 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-Language Models
Apr 02, 2026Developing vision-language models (VLMs) that generalize across diverse tasks requires large-scale training datasets with diverse content. In English, such datasets are typically constructed by aggregating and curating numerous existing visual question answering (VQA) resources. However, this strategy does not readily extend to other languages, where VQA datasets remain limited in both scale and domain coverage, posing a major obstacle to building high-quality multilingual and non-English VLMs. In this work, we introduce Jagle, the largest Japanese multimodal post-training dataset to date, comprising approximately 9.2 million instances across diverse tasks. Rather than relying on existing VQA datasets, we collect heterogeneous source data, including images, image-text pairs, and PDF documents, and generate VQA pairs through multiple strategies such as VLM-based QA generation, translation, and text rendering. Experiments demonstrate that a 2.2B model trained with Jagle achieves strong performance on Japanese tasks, surpassing InternVL3.5-2B in average score across ten Japanese evaluation tasks and approaching within five points of Qwen3-VL-2B-Instruct. Furthermore, combining Jagle with FineVision does not degrade English performance; instead, it improves English performance compared to training with FineVision alone. To facilitate reproducibility and future research, we release the dataset, trained models, and code.
JAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation
Apr 01, 2026Reliable evaluation is essential for the development of vision-language models (VLMs). However, Japanese VQA benchmarks have undergone far less iterative refinement than their English counterparts. As a result, many existing benchmarks contain issues such as ambiguous questions, incorrect answers, and instances that can be solved without visual grounding, undermining evaluation reliability and leading to misleading conclusions in model comparisons. To address these limitations, we introduce JAMMEval, a refined collection of Japanese benchmarks for reliable VLM evaluation. It is constructed by systematically refining seven existing Japanese benchmark datasets through two rounds of human annotation, improving both data quality and evaluation reliability. In our experiments, we evaluate open-weight and proprietary VLMs on JAMMEval and analyze the capabilities of recent models on Japanese VQA. We further demonstrate the effectiveness of our refinement by showing that the resulting benchmarks yield evaluation scores that better reflect model capability, exhibit lower run-to-run variance, and improve the ability to distinguish between models of different capability levels. We release our dataset and code to advance reliable evaluation of VLMs.
ShapleyLaw: A Game-Theoretic Approach to Multilingual Scaling Laws
Mar 18, 2026In multilingual pretraining, the test loss of a pretrained model is heavily influenced by the proportion of each language in the pretraining data, namely the \textit{language mixture ratios}. Multilingual scaling laws can predict the test loss under different language mixture ratios and can therefore be used to estimate the optimal ratios. However, the current approaches to multilingual scaling laws do not measure the \textit{cross-lingual transfer} effect, resulting in suboptimal mixture ratios. In this paper, we consider multilingual pretraining as a cooperative game in which each language acts as a player that jointly contributes to pretraining, gaining the resulting reduction in test loss as the payoff. Consequently, from the perspective of cooperative game theory, we quantify the cross-lingual transfer from each language by its contribution in the game, and propose a game-theoretic multilingual scaling law called \textit{ShapleyLaw}. Our experiments show that ShapleyLaw outperforms baseline methods in model performance prediction and language mixture optimization.
Traveling Across Languages: Benchmarking Cross-Lingual Consistency in Multimodal LLMs
May 21, 2025



The rapid evolution of multimodal large language models (MLLMs) has significantly enhanced their real-world applications. However, achieving consistent performance across languages, especially when integrating cultural knowledge, remains a significant challenge. To better assess this issue, we introduce two new benchmarks: KnowRecall and VisRecall, which evaluate cross-lingual consistency in MLLMs. KnowRecall is a visual question answering benchmark designed to measure factual knowledge consistency in 15 languages, focusing on cultural and historical questions about global landmarks. VisRecall assesses visual memory consistency by asking models to describe landmark appearances in 9 languages without access to images. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, still struggle to achieve cross-lingual consistency. This underscores the need for more robust approaches that produce truly multilingual and culturally aware models.
Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Oct 30, 2024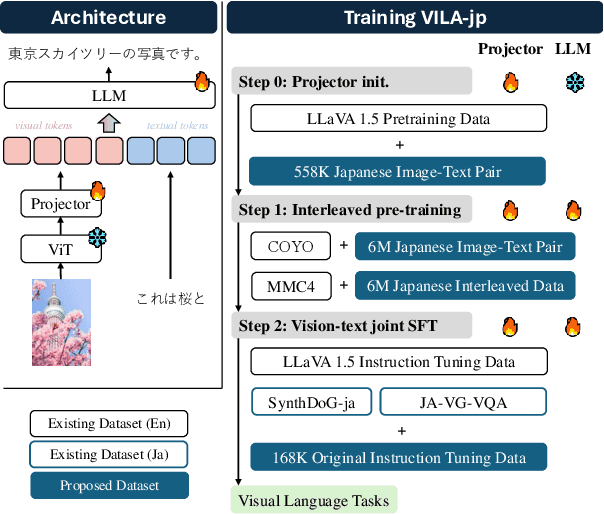
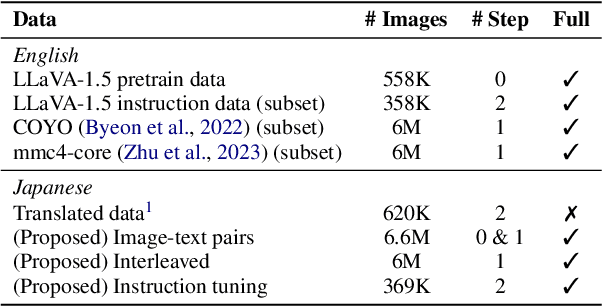
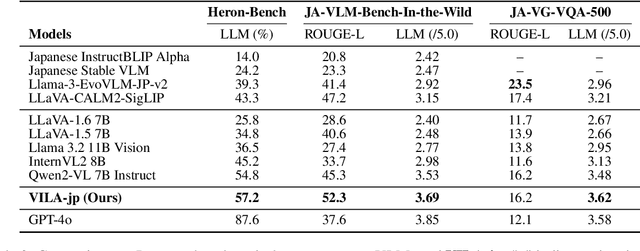

To develop high-performing Visual Language Models (VLMs), it is essential to prepare multimodal resources, such as image-text pairs, interleaved data, and instruction data. While multimodal resources for English are abundant, there is a significant lack of corresponding resources for non-English languages, such as Japanese. To address this problem, we take Japanese as a non-English language and propose a method for rapidly creating Japanese multimodal datasets from scratch. We collect Japanese image-text pairs and interleaved data from web archives and generate Japanese instruction data directly from images using an existing VLM. Our experimental results show that a VLM trained on these native datasets outperforms those relying on machine-translated content.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Reinforcement Learning for Edit-Based Non-Autoregressive Neural Machine Translation
May 02, 2024



Non-autoregressive (NAR) language models are known for their low latency in neural machine translation (NMT). However, a performance gap exists between NAR and autoregressive models due to the large decoding space and difficulty in capturing dependency between target words accurately. Compounding this, preparing appropriate training data for NAR models is a non-trivial task, often exacerbating exposure bias. To address these challenges, we apply reinforcement learning (RL) to Levenshtein Transformer, a representative edit-based NAR model, demonstrating that RL with self-generated data can enhance the performance of edit-based NAR models. We explore two RL approaches: stepwise reward maximization and episodic reward maximization. We discuss the respective pros and cons of these two approaches and empirically verify them. Moreover, we experimentally investigate the impact of temperature setting on performance, confirming the importance of proper temperature setting for NAR models' training.
Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
Feb 22, 2024



We investigate the impact of politeness levels in prompts on the performance of large language models (LLMs). Polite language in human communications often garners more compliance and effectiveness, while rudeness can cause aversion, impacting response quality. We consider that LLMs mirror human communication traits, suggesting they align with human cultural norms. We assess the impact of politeness in prompts on LLMs across English, Chinese, and Japanese tasks. We observed that impolite prompts often result in poor performance, but overly polite language does not guarantee better outcomes. The best politeness level is different according to the language. This phenomenon suggests that LLMs not only reflect human behavior but are also influenced by language, particularly in different cultural contexts. Our findings highlight the need to factor in politeness for cross-cultural natural language processing and LLM usage.
SlideAVSR: A Dataset of Paper Explanation Videos for Audio-Visual Speech Recognition
Jan 18, 2024



Audio-visual speech recognition (AVSR) is a multimodal extension of automatic speech recognition (ASR), using video as a complement to audio. In AVSR, considerable efforts have been directed at datasets for facial features such as lip-readings, while they often fall short in evaluating the image comprehension capabilities in broader contexts. In this paper, we construct SlideAVSR, an AVSR dataset using scientific paper explanation videos. SlideAVSR provides a new benchmark where models transcribe speech utterances with texts on the slides on the presentation recordings. As technical terminologies that are frequent in paper explanations are notoriously challenging to transcribe without reference texts, our SlideAVSR dataset spotlights a new aspect of AVSR problems. As a simple yet effective baseline, we propose DocWhisper, an AVSR model that can refer to textual information from slides, and confirm its effectiveness on SlideAVSR.
Exploring Automatic Evaluation Methods based on a Decoder-based LLM for Text Generation
Oct 17, 2023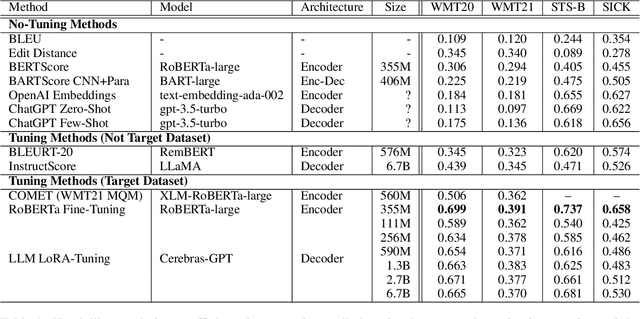
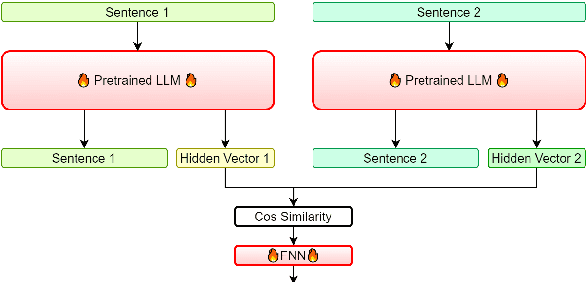

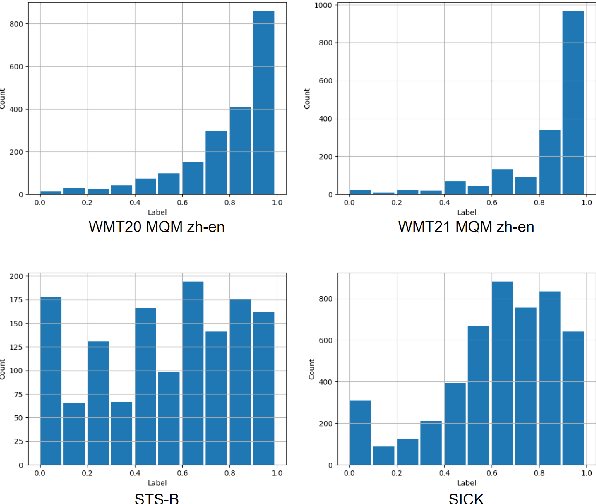
Automatic evaluation of text generation is essential for improving the accuracy of generation tasks. In light of the current trend towards increasingly larger decoder-based language models, we investigate automatic evaluation methods based on such models for text generation. This paper compares various methods, including tuning with encoder-based models and large language models under equal conditions, on two different tasks, machine translation evaluation and semantic textual similarity, in two languages, Japanese and English. Experimental results show that compared to the tuned encoder-based models, the tuned decoder-based models perform poorly. The analysis of the causes for this suggests that the decoder-based models focus on surface word sequences and do not capture meaning. It is also revealed that in-context learning of very large decoder-based models such as ChatGPT makes it difficult to identify fine-grained semantic differences.