 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking the Implicit Norm Dynamics of Sharpness-Aware Minimization in Tensorized Models
Aug 14, 2025

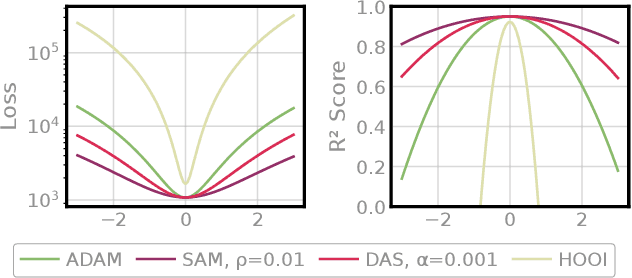

Sharpness-Aware Minimization (SAM) has been proven to be an effective optimization technique for improving generalization in overparameterized models. While prior works have explored the implicit regularization of SAM in simple two-core scale-invariant settings, its behavior in more general tensorized or scale-invariant models remains underexplored. In this work, we leverage scale-invariance to analyze the norm dynamics of SAM in general tensorized models. We introduce the notion of \emph{Norm Deviation} as a global measure of core norm imbalance, and derive its evolution under SAM using gradient flow analysis. We show that SAM's implicit control of Norm Deviation is governed by the covariance between core norms and their gradient magnitudes. Motivated by these findings, we propose a simple yet effective method, \emph{Deviation-Aware Scaling (DAS)}, which explicitly mimics this regularization behavior by scaling core norms in a data-adaptive manner. Our experiments across tensor completion, noisy training, model compression, and parameter-efficient fine-tuning confirm that DAS achieves competitive or improved performance over SAM, while offering reduced computational overhead.
Box-Constrained Softmax Function and Its Application for Post-Hoc Calibration
Jun 12, 2025Controlling the output probabilities of softmax-based models is a common problem in modern machine learning. Although the $\mathrm{Softmax}$ function provides soft control via its temperature parameter, it lacks the ability to enforce hard constraints, such as box constraints, on output probabilities, which can be critical in certain applications requiring reliable and trustworthy models. In this work, we propose the box-constrained softmax ($\mathrm{BCSoftmax}$) function, a novel generalization of the $\mathrm{Softmax}$ function that explicitly enforces lower and upper bounds on output probabilities. While $\mathrm{BCSoftmax}$ is formulated as the solution to a box-constrained optimization problem, we develop an exact and efficient computation algorithm for $\mathrm{BCSoftmax}$. As a key application, we introduce two post-hoc calibration methods based on $\mathrm{BCSoftmax}$. The proposed methods mitigate underconfidence and overconfidence in predictive models by learning the lower and upper bounds of the output probabilities or logits after model training, thereby enhancing reliability in downstream decision-making tasks. We demonstrate the effectiveness of our methods experimentally using the TinyImageNet, CIFAR-100, and 20NewsGroups datasets, achieving improvements in calibration metrics.
Exploring Causes and Mitigation of Hallucinations in Large Vision Language Models
Feb 24, 2025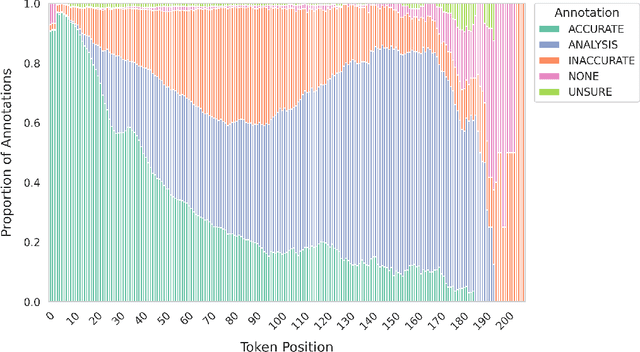
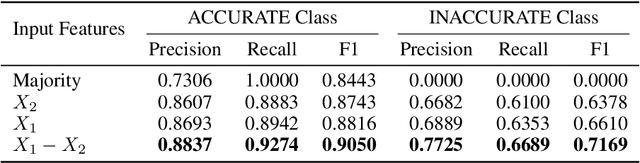
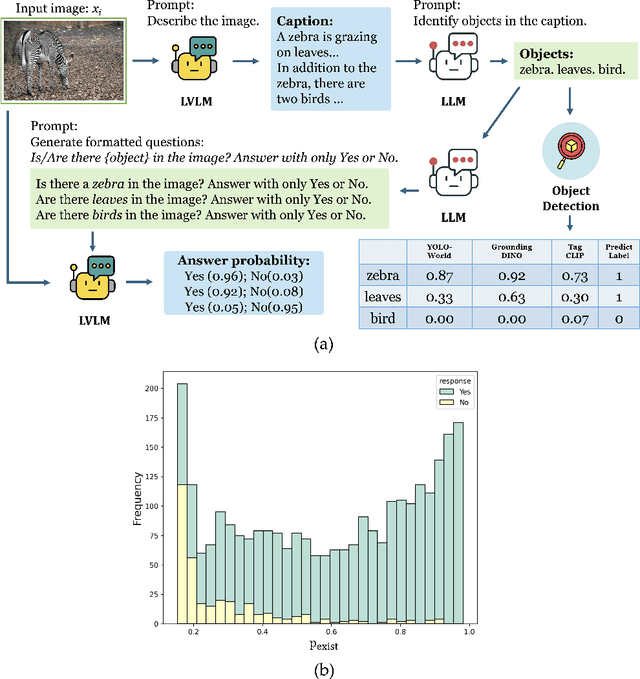
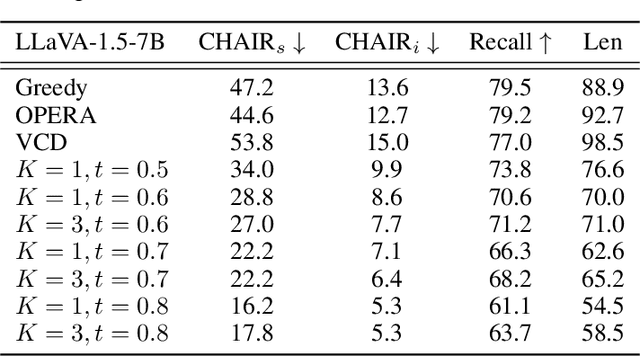
Large Vision-Language Models (LVLMs) integrate image encoders with Large Language Models (LLMs) to process multi-modal inputs and perform complex visual tasks. However, they often generate hallucinations by describing non-existent objects or attributes, compromising their reliability. This study analyzes hallucination patterns in image captioning, showing that not all tokens in the generation process are influenced by image input and that image dependency can serve as a useful signal for hallucination detection. To address this, we develop an automated pipeline to identify hallucinated objects and train a token-level classifier using hidden representations from parallel inference passes-with and without image input. Leveraging this classifier, we introduce a decoding strategy that effectively controls hallucination rates in image captioning at inference time.
Emulating Retrieval Augmented Generation via Prompt Engineering for Enhanced Long Context Comprehension in LLMs
Feb 18, 2025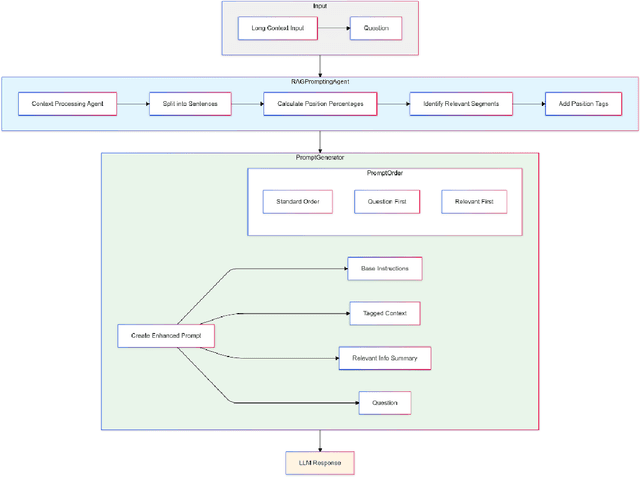


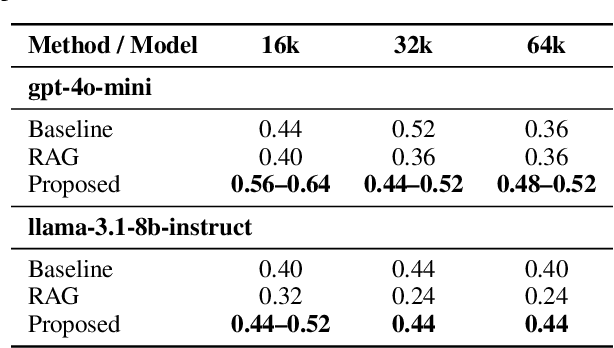
This paper addresses the challenge of comprehending very long contexts in Large Language Models (LLMs) by proposing a method that emulates Retrieval Augmented Generation (RAG) through specialized prompt engineering and chain-of-thought (CoT) reasoning. While recent LLMs support over 100,000 tokens in a single prompt, simply enlarging context windows has not guaranteed robust multi-hop reasoning when key details are scattered across massive input. Our approach treats the model as both the retriever and the reasoner: it first tags relevant segments within a long passage, then employs a stepwise CoT workflow to integrate these pieces of evidence. This single-pass method thereby reduces reliance on an external retriever, yet maintains focus on crucial segments. We evaluate our approach on selected tasks from BABILong, which interleaves standard bAbI QA problems with large amounts of distractor text. Compared to baseline (no retrieval) and naive RAG pipelines, our approach more accurately handles multi-fact questions such as object location tracking, counting, and indefinite knowledge. Furthermore, we analyze how prompt structure, including the order of question, relevant-text tags, and overall instructions, significantly affects performance. These findings underscore that optimized prompt engineering, combined with guided reasoning, can enhance LLMs' long-context comprehension and serve as a lightweight alternative to traditional retrieval pipelines.
Factorization Machines with Regularization for Sparse Feature Interactions
Oct 19, 2020



Factorization machines (FMs) are machine learning predictive models based on second-order feature interactions and FMs with sparse regularization are called sparse FMs. Such regularizations enable feature selection, which selects the most relevant features for accurate prediction, and therefore they can contribute to the improvement of the model accuracy and interpretability. However, because FMs use second-order feature interactions, the selection of features often cause the loss of many relevant feature interactions in the resultant models. In such cases, FMs with regularization specially designed for feature interaction selection trying to achieve interaction-level sparsity may be preferred instead of those just for feature selection trying to achieve feature-level sparsity. In this paper, we present a new regularization scheme for feature interaction selection in FMs. The proposed regularizer is an upper bound of the $\ell_1$ regularizer for the feature interaction matrix, which is computed from the parameter matrix of FMs. For feature interaction selection, our proposed regularizer makes the feature interaction matrix sparse without a restriction on sparsity patterns imposed by the existing methods. We also describe efficient proximal algorithms for the proposed FMs and present theoretical analyses of both existing and the new regularize. In addition, we will discuss how our ideas can be applied or extended to more accurate feature selection and other related models such as higher-order FMs and the all-subsets model. The analysis and experimental results on synthetic and real-world datasets show the effectiveness of the proposed methods.