 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaporetto: Efficient Japanese Tokenization Based on Improved Pointwise Linear Classification
Jun 24, 2024This paper proposes an approach to improve the runtime efficiency of Japanese tokenization based on the pointwise linear classification (PLC) framework, which formulates the whole tokenization process as a sequence of linear classification problems. Our approach optimizes tokenization by leveraging the characteristics of the PLC framework and the task definition. Our approach involves (1) composing multiple classifications into array-based operations, (2) efficient feature lookup with memory-optimized automata, and (3) three orthogonal pre-processing methods for reducing actual score calculation. Thus, our approach makes the tokenization speed 5.7 times faster than the current approach based on the same model without decreasing tokenization accuracy. Our implementation is available at https://github.com/daac-tools/vaporetto under the MIT or Apache-2.0 license.
Succinct Trit-array Trie for Scalable Trajectory Similarity Search
May 21, 2020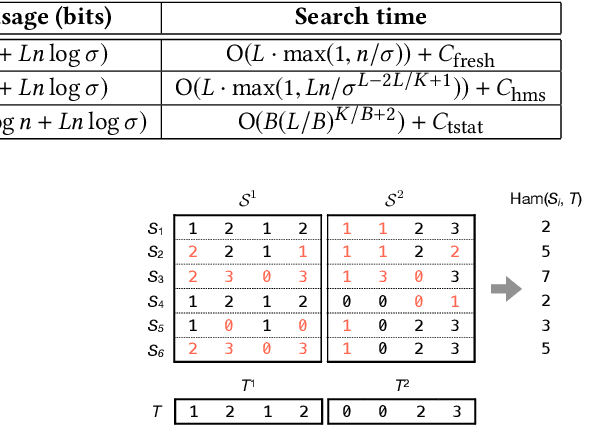

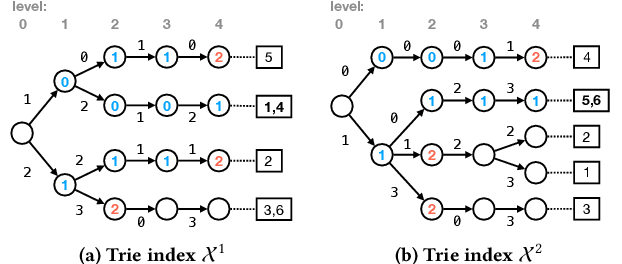
Massive datasets of spatial trajectories representing the mobility of a diversity of moving objects are ubiquitous in research and industry. Similarity search of a large collection of trajectories is indispensable for turning these datasets into knowledge. Current methods for similarity search of trajectories are inefficient in terms of search time and memory when applied to massive datasets. In this paper, we address this problem by presenting a scalable similarity search for Fr\'echet distance on trajectories, which we call trajectory-indexing succinct trit-array trie (tSTAT). tSTAT achieves time and memory efficiency by leveraging locality sensitive hashing (LSH) for Fr\'echet distance and a trie data structure. We also present two novel techniques of node reduction and a space-efficient representation for tries, which enable to dramatically enhance a memory efficiency of tries. We experimentally test tSTAT on its ability to retrieve similar trajectories for a query from large collections of trajectories and show that tSTAT performs superiorly with respect to search time and memory efficiency.
$b$-Bit Sketch Trie: Scalable Similarity Search on Integer Sketches
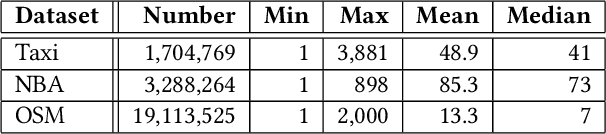
Oct 18, 2019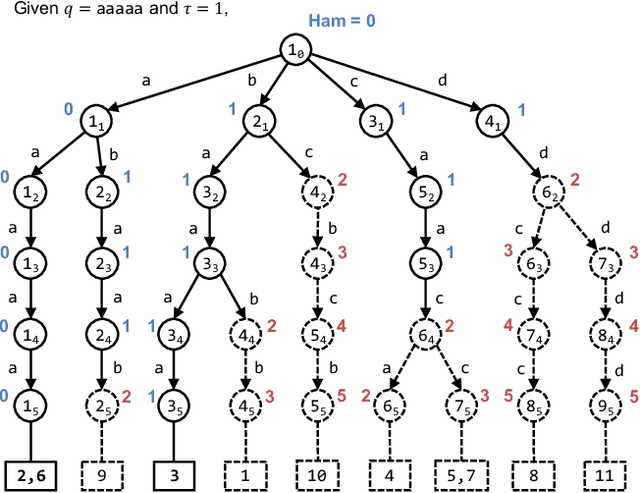
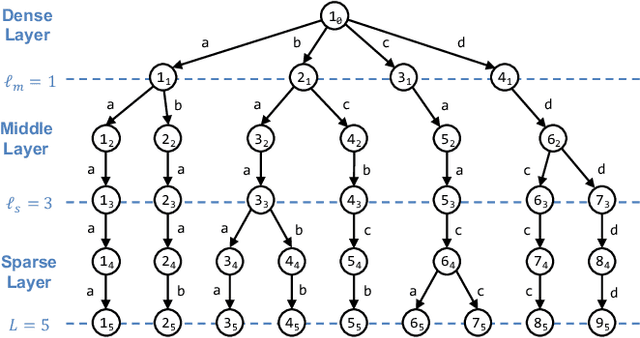

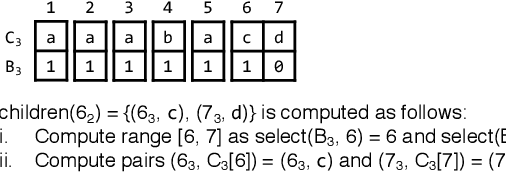
Recently, randomly mapping vectorial data to strings of discrete symbols (i.e., sketches) for fast and space-efficient similarity searches has become popular. Such random mapping is called similarity-preserving hashing and approximates a similarity metric by using the Hamming distance. Although many efficient similarity searches have been proposed, most of them are designed for binary sketches. Similarity searches on integer sketches are in their infancy. In this paper, we present a novel space-efficient trie named $b$-bit sketch trie on integer sketches for scalable similarity searches by leveraging the idea behind succinct data structures (i.e., space-efficient data structures while supporting various data operations in the compressed format) and a favorable property of integer sketches as fixed-length strings. Our experimental results obtained using real-world datasets show that a trie-based index is built from integer sketches and efficiently performs similarity searches on the index by pruning useless portions of the search space, which greatly improves the search time and space-efficiency of the similarity search. The experimental results show that our similarity search is at most one order of magnitude faster than state-of-the-art similarity searches. Besides, our method needs only 10 GiB of memory on a billion-scale database, while state-of-the-art similarity searches need 29 GiB of memory.