 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-Mimi: Speech Language Models with Interleaved Semantic and Acoustic Tokens
Sep 18, 2025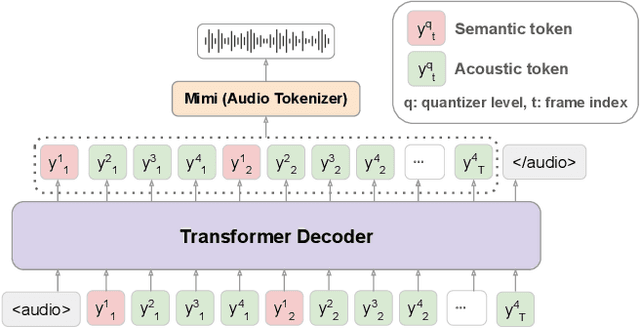
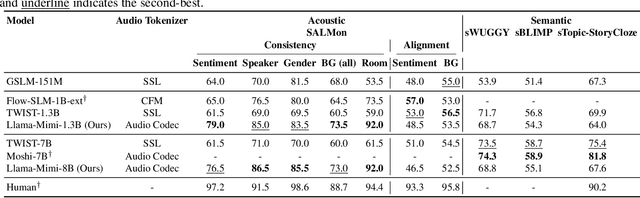

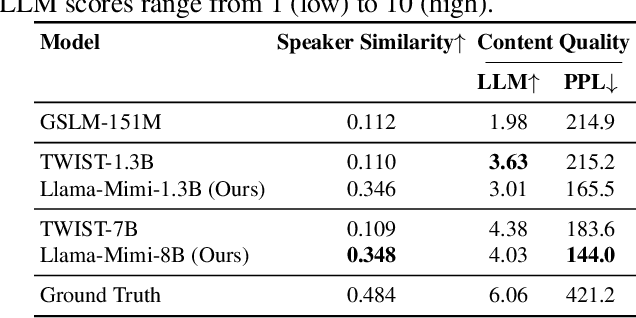
We propose Llama-Mimi, a speech language model that uses a unified tokenizer and a single Transformer decoder to jointly model sequences of interleaved semantic and acoustic tokens. Comprehensive evaluation shows that Llama-Mimi achieves state-of-the-art performance in acoustic consistency and possesses the ability to preserve speaker identity. Our analysis further demonstrates that increasing the number of quantizers improves acoustic fidelity but degrades linguistic performance, highlighting the inherent challenge of maintaining long-term coherence. We additionally introduce an LLM-as-a-Judge-based evaluation to assess the spoken content quality of generated outputs. Our models, code, and speech samples are publicly available.
EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements
Jun 10, 2025



Financial analysis presents complex challenges that could leverage large language model (LLM) capabilities. However, the scarcity of challenging financial datasets, particularly for Japanese financial data, impedes academic innovation in financial analytics. As LLMs advance, this lack of accessible research resources increasingly hinders their development and evaluation in this specialized domain. To address this gap, we introduce EDINET-Bench, an open-source Japanese financial benchmark designed to evaluate the performance of LLMs on challenging financial tasks including accounting fraud detection, earnings forecasting, and industry prediction. EDINET-Bench is constructed by downloading annual reports from the past 10 years from Japan's Electronic Disclosure for Investors' NETwork (EDINET) and automatically assigning labels corresponding to each evaluation task. Our experiments reveal that even state-of-the-art LLMs struggle, performing only slightly better than logistic regression in binary classification for fraud detection and earnings forecasting. These results highlight significant challenges in applying LLMs to real-world financial applications and underscore the need for domain-specific adaptation. Our dataset, benchmark construction code, and evaluation code is publicly available to facilitate future research in finance with LLMs.
llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length
Apr 22, 2025Encoder-only transformer models like BERT are widely adopted as a pre-trained backbone for tasks like sentence classification and retrieval. However, pretraining of encoder models with large-scale corpora and long contexts has been relatively underexplored compared to decoder-only transformers. In this work, we present llm-jp-modernbert, a ModernBERT model trained on a publicly available, massive Japanese corpus with a context length of 8192 tokens. While our model does not surpass existing baselines on downstream tasks, it achieves good results on fill-mask test evaluations. We also analyze the effect of context length expansion through pseudo-perplexity experiments. Furthermore, we investigate sentence embeddings in detail, analyzing their transitions during training and comparing them with those from other existing models, confirming similar trends with models sharing the same architecture. To support reproducibility and foster the development of long-context BERT, we release our model, along with the training and evaluation code.
Constructing Multimodal Datasets from Scratch for Rapid Development of a Japanese Visual Language Model
Oct 30, 2024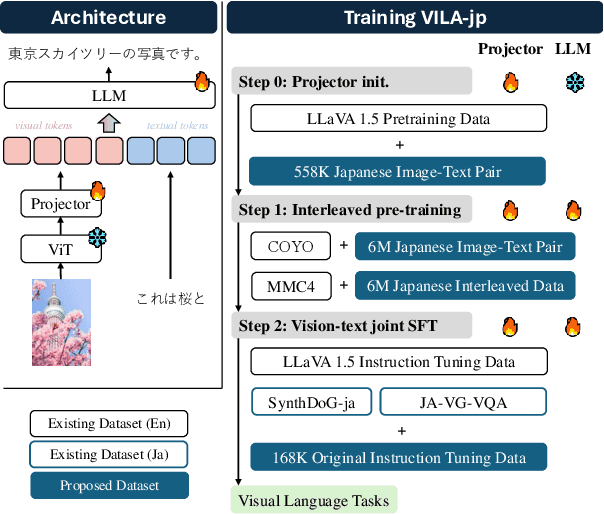
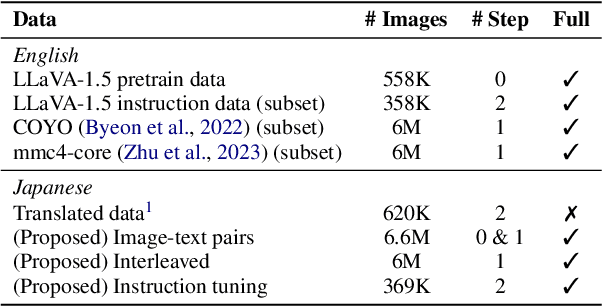
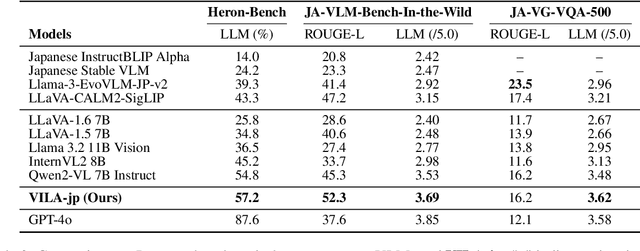

To develop high-performing Visual Language Models (VLMs), it is essential to prepare multimodal resources, such as image-text pairs, interleaved data, and instruction data. While multimodal resources for English are abundant, there is a significant lack of corresponding resources for non-English languages, such as Japanese. To address this problem, we take Japanese as a non-English language and propose a method for rapidly creating Japanese multimodal datasets from scratch. We collect Japanese image-text pairs and interleaved data from web archives and generate Japanese instruction data directly from images using an existing VLM. Our experimental results show that a VLM trained on these native datasets outperforms those relying on machine-translated content.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.