 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Apr 07, 2023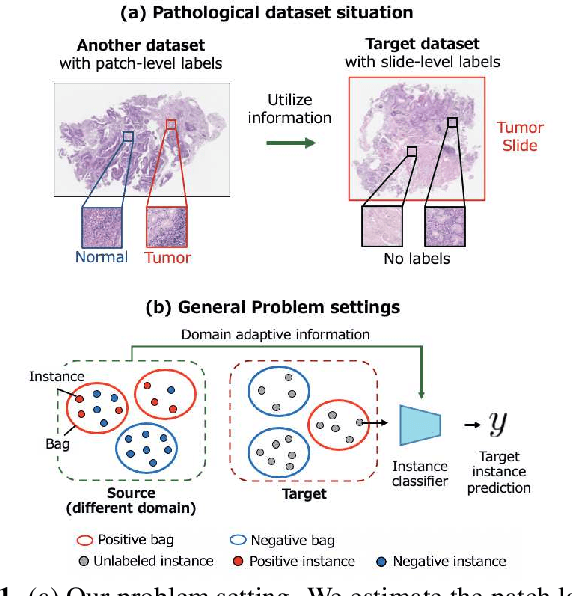
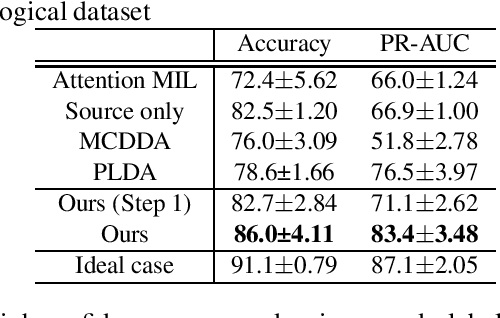
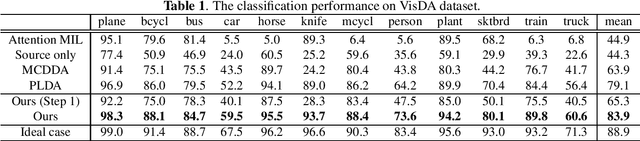
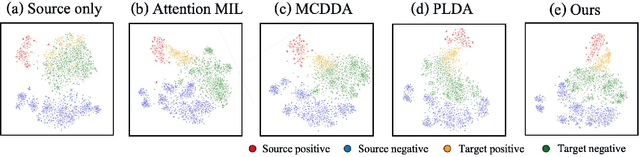
Pathological image analysis is an important process for detecting abnormalities such as cancer from cell images. However, since the image size is generally very large, the cost of providing detailed annotations is high, which makes it difficult to apply machine learning techniques. One way to improve the performance of identifying abnormalities while keeping the annotation cost low is to use only labels for each slide, or to use information from another dataset that has already been labeled. However, such weak supervisory information often does not provide sufficient performance. In this paper, we proposed a new task setting to improve the classification performance of the target dataset without increasing annotation costs. And to solve this problem, we propose a pipeline that uses multiple instance learning (MIL) and domain adaptation (DA) methods. Furthermore, in order to combine the supervisory information of both methods effectively, we propose a method to create pseudo-labels with high confidence. We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020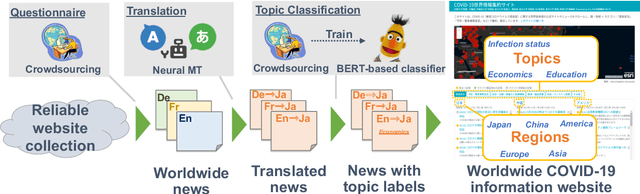

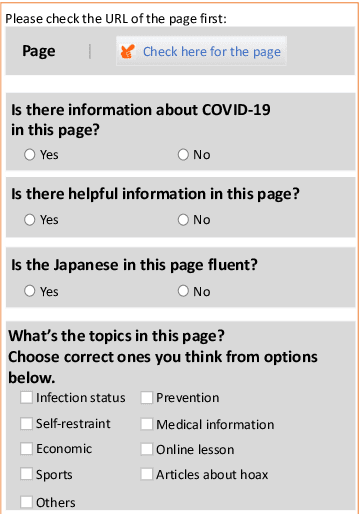
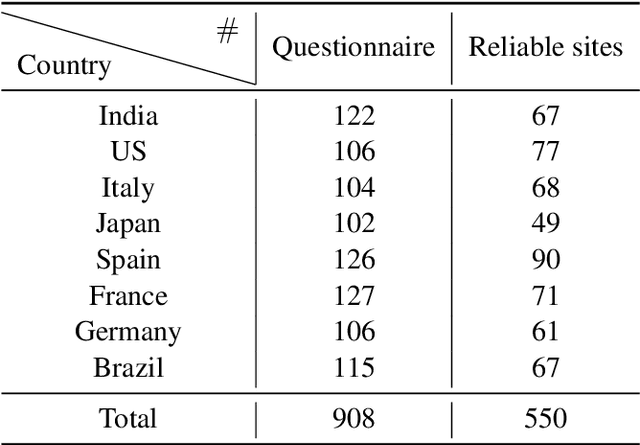
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.
Vocabulary Adaptation for Distant Domain Adaptation in Neural Machine Translation
Apr 30, 2020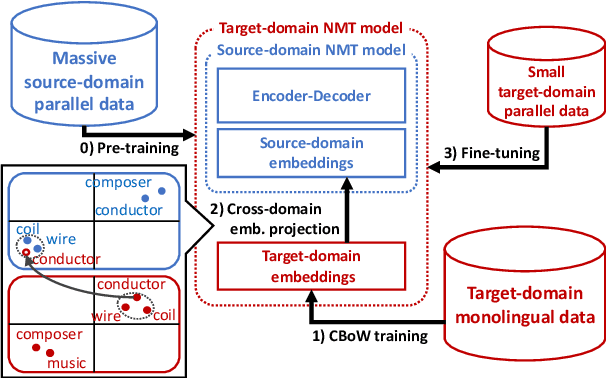
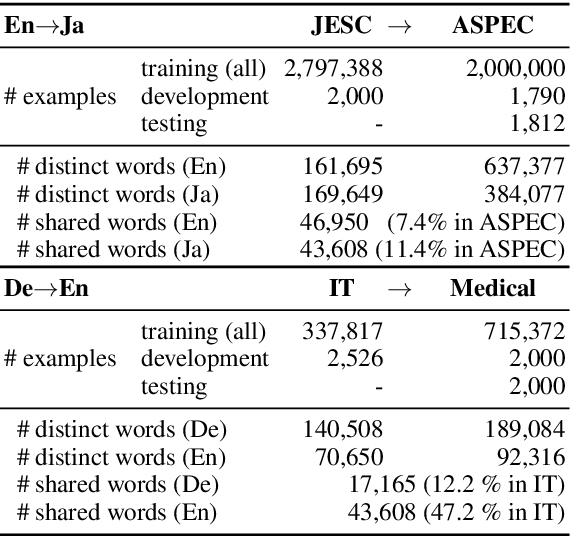
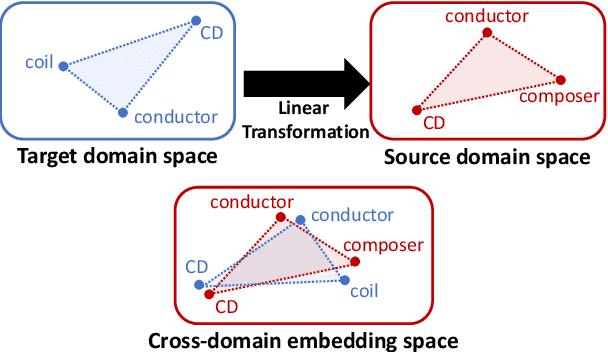

Neural machine translation (NMT) models do not work well in domains different from the training data. The standard approach to this problem is to build a small parallel data in the target domain and perform domain adaptation from a source domain where massive parallel data is available. However, domain adaptation between distant domains (e.g., subtitles and research papers) does not perform effectively because of mismatches in vocabulary; it will encounter many domain-specific unknown words (e.g., `angstrom') and words whose meanings shift across domains (e.g., `conductor'). In this study, aiming to solve these vocabulary mismatches in distant domain adaptation, we propose vocabulary adaptation, a simple method for effective fine-tuning that adapts embedding layers in a given pre-trained NMT model to the target domain. Prior to fine-tuning, our method replaces word embeddings in embedding layers of the NMT model, by projecting general word embeddings induced from monolingual data in the target domain onto the source-domain embedding space. Experimental results on distant domain adaptation for English-to-Japanese translation and German-to-English translation indicate that our vocabulary adaptation improves the performance of fine-tuning by 3.6 BLEU points.
Learning to Describe Phrases with Local and Global Contexts
Nov 01, 2018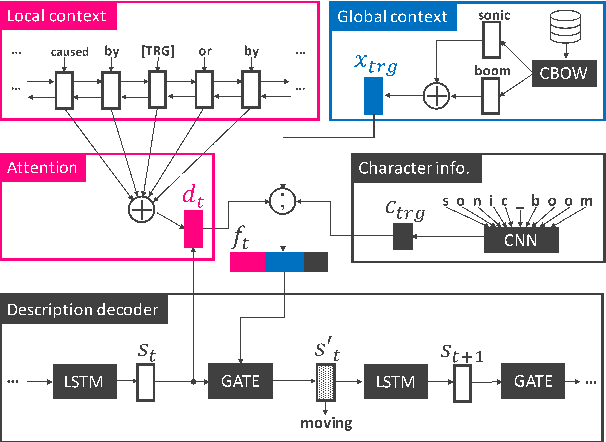
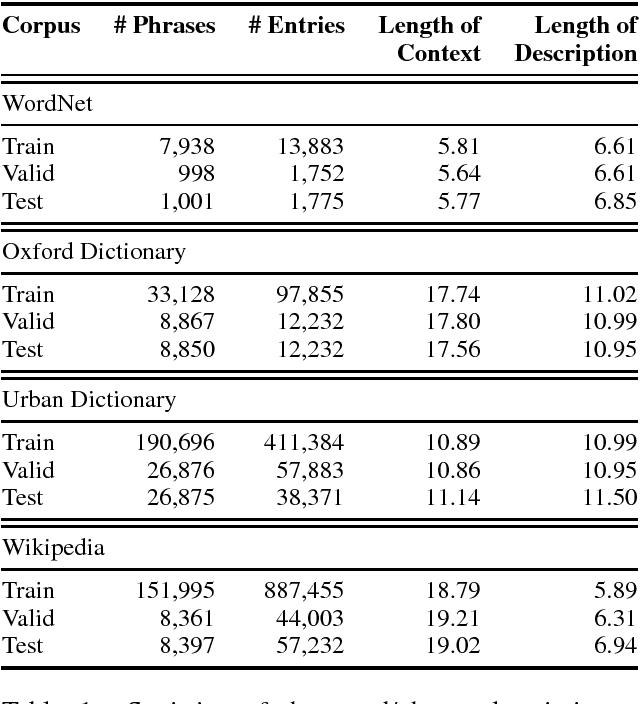

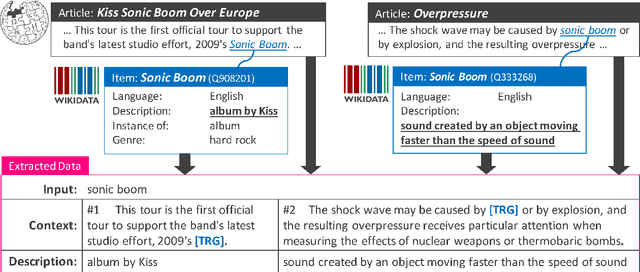
When reading a text, it is common to become stuck on unfamiliar words and phrases, such as polysemous words with novel senses, rarely used idioms, Internet slang, or emerging entities. At first, we attempt to figure out the meaning of those expressions from their context, and ultimately we may consult a dictionary for their definitions. However, rarely-used senses or emerging entities are not always covered by the hand-crafted definitions in existing dictionaries, which can cause problems in text comprehension. This paper undertakes a task of describing (or defining) a given expression (word or phrase) based on its usage contexts, and presents a novel neural-network generator for expressing its meaning as a natural language description. Experimental results on four datasets (including WordNet, Oxford and Urban Dictionaries, non-standard English, and Wikipedia) demonstrate the effectiveness of our method over previous methods for definition generation[Noraset+17; Gadetsky+18; Ni+17].