 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023



Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
Conversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022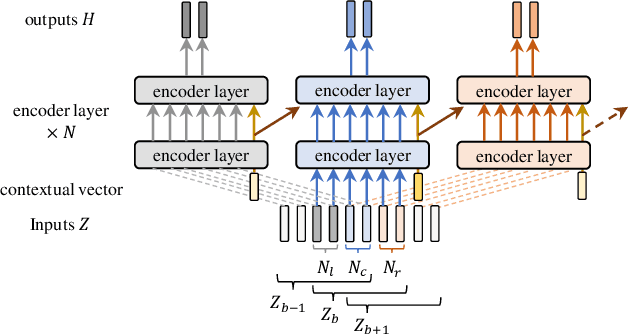
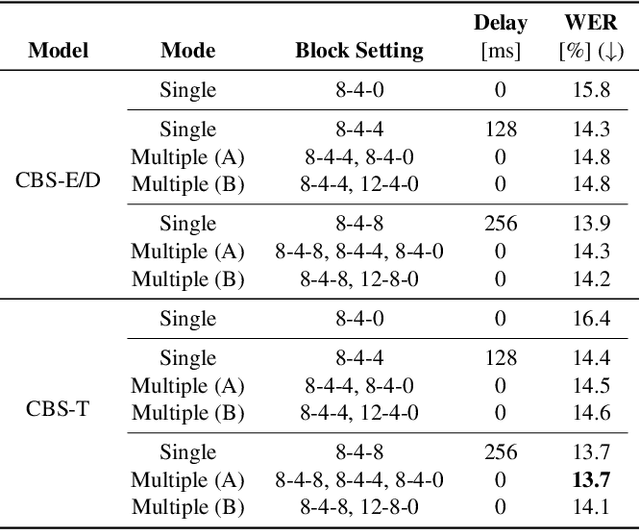
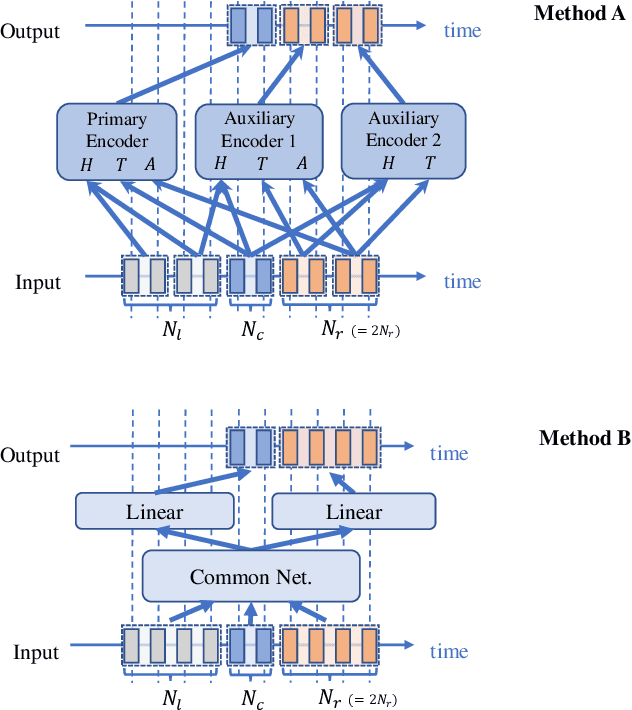
During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.
An Investigation of Enhancing CTC Model for Triggered Attention-based Streaming ASR
Oct 20, 2021

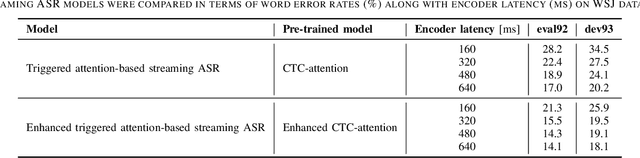
In the present paper, an attempt is made to combine Mask-CTC and the triggered attention mechanism to construct a streaming end-to-end automatic speech recognition (ASR) system that provides high performance with low latency. The triggered attention mechanism, which performs autoregressive decoding triggered by the CTC spike, has shown to be effective in streaming ASR. However, in order to maintain high accuracy of alignment estimation based on CTC outputs, which is the key to its performance, it is inevitable that decoding should be performed with some future information input (i.e., with higher latency). It should be noted that in streaming ASR, it is desirable to be able to achieve high recognition accuracy while keeping the latency low. Therefore, the present study aims to achieve highly accurate streaming ASR with low latency by introducing Mask-CTC, which is capable of learning feature representations that anticipate future information (i.e., that can consider long-term contexts), to the encoder pre-training. Experimental comparisons conducted using WSJ data demonstrate that the proposed method achieves higher accuracy with lower latency than the conventional triggered attention-based streaming ASR system.