 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of Games and their Solvers
May 28, 2026A central challenge in game theory and learning systems such as GANs is understanding which algorithms can efficiently compute equilibria across the heterogeneous landscape of games. Equilibrium computation is typically studied solver by solver and game class by game class, yielding strong local guarantees but a fragmented view of solver behaviour. Existing discrete taxonomies often provide an incomplete account of where algorithms succeed. We study this problem through a solver-game map linking games to effective solver dynamics. Classical theory identifies isolated regions of this map but provides limited insight into intermediate or overlapping regimes, suggesting that solvability is governed by latent structural properties defining a continuous solver-aligned geometry of games. We formalise this perspective through structure-aware solver synthesis. A learned structure recogniser maps each game to a low-dimensional solver-aligned representation, and a policy maps this representation to effective primitive mechanisms, adapting solver behaviour across regimes. This reveals regions where particular solver dynamics are effective and where mixtures of primitives are required rather than a single dominant solver. A bounded residual acts as a local corrector and diagnostic signal for incomplete solver bases or representations. The framework yields both an adaptive solver and an analytical lens: games with similar optimisation dynamics cluster together, revealing continuous regions of algorithmic validity and overlapping solver behaviour. Empirically, we show that fixed primitives exhibit systematic regime mismatch, while the learned representation organises game space into a structured cartography aligned with solver behaviour. These results suggest viewing equilibrium computation as the joint problem of learning solver mechanisms and mapping the geometry of solvability.
Exploring Causes and Mitigation of Hallucinations in Large Vision Language Models
Feb 24, 2025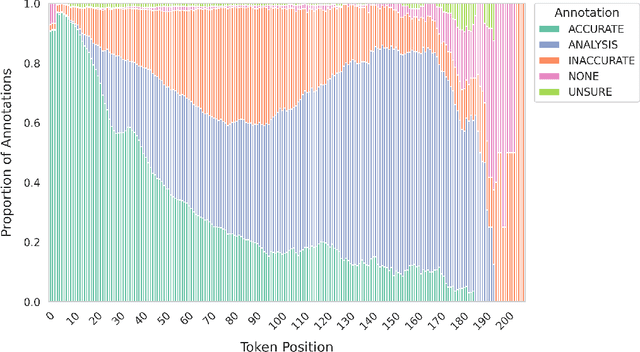
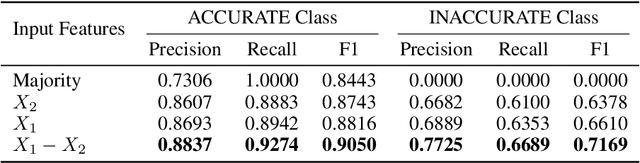
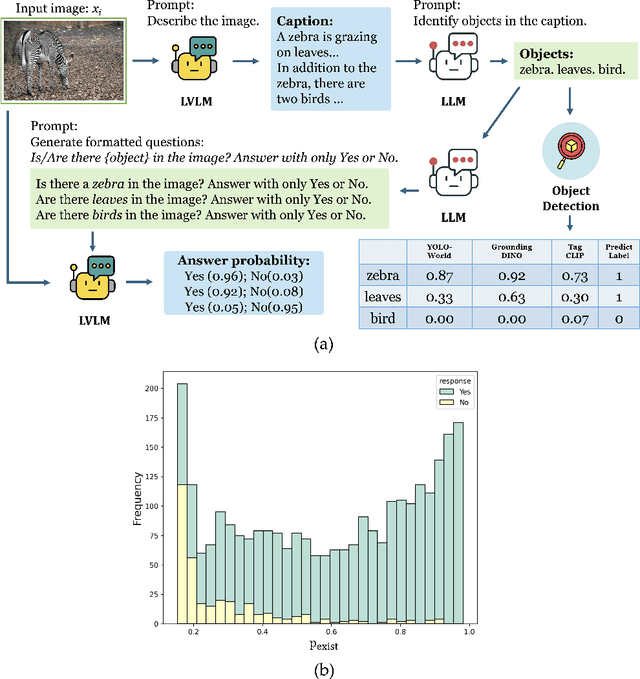
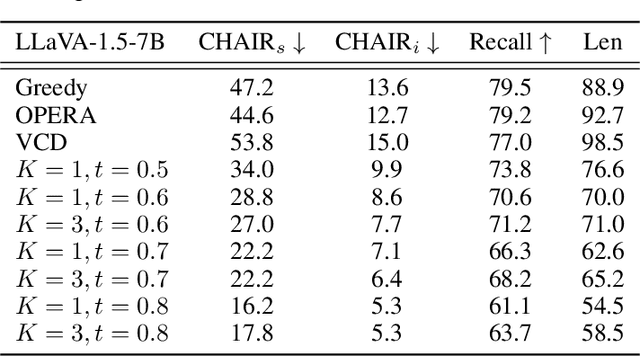
Large Vision-Language Models (LVLMs) integrate image encoders with Large Language Models (LLMs) to process multi-modal inputs and perform complex visual tasks. However, they often generate hallucinations by describing non-existent objects or attributes, compromising their reliability. This study analyzes hallucination patterns in image captioning, showing that not all tokens in the generation process are influenced by image input and that image dependency can serve as a useful signal for hallucination detection. To address this, we develop an automated pipeline to identify hallucinated objects and train a token-level classifier using hidden representations from parallel inference passes-with and without image input. Leveraging this classifier, we introduce a decoding strategy that effectively controls hallucination rates in image captioning at inference time.
HiBid: A Cross-Channel Constrained Bidding System with Budget Allocation by Hierarchical Offline Deep Reinforcement Learning
Dec 29, 2023



Online display advertising platforms service numerous advertisers by providing real-time bidding (RTB) for the scale of billions of ad requests every day. The bidding strategy handles ad requests cross multiple channels to maximize the number of clicks under the set financial constraints, i.e., total budget and cost-per-click (CPC), etc. Different from existing works mainly focusing on single channel bidding, we explicitly consider cross-channel constrained bidding with budget allocation. Specifically, we propose a hierarchical offline deep reinforcement learning (DRL) framework called ``HiBid'', consisted of a high-level planner equipped with auxiliary loss for non-competitive budget allocation, and a data augmentation enhanced low-level executor for adaptive bidding strategy in response to allocated budgets. Additionally, a CPC-guided action selection mechanism is introduced to satisfy the cross-channel CPC constraint. Through extensive experiments on both the large-scale log data and online A/B testing, we confirm that HiBid outperforms six baselines in terms of the number of clicks, CPC satisfactory ratio, and return-on-investment (ROI). We also deploy HiBid on Meituan advertising platform to already service tens of thousands of advertisers every day.
A Fair Federated Learning Framework With Reinforcement Learning
May 26, 2022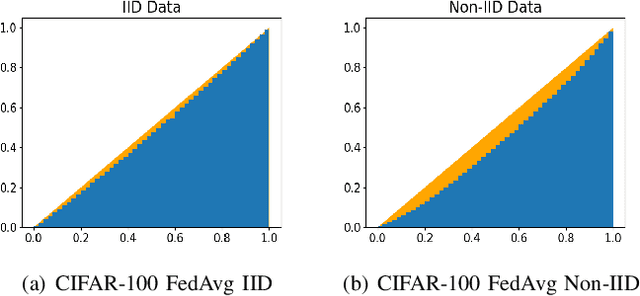
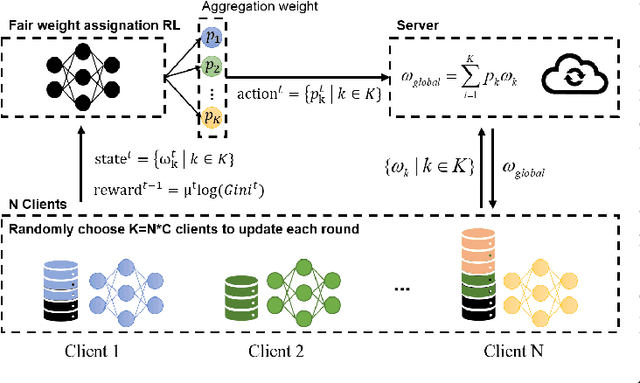
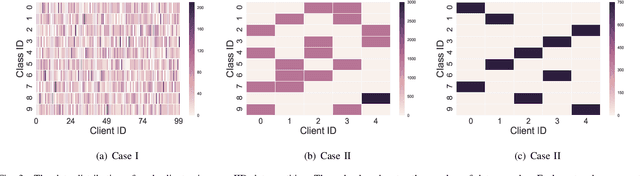
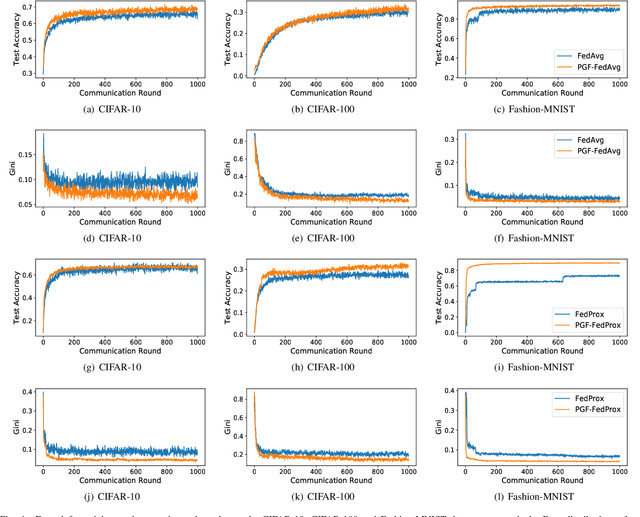
Federated learning (FL) is a paradigm where many clients collaboratively train a model under the coordination of a central server, while keeping the training data locally stored. However, heterogeneous data distributions over different clients remain a challenge to mainstream FL algorithms, which may cause slow convergence, overall performance degradation and unfairness of performance across clients. To address these problems, in this study we propose a reinforcement learning framework, called PG-FFL, which automatically learns a policy to assign aggregation weights to clients. Additionally, we propose to utilize Gini coefficient as the measure of fairness for FL. More importantly, we apply the Gini coefficient and validation accuracy of clients in each communication round to construct a reward function for the reinforcement learning. Our PG-FFL is also compatible to many existing FL algorithms. We conduct extensive experiments over diverse datasets to verify the effectiveness of our framework. The experimental results show that our framework can outperform baseline methods in terms of overall performance, fairness and convergence speed.