 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocabulary Adaptation for Distant Domain Adaptation in Neural Machine Translation
Paper and Code
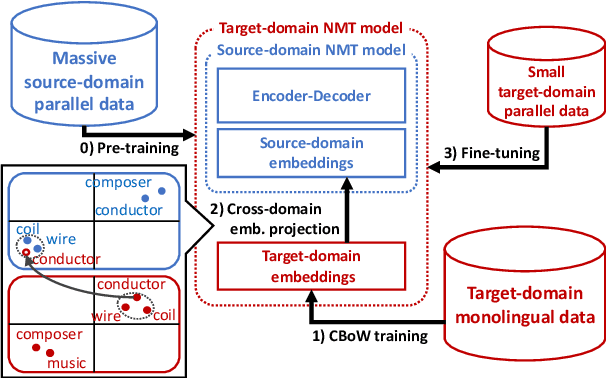
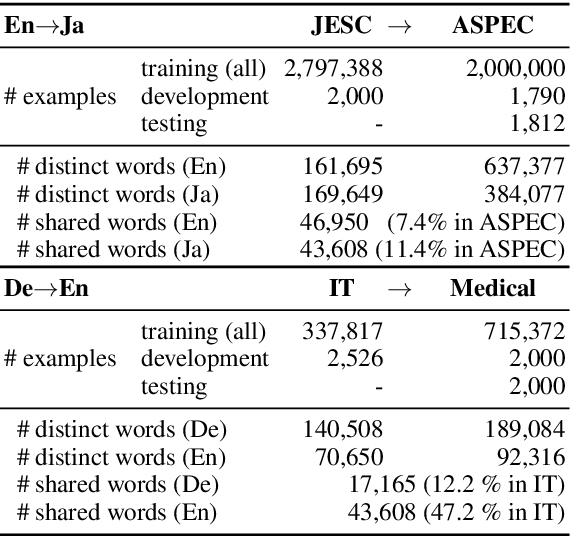
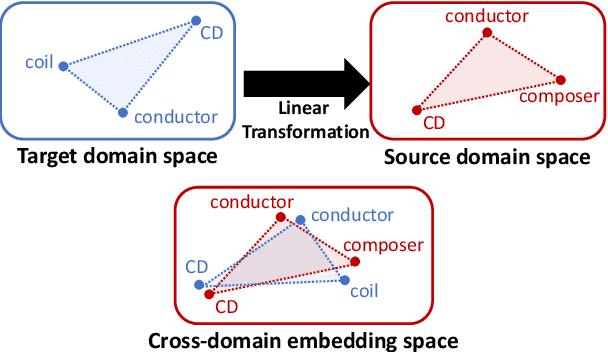

Neural machine translation (NMT) models do not work well in domains different from the training data. The standard approach to this problem is to build a small parallel data in the target domain and perform domain adaptation from a source domain where massive parallel data is available. However, domain adaptation between distant domains (e.g., subtitles and research papers) does not perform effectively because of mismatches in vocabulary; it will encounter many domain-specific unknown words (e.g., `angstrom') and words whose meanings shift across domains (e.g., `conductor'). In this study, aiming to solve these vocabulary mismatches in distant domain adaptation, we propose vocabulary adaptation, a simple method for effective fine-tuning that adapts embedding layers in a given pre-trained NMT model to the target domain. Prior to fine-tuning, our method replaces word embeddings in embedding layers of the NMT model, by projecting general word embeddings induced from monolingual data in the target domain onto the source-domain embedding space. Experimental results on distant domain adaptation for English-to-Japanese translation and German-to-English translation indicate that our vocabulary adaptation improves the performance of fine-tuning by 3.6 BLEU points.