 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022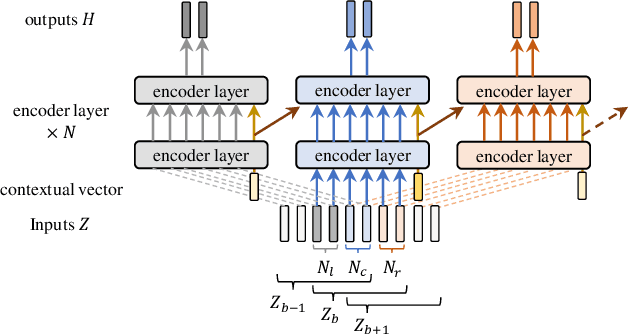
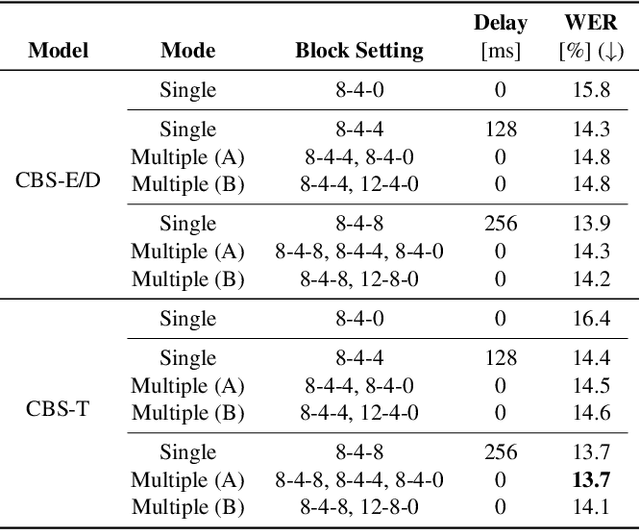
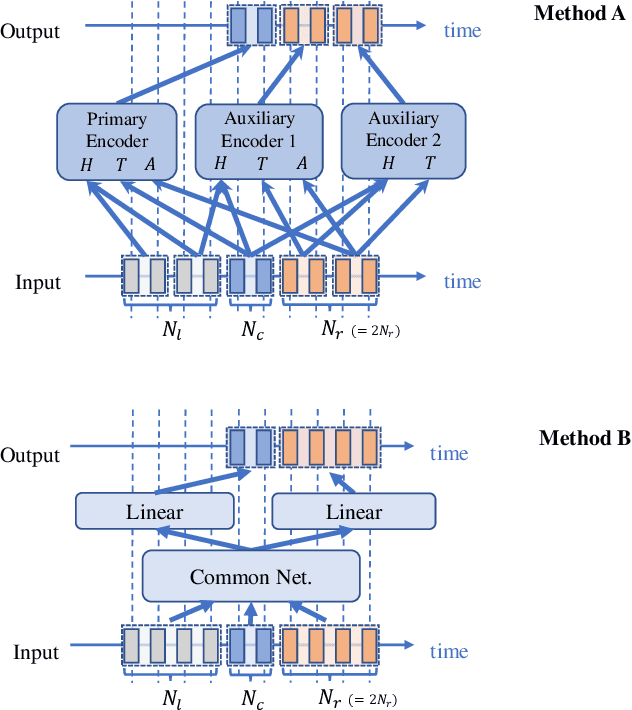
During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.