 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapleyLaw: A Game-Theoretic Approach to Multilingual Scaling Laws
Mar 18, 2026In multilingual pretraining, the test loss of a pretrained model is heavily influenced by the proportion of each language in the pretraining data, namely the \textit{language mixture ratios}. Multilingual scaling laws can predict the test loss under different language mixture ratios and can therefore be used to estimate the optimal ratios. However, the current approaches to multilingual scaling laws do not measure the \textit{cross-lingual transfer} effect, resulting in suboptimal mixture ratios. In this paper, we consider multilingual pretraining as a cooperative game in which each language acts as a player that jointly contributes to pretraining, gaining the resulting reduction in test loss as the payoff. Consequently, from the perspective of cooperative game theory, we quantify the cross-lingual transfer from each language by its contribution in the game, and propose a game-theoretic multilingual scaling law called \textit{ShapleyLaw}. Our experiments show that ShapleyLaw outperforms baseline methods in model performance prediction and language mixture optimization.
ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding
Feb 18, 2026While multimodal large language models (MLLMs) have shown remarkable success across a wide range of tasks, long-form video understanding remains a significant challenge. In this study, we focus on video understanding by MLLMs. This task is challenging because processing a full stream of RGB frames is computationally intractable and highly redundant, as self-attention have quadratic complexity with sequence length. In this paper, we propose ReMoRa, a video MLLM that processes videos by operating directly on their compressed representations. A sparse set of RGB keyframes is retained for appearance, while temporal dynamics are encoded as a motion representation, removing the need for sequential RGB frames. These motion representations act as a compact proxy for optical flow, capturing temporal dynamics without full frame decoding. To refine the noise and low fidelity of block-based motions, we introduce a module to denoise and generate a fine-grained motion representation. Furthermore, our model compresses these features in a way that scales linearly with sequence length. We demonstrate the effectiveness of ReMoRa through extensive experiments across a comprehensive suite of long-video understanding benchmarks. ReMoRa outperformed baseline methods on multiple challenging benchmarks, including LongVideoBench, NExT-QA, and MLVU.
Instability in Downstream Task Performance During LLM Pretraining
Oct 06, 2025When training large language models (LLMs), it is common practice to track downstream task performance throughout the training process and select the checkpoint with the highest validation score. However, downstream metrics often exhibit substantial fluctuations, making it difficult to identify the checkpoint that truly represents the best-performing model. In this study, we empirically analyze the stability of downstream task performance in an LLM trained on diverse web-scale corpora. We find that task scores frequently fluctuate throughout training, both at the aggregate and example levels. To address this instability, we investigate two post-hoc checkpoint integration methods: checkpoint averaging and ensemble, motivated by the hypothesis that aggregating neighboring checkpoints can reduce performance volatility. We demonstrate both empirically and theoretically that these methods improve downstream performance stability without requiring any changes to the training procedure.
Llama-Mimi: Speech Language Models with Interleaved Semantic and Acoustic Tokens
Sep 18, 2025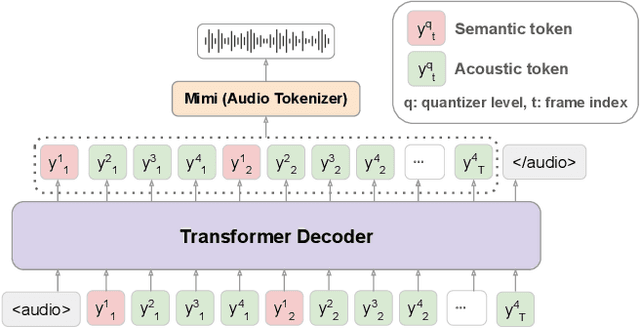
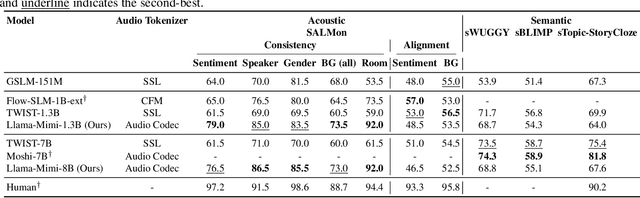

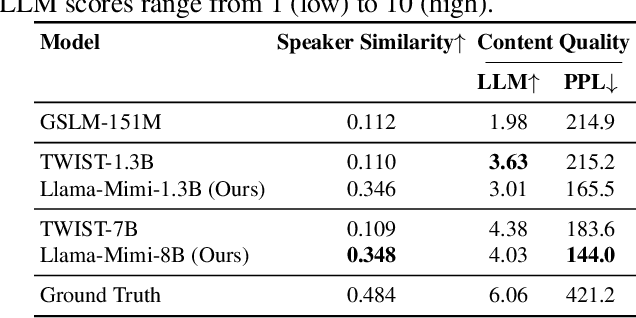
We propose Llama-Mimi, a speech language model that uses a unified tokenizer and a single Transformer decoder to jointly model sequences of interleaved semantic and acoustic tokens. Comprehensive evaluation shows that Llama-Mimi achieves state-of-the-art performance in acoustic consistency and possesses the ability to preserve speaker identity. Our analysis further demonstrates that increasing the number of quantizers improves acoustic fidelity but degrades linguistic performance, highlighting the inherent challenge of maintaining long-term coherence. We additionally introduce an LLM-as-a-Judge-based evaluation to assess the spoken content quality of generated outputs. Our models, code, and speech samples are publicly available.
Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality
Jun 17, 2025Supervised fine-tuning (SFT) is a critical step in aligning large language models (LLMs) with human instructions and values, yet many aspects of SFT remain poorly understood. We trained a wide range of base models on a variety of datasets including code generation, mathematical reasoning, and general-domain tasks, resulting in 1,000+ SFT models under controlled conditions. We then identified the dataset properties that matter most and examined the layer-wise modifications introduced by SFT. Our findings reveal that some training-task synergies persist across all models while others vary substantially, emphasizing the importance of model-specific strategies. Moreover, we demonstrate that perplexity consistently predicts SFT effectiveness--often surpassing superficial similarity between trained data and benchmark--and that mid-layer weight changes correlate most strongly with performance gains. We will release these 1,000+ SFT models and benchmark results to accelerate further research.
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
llm-jp-modernbert: A ModernBERT Model Trained on a Large-Scale Japanese Corpus with Long Context Length
Apr 22, 2025Encoder-only transformer models like BERT are widely adopted as a pre-trained backbone for tasks like sentence classification and retrieval. However, pretraining of encoder models with large-scale corpora and long contexts has been relatively underexplored compared to decoder-only transformers. In this work, we present llm-jp-modernbert, a ModernBERT model trained on a publicly available, massive Japanese corpus with a context length of 8192 tokens. While our model does not surpass existing baselines on downstream tasks, it achieves good results on fill-mask test evaluations. We also analyze the effect of context length expansion through pseudo-perplexity experiments. Furthermore, we investigate sentence embeddings in detail, analyzing their transitions during training and comparing them with those from other existing models, confirming similar trends with models sharing the same architecture. To support reproducibility and foster the development of long-context BERT, we release our model, along with the training and evaluation code.
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization
Feb 26, 2025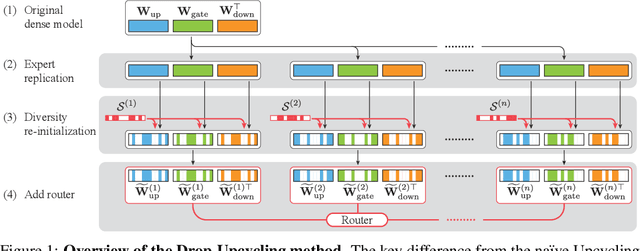
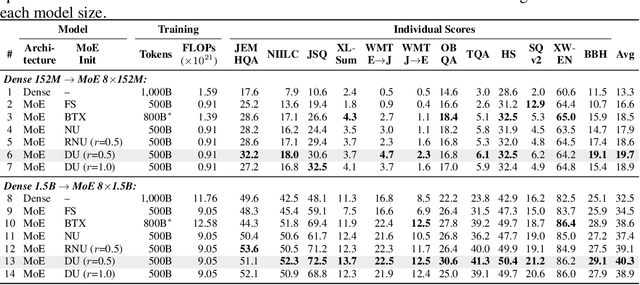
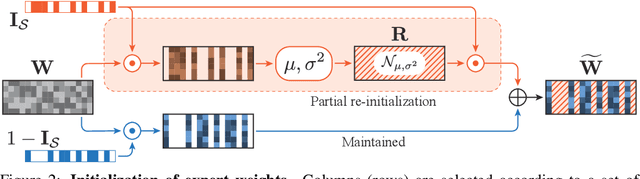
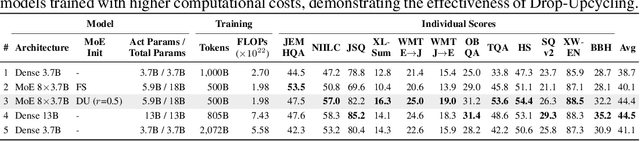
The Mixture of Experts (MoE) architecture reduces the training and inference cost significantly compared to a dense model of equivalent capacity. Upcycling is an approach that initializes and trains an MoE model using a pre-trained dense model. While upcycling leads to initial performance gains, the training progresses slower than when trained from scratch, leading to suboptimal performance in the long term. We propose Drop-Upcycling - a method that effectively addresses this problem. Drop-Upcycling combines two seemingly contradictory approaches: utilizing the knowledge of pre-trained dense models while statistically re-initializing some parts of the weights. This approach strategically promotes expert specialization, significantly enhancing the MoE model's efficiency in knowledge acquisition. Extensive large-scale experiments demonstrate that Drop-Upcycling significantly outperforms previous MoE construction methods in the long term, specifically when training on hundreds of billions of tokens or more. As a result, our MoE model with 5.9B active parameters achieves comparable performance to a 13B dense model in the same model family, while requiring approximately 1/4 of the training FLOPs. All experimental resources, including source code, training data, model checkpoints and logs, are publicly available to promote reproducibility and future research on MoE.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Vaporetto: Efficient Japanese Tokenization Based on Improved Pointwise Linear Classification
Jun 24, 2024This paper proposes an approach to improve the runtime efficiency of Japanese tokenization based on the pointwise linear classification (PLC) framework, which formulates the whole tokenization process as a sequence of linear classification problems. Our approach optimizes tokenization by leveraging the characteristics of the PLC framework and the task definition. Our approach involves (1) composing multiple classifications into array-based operations, (2) efficient feature lookup with memory-optimized automata, and (3) three orthogonal pre-processing methods for reducing actual score calculation. Thus, our approach makes the tokenization speed 5.7 times faster than the current approach based on the same model without decreasing tokenization accuracy. Our implementation is available at https://github.com/daac-tools/vaporetto under the MIT or Apache-2.0 license.