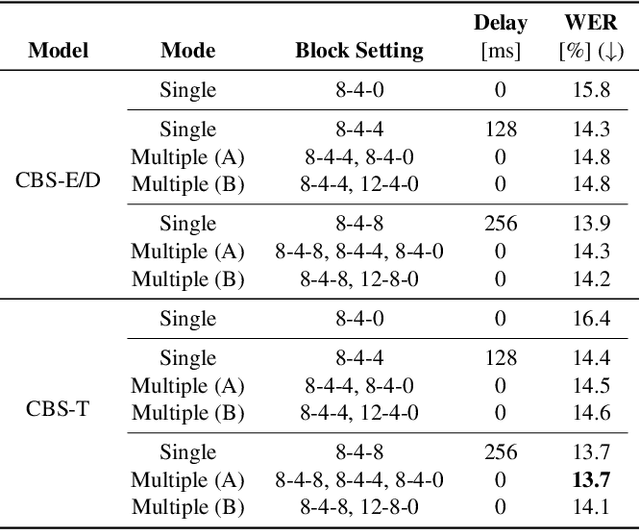
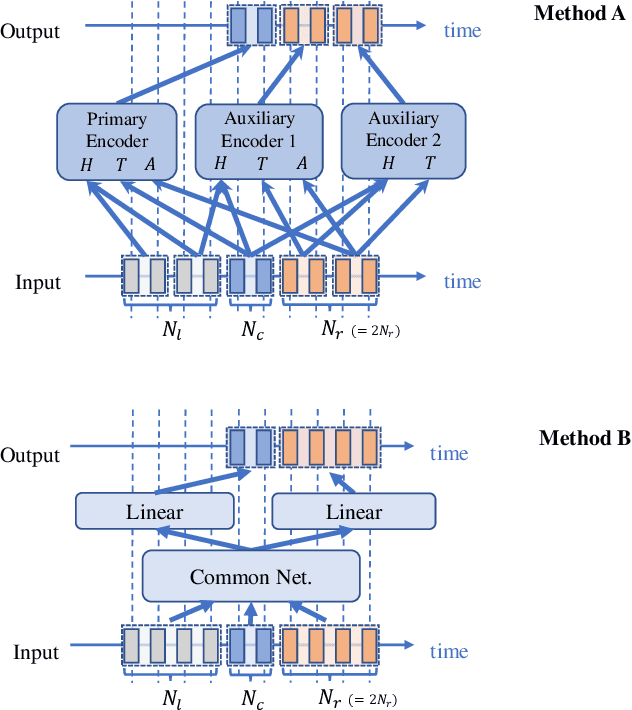
During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.
MLP-ASR: Sequence-length agnostic all-MLP architectures for speech recognition
Feb 17, 2022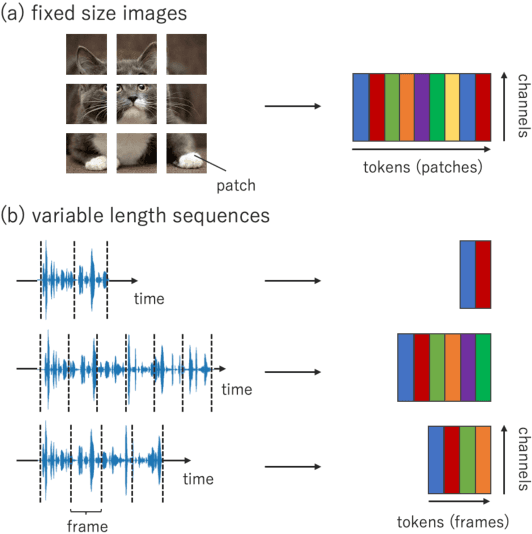

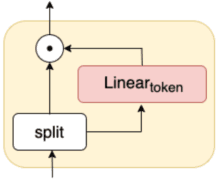
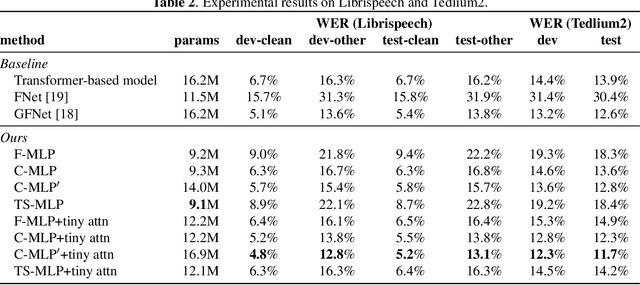
We propose multi-layer perceptron (MLP)-based architectures suitable for variable length input. MLP-based architectures, recently proposed for image classification, can only be used for inputs of a fixed, pre-defined size. However, many types of data are naturally variable in length, for example, acoustic signals. We propose three approaches to extend MLP-based architectures for use with sequences of arbitrary length. The first one uses a circular convolution applied in the Fourier domain, the second applies a depthwise convolution, and the final relies on a shift operation. We evaluate the proposed architectures on an automatic speech recognition task with the Librispeech and Tedlium2 corpora. The best proposed MLP-based architectures improves WER by 1.0 / 0.9%, 0.9 / 0.5% on Librispeech dev-clean/dev-other, test-clean/test-other set, and 0.8 / 1.1% on Tedlium2 dev/test set using 86.4% the size of self-attention-based architecture.
Vocabulary Adaptation for Distant Domain Adaptation in Neural Machine Translation
Apr 30, 2020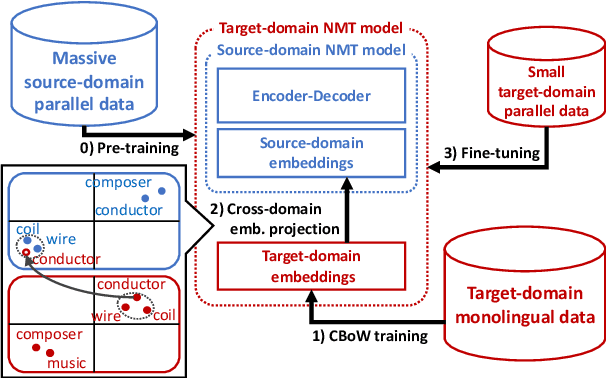
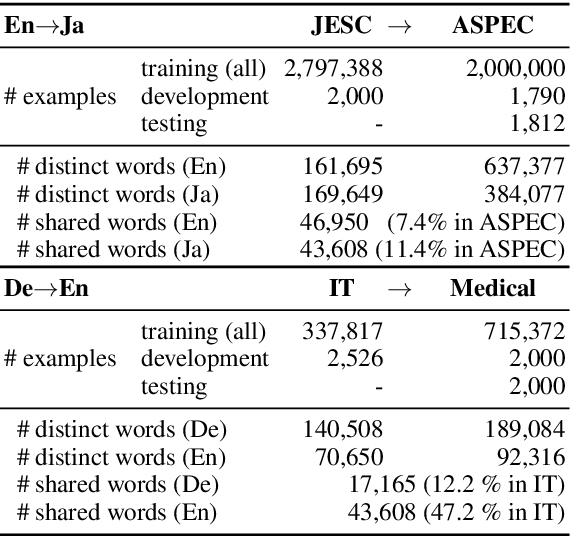
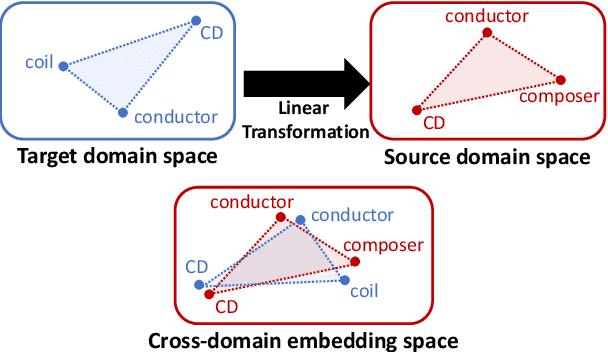

Neural machine translation (NMT) models do not work well in domains different from the training data. The standard approach to this problem is to build a small parallel data in the target domain and perform domain adaptation from a source domain where massive parallel data is available. However, domain adaptation between distant domains (e.g., subtitles and research papers) does not perform effectively because of mismatches in vocabulary; it will encounter many domain-specific unknown words (e.g., `angstrom') and words whose meanings shift across domains (e.g., `conductor'). In this study, aiming to solve these vocabulary mismatches in distant domain adaptation, we propose vocabulary adaptation, a simple method for effective fine-tuning that adapts embedding layers in a given pre-trained NMT model to the target domain. Prior to fine-tuning, our method replaces word embeddings in embedding layers of the NMT model, by projecting general word embeddings induced from monolingual data in the target domain onto the source-domain embedding space. Experimental results on distant domain adaptation for English-to-Japanese translation and German-to-English translation indicate that our vocabulary adaptation improves the performance of fine-tuning by 3.6 BLEU points.