 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Enhancing CTC Model for Triggered Attention-based Streaming ASR
Paper and Code
Oct 20, 2021

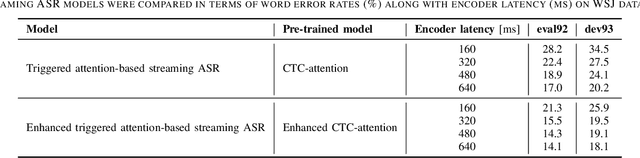
In the present paper, an attempt is made to combine Mask-CTC and the triggered attention mechanism to construct a streaming end-to-end automatic speech recognition (ASR) system that provides high performance with low latency. The triggered attention mechanism, which performs autoregressive decoding triggered by the CTC spike, has shown to be effective in streaming ASR. However, in order to maintain high accuracy of alignment estimation based on CTC outputs, which is the key to its performance, it is inevitable that decoding should be performed with some future information input (i.e., with higher latency). It should be noted that in streaming ASR, it is desirable to be able to achieve high recognition accuracy while keeping the latency low. Therefore, the present study aims to achieve highly accurate streaming ASR with low latency by introducing Mask-CTC, which is capable of learning feature representations that anticipate future information (i.e., that can consider long-term contexts), to the encoder pre-training. Experimental comparisons conducted using WSJ data demonstrate that the proposed method achieves higher accuracy with lower latency than the conventional triggered attention-based streaming ASR system.