 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Outlier Prediction Through Outlier Score Modeling
Mar 22, 2026This study addresses an important gap in time series outlier detection by proposing a novel problem setting: long-term outlier prediction. Conventional methods primarily focus on immediate detection by identifying deviations from normal patterns. As a result, their applicability is limited when forecasting outlier events far into the future. To overcome this limitation, we propose a simple and unsupervised two-layer method that is independent of specific models. The first layer performs standard outlier detection, and the second layer predicts future outlier scores based on the temporal structure of previously observed outliers. This framework enables not only pointwise detection but also long-term forecasting of outlier likelihoods. Experiments on synthetic datasets show that the proposed method performs well in both detection and prediction tasks. These findings suggest that the method can serve as a strong baseline for future work in outlier detection and forecasting.
Evaluating Cross-Modal Reasoning Ability and Problem Characteristics with Multimodal Item Response Theory
Mar 03, 2026Multimodal Large Language Models (MLLMs) have recently emerged as general architectures capable of reasoning over diverse modalities. Benchmarks for MLLMs should measure their ability for cross-modal integration. However, current benchmarks are filled with shortcut questions, which can be solved using only a single modality, thereby yielding unreliable rankings. For example, in vision-language cases, we can find the correct answer without either the image or the text. These low-quality questions unnecessarily increase the size and computational requirements of benchmarks. We introduce a multi-modal and multidimensional item response theory framework (M3IRT) that extends classical IRT by decomposing both model ability and item difficulty into image-only, text-only, and cross-modal components. M3IRT estimates cross-modal ability of MLLMs and each question's cross-modal difficulty, enabling compact, high-quality subsets that better reflect multimodal reasoning. Across 24 VLMs on three benchmarks, M3IRT prioritizes genuinely cross-modal questions over shortcuts and preserves ranking fidelity even when 50% of items are artificially generated low-quality questions, thereby reducing evaluation cost while improving reliability. M3IRT thus offers a practical tool for assessing cross-modal reasoning and refining multimodal benchmarks.
Adaptive Quality-Diversity Trade-offs for Large-Scale Batch Recommendation
Feb 02, 2026A core research question in recommender systems is to propose batches of highly relevant and diverse items, that is, items personalized to the user's preferences, but which also might get the user out of their comfort zone. This diversity might induce properties of serendipidity and novelty which might increase user engagement or revenue. However, many real-life problems arise in that case: e.g., avoiding to recommend distinct but too similar items to reduce the churn risk, and computational cost for large item libraries, up to millions of items. First, we consider the case when the user feedback model is perfectly observed and known in advance, and introduce an efficient algorithm called B-DivRec combining determinantal point processes and a fuzzy denuding procedure to adjust the degree of item diversity. This helps enforcing a quality-diversity trade-off throughout the user history. Second, we propose an approach to adaptively tailor the quality-diversity trade-off to the user, so that diversity in recommendations can be enhanced if it leads to positive feedback, and vice-versa. Finally, we illustrate the performance and versatility of B-DivRec in the two settings on synthetic and real-life data sets on movie recommendation and drug repurposing.
Dynamic Feature Selection from Variable Feature Sets Using Features of Features
Mar 12, 2025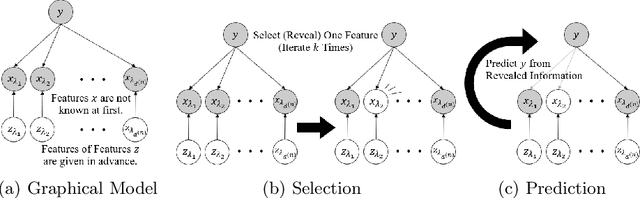
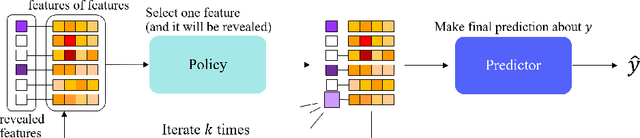
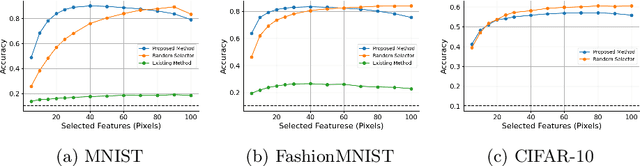
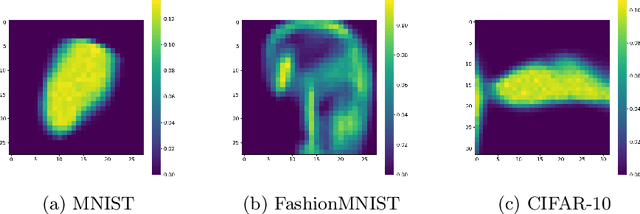
Machine learning models usually assume that a set of feature values used to obtain an output is fixed in advance. However, in many real-world problems, a cost is associated with measuring these features. To address the issue of reducing measurement costs, various methods have been proposed to dynamically select which features to measure, but existing methods assume that the set of measurable features remains constant, which makes them unsuitable for cases where the set of measurable features varies from instance to instance. To overcome this limitation, we define a new problem setting for Dynamic Feature Selection (DFS) with variable feature sets and propose a deep learning method that utilizes prior information about each feature, referred to as ''features of features''. Experimental results on several datasets demonstrate that the proposed method effectively selects features based on the prior information, even when the set of measurable features changes from instance to instance.
Exploring Causes and Mitigation of Hallucinations in Large Vision Language Models
Feb 24, 2025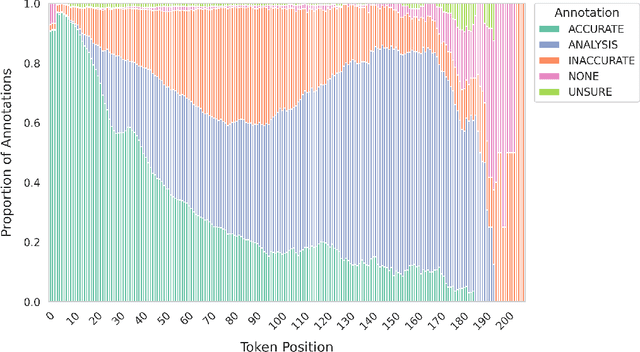
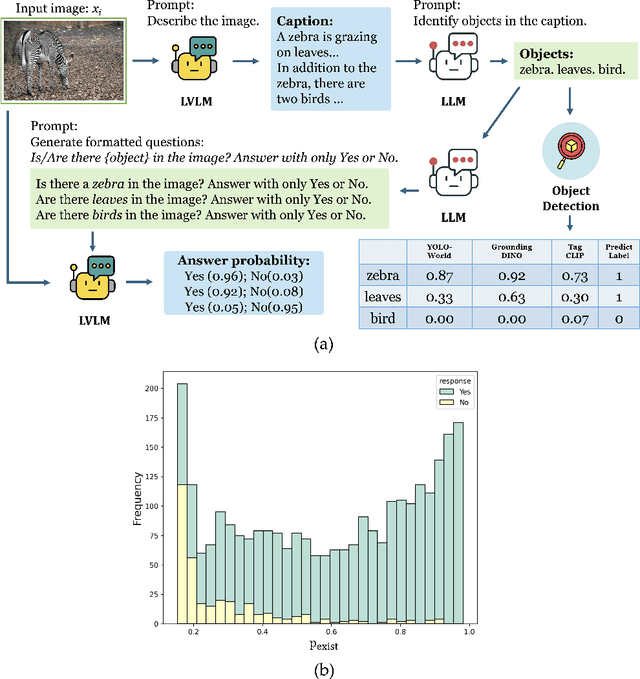
Large Vision-Language Models (LVLMs) integrate image encoders with Large Language Models (LLMs) to process multi-modal inputs and perform complex visual tasks. However, they often generate hallucinations by describing non-existent objects or attributes, compromising their reliability. This study analyzes hallucination patterns in image captioning, showing that not all tokens in the generation process are influenced by image input and that image dependency can serve as a useful signal for hallucination detection. To address this, we develop an automated pipeline to identify hallucinated objects and train a token-level classifier using hidden representations from parallel inference passes-with and without image input. Leveraging this classifier, we introduce a decoding strategy that effectively controls hallucination rates in image captioning at inference time.
Emulating Retrieval Augmented Generation via Prompt Engineering for Enhanced Long Context Comprehension in LLMs
Feb 18, 2025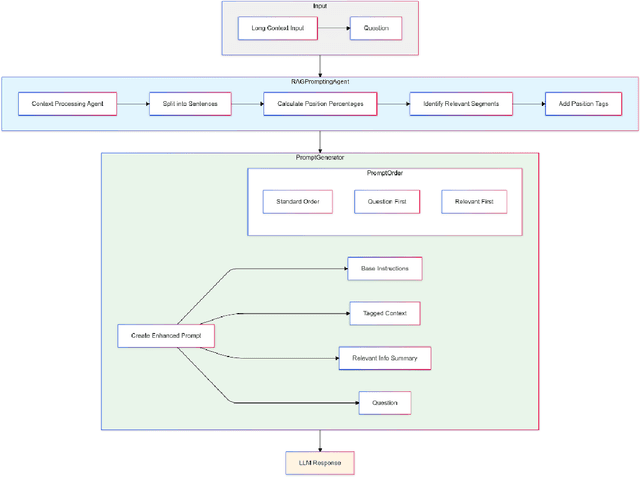


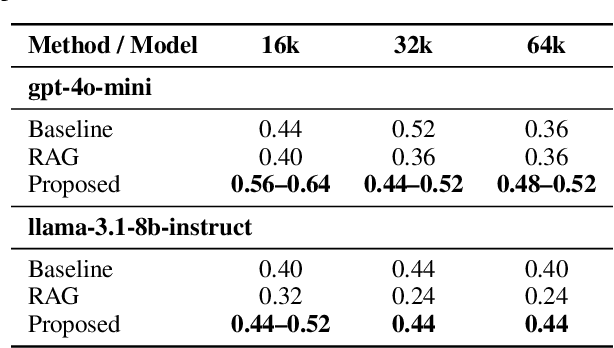
This paper addresses the challenge of comprehending very long contexts in Large Language Models (LLMs) by proposing a method that emulates Retrieval Augmented Generation (RAG) through specialized prompt engineering and chain-of-thought (CoT) reasoning. While recent LLMs support over 100,000 tokens in a single prompt, simply enlarging context windows has not guaranteed robust multi-hop reasoning when key details are scattered across massive input. Our approach treats the model as both the retriever and the reasoner: it first tags relevant segments within a long passage, then employs a stepwise CoT workflow to integrate these pieces of evidence. This single-pass method thereby reduces reliance on an external retriever, yet maintains focus on crucial segments. We evaluate our approach on selected tasks from BABILong, which interleaves standard bAbI QA problems with large amounts of distractor text. Compared to baseline (no retrieval) and naive RAG pipelines, our approach more accurately handles multi-fact questions such as object location tracking, counting, and indefinite knowledge. Furthermore, we analyze how prompt structure, including the order of question, relevant-text tags, and overall instructions, significantly affects performance. These findings underscore that optimized prompt engineering, combined with guided reasoning, can enhance LLMs' long-context comprehension and serve as a lightweight alternative to traditional retrieval pipelines.
Cognitive Biases in Large Language Models: A Survey and Mitigation Experiments
Nov 30, 2024

Large Language Models (LLMs) are trained on large corpora written by humans and demonstrate high performance on various tasks. However, as humans are susceptible to cognitive biases, which can result in irrational judgments, LLMs can also be influenced by these biases, leading to irrational decision-making. For example, changing the order of options in multiple-choice questions affects the performance of LLMs due to order bias. In our research, we first conducted an extensive survey of existing studies examining LLMs' cognitive biases and their mitigation. The mitigation techniques in LLMs have the disadvantage that they are limited in the type of biases they can apply or require lengthy inputs or outputs. We then examined the effectiveness of two mitigation methods for humans, SoPro and AwaRe, when applied to LLMs, inspired by studies in crowdsourcing. To test the effectiveness of these methods, we conducted experiments on GPT-3.5 and GPT-4 to evaluate the influence of six biases on the outputs before and after applying these methods. The results demonstrate that while SoPro has little effect, AwaRe enables LLMs to mitigate the effect of these biases and make more rational responses.
Learning Neural Strategy-Proof Matching Mechanism from Examples
Oct 25, 2024
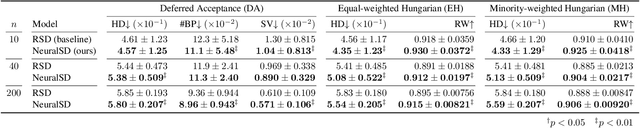


Designing effective two-sided matching mechanisms is a major problem in mechanism design, and the goodness of matching cannot always be formulated. The existing work addresses this issue by searching over a parameterized family of mechanisms with certain properties by learning to fit a human-crafted dataset containing examples of preference profiles and matching results. However, this approach does not consider a strategy-proof mechanism, implicitly assumes the number of agents to be a constant, and does not consider the public contextual information of the agents. In this paper, we propose a new parametric family of strategy-proof matching mechanisms by extending the serial dictatorship (SD). We develop a novel attention-based neural network called NeuralSD, which can learn a strategy-proof mechanism from a human-crafted dataset containing public contextual information. NeuralSD is constructed by tensor operations that make SD differentiable and learns a parameterized mechanism by estimating an order of SD from the contextual information. We conducted experiments to learn a strategy-proof matching from matching examples with different numbers of agents. We demonstrated that our method shows the superiority of learning with context-awareness over a baseline in terms of regression performance and other metrics.
Learning Fair and Preferable Allocations through Neural Network
Oct 23, 2024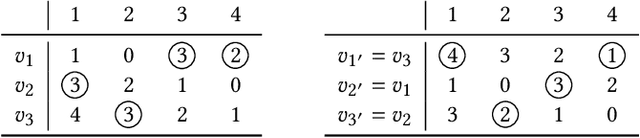



The fair allocation of indivisible resources is a fundamental problem. Existing research has developed various allocation mechanisms or algorithms to satisfy different fairness notions. For example, round robin (RR) was proposed to meet the fairness criterion known as envy-freeness up to one good (EF1). Expert algorithms without mathematical formulations are used in real-world resource allocation problems to find preferable outcomes for users. Therefore, we aim to design mechanisms that strictly satisfy good properties with replicating expert knowledge. However, this problem is challenging because such heuristic rules are often difficult to formalize mathematically, complicating their integration into theoretical frameworks. Additionally, formal algorithms struggle to find preferable outcomes, and directly replicating these implicit rules can result in unfair allocations because human decision-making can introduce biases. In this paper, we aim to learn implicit allocation mechanisms from examples while strictly satisfying fairness constraints, specifically focusing on learning EF1 allocation mechanisms through supervised learning on examples of reported valuations and corresponding allocation outcomes produced by implicit rules. To address this, we developed a neural RR (NRR), a novel neural network that parameterizes RR. NRR is built from a differentiable relaxation of RR and can be trained to learn the agent ordering used for RR. We conducted experiments to learn EF1 allocation mechanisms from examples, demonstrating that our method outperforms baselines in terms of the proximity of predicted allocations and other metrics.
AHP-Powered LLM Reasoning for Multi-Criteria Evaluation of Open-Ended Responses
Oct 02, 2024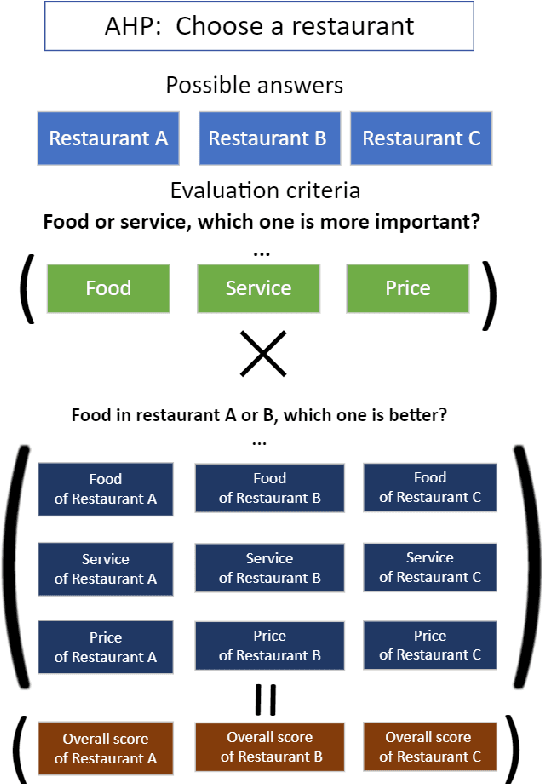



Question answering (QA) tasks have been extensively studied in the field of natural language processing (NLP). Answers to open-ended questions are highly diverse and difficult to quantify, and cannot be simply evaluated as correct or incorrect, unlike close-ended questions with definitive answers. While large language models (LLMs) have demonstrated strong capabilities across various tasks, they exhibit relatively weaker performance in evaluating answers to open-ended questions. In this study, we propose a method that leverages LLMs and the analytic hierarchy process (AHP) to assess answers to open-ended questions. We utilized LLMs to generate multiple evaluation criteria for a question. Subsequently, answers were subjected to pairwise comparisons under each criterion with LLMs, and scores for each answer were calculated in the AHP. We conducted experiments on four datasets using both ChatGPT-3.5-turbo and GPT-4. Our results indicate that our approach more closely aligns with human judgment compared to the four baselines. Additionally, we explored the impact of the number of criteria, variations in models, and differences in datasets on the results.